MapReduce需要确保每个reducer的输入都是按键(key)排序的,而系统执行排序,将map输出作为输入传给reducer的过程就是shuffle。
但是在某些描述上面,它只代表reduce任务获取map输出的这个部分。
而shuffle是mapReduce的核心,主要工作是从Map结束阶段到Reduce阶段,可以分为Map端的Shuffle和Reduce端的Shuffle。
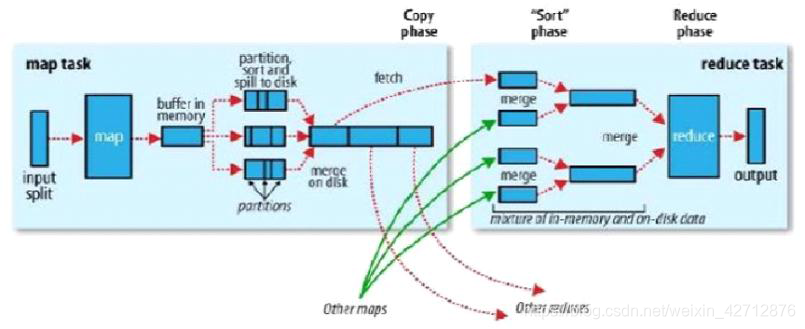
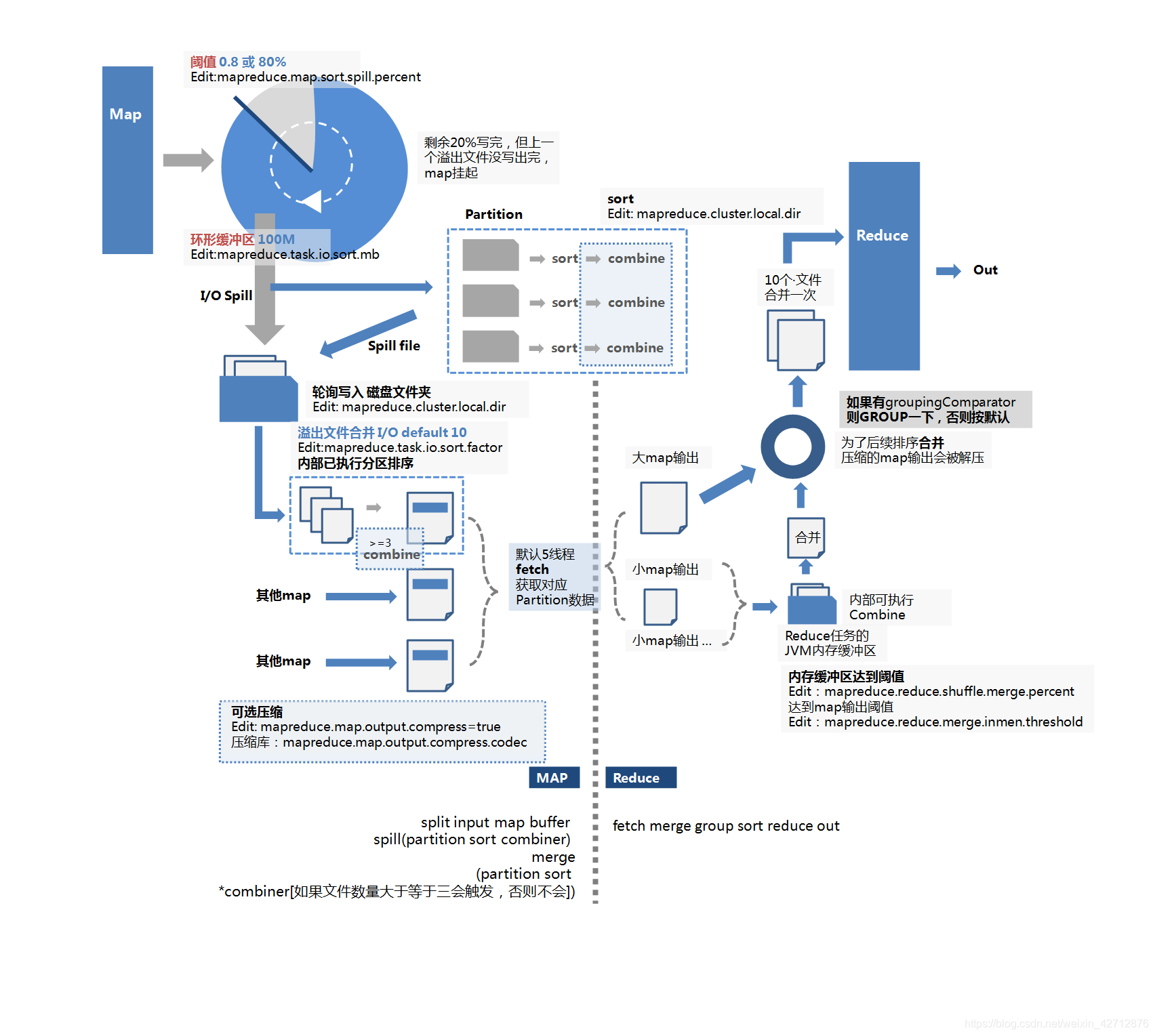
1 Map端的shuffle
—split input map buffer spill(partition sort combiner) merge(partition sort *combiner[如果文件数量大于等于三会触发,否则不会])
系统根据文件情况Split 数据,经过逻辑划分后,input进入指定的map,map将数据解析后,会放入环形缓冲区,当缓冲区容量达到阈值时,就会将文件通过IO流溢写到磁盘中形成一个溢出文件。
但是在数据写到磁盘前,线程会根据最终要传的reducer把数据划分成相应的分区,在每个分区中,按键在内存中进行排序,如果有combiner,它就在排序的输出上运行。
在map任务完成前,溢出文件会被合并成一个已经分区排序的文件。如果存在至少3个溢出文件,combiner会在写到磁盘之前进行合并。其中,可选压缩。
2 Reduce端的shuffle
—fetch merge group sort reduce out
当一个map完成后,reduce会根据分区信息主动fetch获取文件,并复制到磁盘,随着磁盘副本增多,后台线程会将它们合并成为更大的,排好序的文件。若前期map阶段进行了压缩,本阶段将会进行解压。
复制完所有map输出后,进行分组(默认按key分组,如果有groupingComparator,则按自定义分组器分组),然后reduce会进入排序阶段,将合并map后输出,维持其顺序排序,将中间文件以组为单位,输入reduce函数,每趟的合并文件数量可能不同,目的是合并最小数量的文件以满足最后一趟的合并系数。最终合成一个文件。
画了很久的解剖图 ε≡٩(๑>₃<)۶
完