Why:
Internal Covariate Shift:网络中间层在训练过程中,输入数据分布的改变。训练过程中参数会不断的更新,前面层训练参数的更新将导致后面层输入数据分布的变化。
因此,模型参数要不断去适应这种随迭代变化的输入分布,这回导致模型参数学习很慢。如果能使每层的输入分布固定(如均值为0,方差为1的高斯分布),那么模型参数的学习将会更加容易。
What:
将每层输入的分布做归一化的操作,叫做Batch Normolization(批归一化)。
输入——>计算mini-batch的均值和方差——>归一化——>线性变换——>输出
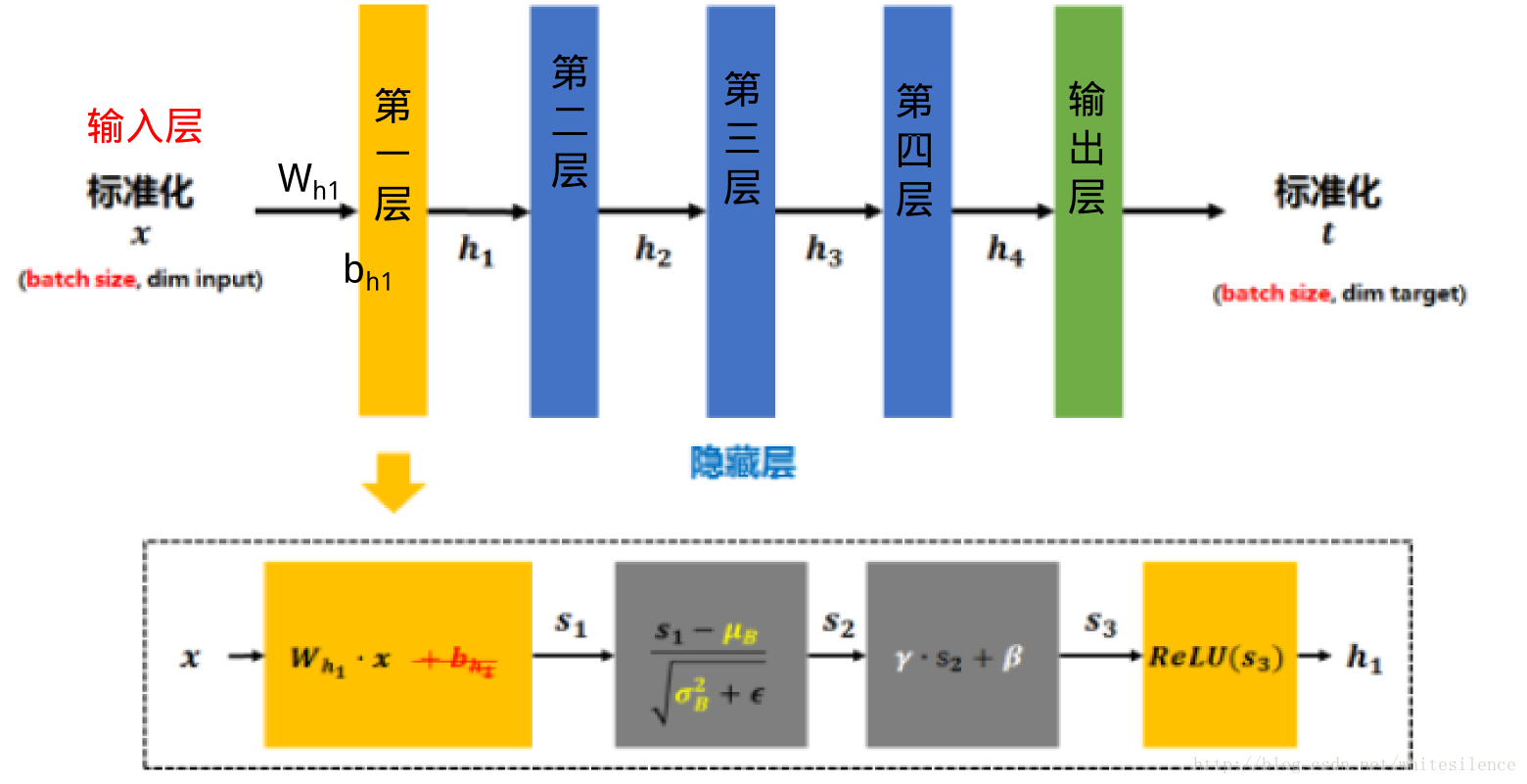
Results:
- 输入数据样本空间中的分布将更加均匀和固定,模型参数的学习也会变得更加容易,显著加速模型训练的收敛速度。
- 限制了在前层的参数的更新,减少了输入值改变的问题,使输出值更加稳定,因此有轻微的正则化的效果。
- 给隐藏层增加了噪音,有一定的正则化效果。
How:
卷积神经网络经过卷积后得到的是一系列的特征图,如果min-batch sizes为m,那么网络某一层输入数据可以表示为四维矩阵(m,f,p,q),m为min-batch sizes,f为特征图个数,p、q分别为特征图的宽高。在cnn中我们可以把每个特征图看成是一个特征处理(一个神经元),因此在使用Batch Normalization,mini-batch size 的大小就是:m*p*q,于是对于每个特征图都只有一对可学习参数:γ、β。说白了吧,这就是相当于求取所有样本所对应的一个特征图的所有神经元的平均值、方差,然后对这个特征图神经元做归一化。