1. Bagging和Boosting的原理与区别
在讲解Boosting之前,必须提一下Bagging算法。两者作为机器学习中集成学习的主要算法,其思想是必须理解和掌握的。总的来说Bagging和Boosting都是将已有的分类或回归算法通过一定方式组合起来,形成一个性能更加强大的分类器,更准确的说这是一种分类或回归算法的组装方法,即将弱分类器组装成强分类器的方法。
Bagging:
Bagging指的是一种叫做 [Bootstrap Aggregating](自助聚合)的技术。其算法过程如下:
(1)从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
(2)每次使用一个训练集得到一个模型,k个训练集共得到k个模型。(注:这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
(3)对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。

上述过程可以这样考虑:我们假设有3 个分类器,它们生成一个分类结果,该结果可能是对的也可能是错的。我们绘制出 3 个分类器的结果,我们用红色表示分类结果错误的区域。一般总有多数分类器可以分类正确,本例中我们假设有2个总是对的。通过对分类器进行投票,你可以获得很高的分类准确率。

但Bagging 机制有时并不能很好地起作用,如上图所示,所有的分类器都会在同一个区域内获得错误的分类结果。由于Bagging机制是并行的,此时我们投票获得的结果总是错误的。出于此原因,对Boosting算法背后的直观想法就是:
(1)我们可否串行训练模型,而不是像Bagging一样并行训练
(2)每个模型通过重点关注之前的分类器表现不佳的地方进行下一步训练,是否能获得更好的结果
Boosting:
Boosting可以诠释为如下步骤(以分类任务来说明):
(1)先通过对N个训练数据的学习得到第一个弱分类器h1;
(2)将h1分错的数据和其他的新数据一起构成一个新的有N个训练数据的样本,通过对这个样本的学习得到第二个弱分类器h2;
(3)将h1和h2都分错了的数据加上其他的新数据构成另一个新的有N个训练数据的样本,通过对这个样本的学习得到第三个弱分类器h3;
(4)最终经过提升的强分类器h_final=Majority Vote(h1,h2,h3)。即某个数据被分为哪一类要通过h1,h2,h3的多数表决。
上述Boosting算法,存在两个问题:
①如何调整训练集,使得在训练集上训练弱分类器得以进行。
②如何将训练得到的各个弱分类器联合起来形成强分类器。
针对以上两个问题,AdaBoost算法进行了调整:
①使用加权后选取的训练数据代替随机选取的训练数据,这样将训练的焦点集中在比较难分的训练数据上。
②将弱分类器联合起来时,使用加权的投票机制代替平均投票机制。让分类效果好的弱分类器具有较大的权重,而分类效果差的分类器具有较小的权重。
2. 自适应boosting–Adaboost
综合上述讲解,Adaboost算法可以简单的描述为以下几个步骤:
算法描述
(1)首先,是初始化训练数据的权值分布D1。假设有N个训练样本数据,则每一个训练样本最开始时,都被赋予相同的权值:w1=1/N。
(2)然后,训练弱分类器hi。具体训练过程中是:如果某个训练样本点,被弱分类器hi准确地分类,那么在构造下一个训练集
中,它对应的权值要减小;相反,如果某个训练样本点被错误分类,那么它的权值就应该增大。权值更新过的样本集被用于训
练下一个分类器,整个训练过程如此迭代地进行下去。
(3)最后,将各个训练得到的弱分类器组合成一个强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器
的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起
着较小的决定作用。
数学推导
我们以二分类为例,简单讲述以下Adaboost算法的数学推导过程:
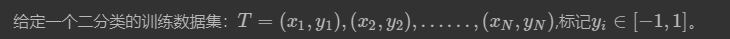
算法流程:(此部分引用自: pan_jinquan,Adaboost算法原理分析和实例+代码. 原文链接)



3. Adaboost算法代码实现
主要代码如下:(数据集采用的是Absenteeism_at_work.csv,为旷工时间的一个UCI的公共数据集)
import numpy as np
import math
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
"""读取训练集数据数据"""
with open('d:\Absenteeism_at_work.csv','r') as csvfile:
#reader = csv.reader(csvfile)
data = [line.strip('\n').split(',') for line in csvfile]
data = np.array(data)
#print(data)
X = [[float(raw[1]),float(raw[5])] for raw in data[1:]] #选取数据集中的第二行到结束,取出第二列,六列
y = [1 if raw[-7]=='1' else -1 for raw in data[1:]] #标签
X = np.array(X)
y = np.array(y)
'''Adaboost算法部分'''
def iteralo(T,X,y): # h代表学习函数,X代表训练集,et表示误差率
Dt = []
At=[]
Ht=[]
length = len(y)
for i in range(length):
Dt.append(1 / length) #初始化权值分布,最开始权值是相同的
for t in range(1,T): # 迭代T次
#进行预测运算,et表示误差率(误分类样本权值之和),at表示Ht的权重
clf = DecisionTreeClassifier(random_state=0) #基学习算法
clf.fit(X, y, Dt)
Ht.append(clf) #Ht代表每一轮所迭代出来的学习算法,是当前误差率最低的弱分类器作为第t个基本分类器
l = clf.predict(X)
et=0
for i in range(len(l)): #计算错误率
if l[i] != y[i]:
et += Dt[i] #计算误分类样本的权值之和
print("错误率:" + str(et))
if et >0.5:
break
at = 1/2 * math.log(((1-et)/et),math.e) # 计算弱分类器在最终分类器所占的权重at
At.append(at)
return At,Ht
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=2019) #划分训练集与测试集
At,Ht = iteralo(T = 20,X = X_train,y=y_train)
#print(np.shape(At),np.shape(Ht))
res = np.zeros(len(y_test))
for i in range(len(Ht)):
res += At[i]*Ht[i].predict_proba(X_test)[:,1] #进行加权整合
res = np.sign(res) #进行sign函数化
print(accuracy_score(y_test,res)) #打印准确度
注:代码来自于室友,一位精通前端、后端开发的研究僧
2019年3月8日 沙坡村职业技术学院