版权声明:本博客都是作者10多年工作总结 https://blog.csdn.net/Peter_Changyb/article/details/82658958
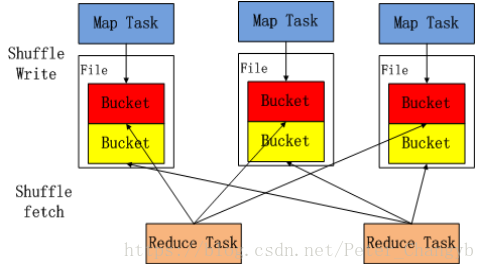
shuffle 中Map任务产生的结果会根据所设置的partitioner算法填充到当前执行任务所在机器的每个桶中。
- Reduce任务启动时时,会根据任务的ID,所依赖的Map任务ID以及MapStatus从远端或本地的BlockManager获取相应的数据作为输入进行处理。
- Shuffle数据必须持久化磁盘,不能缓存在内存。
Hash方式:
- shuffle不排序,效率高。
- 生成MXR个shuffle中间文件,一个分片一个文件。
- 产生和生成这些中间文件会产生大量的随机IO,磁盘效率低。
- shuffle时需要全部数据都放在内存,对内存消耗大。
- 适合数据量能全部放到内存,reduce操作不需要排序的场景。

Sort方式:
- shuffle需要排序。
- 生成M个shuffle中间数据文件,一个Map所有分片放到一个数据文件中,外加一个索引文件记录每个分片在数据文件中的偏移量。
- shuffle能够借助磁盘(外部排序)处理庞大的数据集。
- 数据量大于内存时只能使用Sort方式,也适用于Reduce操作需要排序的场景。