中心极限定律
中心极限定理:无论是多么复杂,多么乱的分布,甚至未知分布,取一定容量(个数)的样本,求样本均值(样本和),这样重复多次,得到的样本均值(样本和)都服从正态分布,尤其是当取值次数趋于无穷大时。
样本抽样
- 总体是你所研究的所有事件的集 合。
- 样本是从总体中选取的相对较小 的集合,可用于做出关于总体本身 的结论。
- 进行抽样时,首先定义目标总体, 即要研究的总体。然后确定抽样单 位,即要抽样的对象类型。最后, 拟定一个抽样空间,即目标总体中 的所有抽样单位的列表。
如果样本不能代表目标总体,则这 个样本存在偏倚。
抽样形式
- 简单随机抽样即随机选择抽样单位 并形成样本,包括重复抽样和不重复抽样。简单随机抽样的具体方式 包括抽签或棚随机编器。
- 分层抽样即将总体划分为几个组, 或者叫做几个层,组或层中的单位 都很相似,每一层都尽可能与其他 层不一样。分好层以后,就对每一 层执行简单随机抽样。
- 整群抽样即将总体划分为几个群, 其中每个群都尽置与其他群相似, 可通过简单随机柚样柚取几个群, 然后用这些群中的每一个柚样单位 形成样本。
- 系统抽样即选取一个数字k,然后 每到第k个抽样单位就抽样一次。
样本均值的抽样分布
总体分布非正态,但方差已知,这时当样本足够大时,其样本均值的分布为渐近正态分布。 接近正态分布的程度与样本n及其总体偏斜程度有关。样本n越大,接近得就越好或总体偏态越小
样本均值抽样的方差
样本均值抽样分布的方差等于原分布的方差除以样本容量,公式:
样本均值抽样的标准差
本均值抽样分布的标准差通常被称为均值标准差。公式:
置信区间
置信区间是指由样本统计量所构造的总体参数的估计区间。在统计学中,一个概率样本的置信区间(Confidence interval)是对这个样本的某个总体参数的区间估计。置信区间展现的是这个参数的真实值有一定概率落在测量结果的周围的程度,其给出的是被测量参数的测量值的可信程度,即前面所要求的“一个概率”。
计算步骤
置信区间是一种常用的区间估计方法,所谓置信区间就是分别以统计量的置信上限和置信下限为上下界构成的区间 。对于一组给定的样本数据,其平均值为μ,标准偏差为σ,则其整体数据的平均值的100(1-α)%置信区间为(μ-Ζα/2σ , μ+Ζα/2σ) ,其中α为非置信水平在正态分布内的覆盖面积 ,Ζα/2即为对应的标准分数。
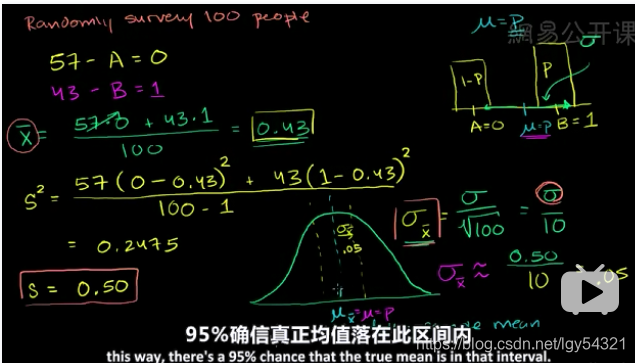
第一步:求一个样本的均值
第二步:计算出抽样误差。经过实践,通常认为调查:100个样本的抽样误差为±10%;500个样本的抽样误差为±5%;1200个样本时的抽样误差为±3%。
第三步:用第一步求出的“样本均值”加、减第二步计算的“抽样误差”,得出置信区间的两个端点 。
简便计算方法
C取决于置信水平

伯努利分布方差与均值
均值等于各期望乘以其概率 之和。方差等于 (各期望-均值 )平方乘以其概率 之和。
比如有成功(1)的为p,失败为1-p.
均值:
方差: