1 特征数据的标准化
- 针对每一类型做标准化而不是整个数据
- 令数据统一跨度加速数据处理
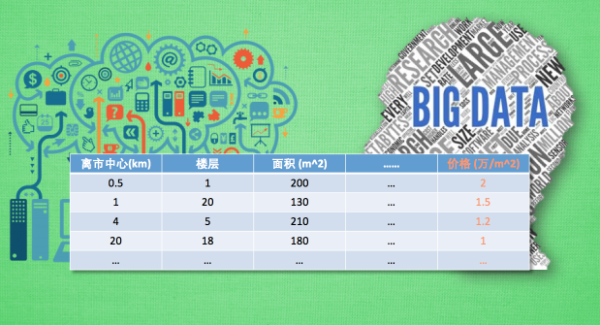
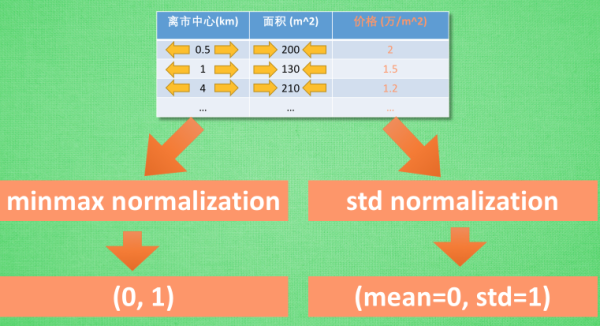
两种标准化的方法:
2 Batch Normalization
Batch Normalization(批标准化), 是将分散的数据统一的一种做法, 也是优化神经网络的一种方法.
2.1 WHY Batch Normalization
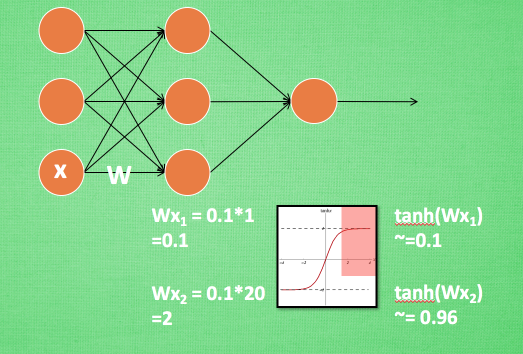
x 无论再怎么扩大, tanh 激励函数输出值也还是 接近1. 换句话说, 神经网络在初始阶段已经不对那些比较大的 x 特征范围 敏感。
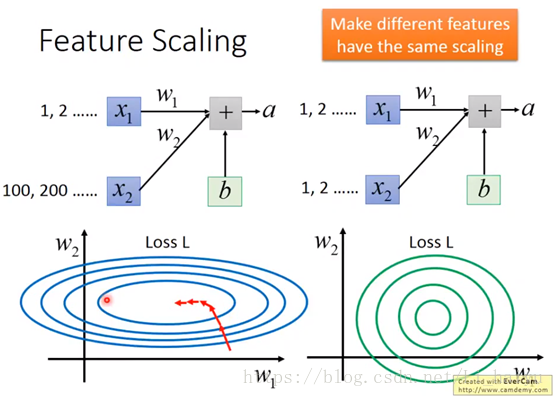
在没有进行Feature Scaling之前,如果两个输入数据x1,x2的distribution很不均匀的话,导致w2对计算结果的影响比较大(图左),所以训练的时候,横纵方向上需要给与一个不同的training rate,在w1方向需要一个更大的learning rate,w2方向给与一个较小的learning rate,不过这样做的办法却不见得很简单。所以对不同Feature做了normalization之后,使得error surface看起来比较接近正圆(图右),就可以使训练容易得多。
2.2 How to Batch Normalization
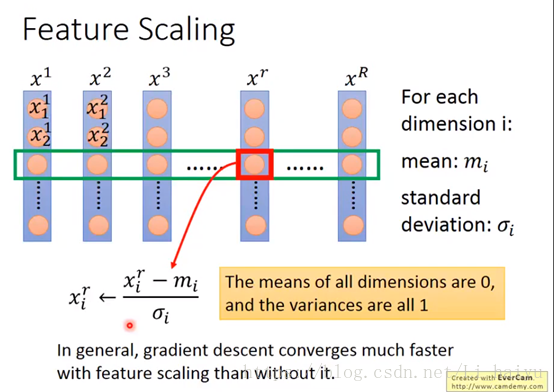
2.2.1 Feature Scaling
下面一共有R个data,分别计算每个维度的平均值,标准差,然后再使用图片那个简单的公式进行一下normalization,就可以把所有维度的平均值变为0,方差变为1了。一般来说,进行Feature Scaling之后可以使梯度下降算法更快收敛。
2.2.2 Internal Covariate Shift
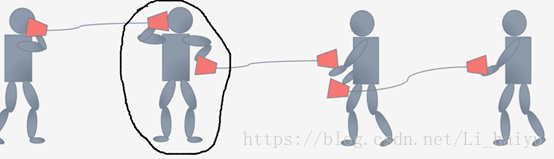
对每一个layer的输入进行Feature Scaling,其实这样对deep learning的训练是很有帮助的,因为它让Internal Covariate Shift下降,那么Internal Covariate Shift是个什么问题呢,可以按照下图来理解,每个小人手上都有一个话筒只有他们将两个话筒对接在一块才能很好地像后面传递信息。
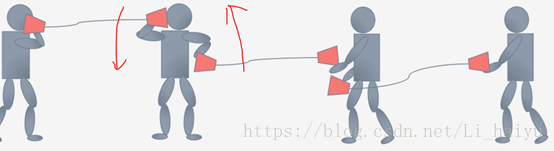
现在我们看一下中间那个小人在训练的时候为了将两个话筒拉到同一个水平高度,它会将左手边的话筒放低一点,同时右手的话筒放低一点,因为是同时两边都变,所以就可能出现了下面的图。
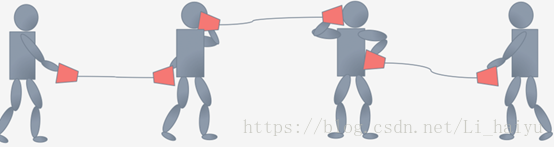
在过去的解决方法是调小learning rate,因为没对上就是因为学习率太大导致的,虽然体调小learning rate可以很好地解决这个问题,但是又会导致训练速度变得很慢。
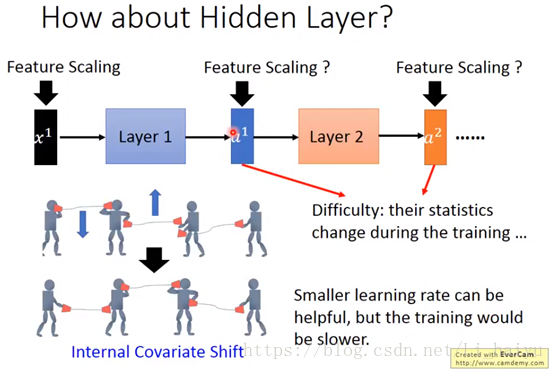
2.2.3 How to Batch Normalization
那么把刚才的话筒转化为deep learning中就是说,训练过程参数在调整的时候前一个层是后一个层的输入,当前一个层的参数改变之后也会改变后一层的参数。当后面的参数按照前面的参数学好了之后前面的layer就变了。
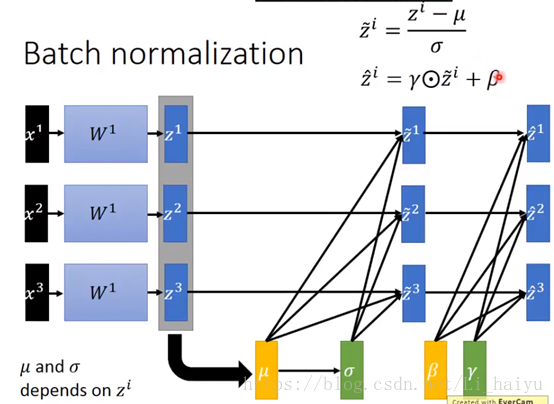
其实输入数据很好normalization,因为输入数据是固定下来的,但是后面层的参数在不断变化根本就不能那么容易算出mean和variance,所以需要一个新的技术叫Batch normalization。
Train
- 对每层进行Batch Normalization的时候一般都是先进行normalization再传进
active function的,优点是可以让输入更多地落在active function (比如sigmoid和tanh)的微分比较大的地方也就是零附近。 - 先对一层的输出求平均值 和方差 ,然后normalization,可以得到每个维度的平均值为零,方差为1。
- 修正操作:将 normalize 后的数据再扩展和平移。 原来这是为了让神经网络自己去学着使用和修改这个扩展参数 , 和 平移参数 , 这样神经网络就能自己慢慢琢磨出前面的 normalization 操作到底有没有起到优化的作用, 如果没有起到作用, 我就使用 和 来抵消一些 normalization 的操作。
- 网络的反向传播:反向传播回来的时候是会通过
然后通过
然后去更新
。在BP过程中需要考虑
和
,因为
和
依赖于Z,改动了Z就相当于改动了
和
。
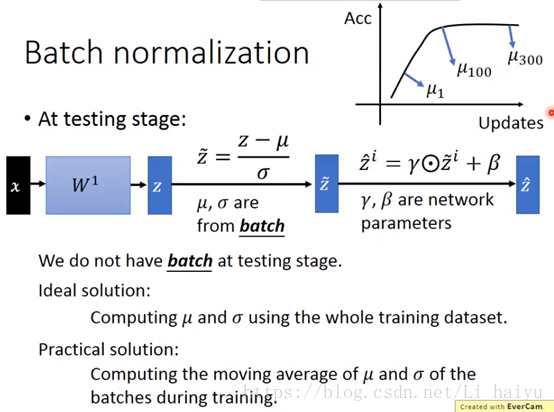
Test
Testing的时候只有一笔data输入到网络中,不能估计出 和 ,这里提供两个思路估算testing时候的 和 :
- Ideal Solution:直接在整个training dataset上计算 和 ,但实际中由于training dataset太大或者training dataset没有留下来,一般不采用这个方法。
- Practical Solution:把过去所有Batch的
和
都算出来,例如途中
2.3 Benefit

- Less Covariate Shift, 用更大的学习率
- 避免梯度消失
- 学习过程中被数据初始化影响较小
- 降低正则化的要求(有时候能够取代Dropout)
2.4 BN 算法
