Shuffle简介
Shuffle的本意是洗牌、混洗的意思,把一组有规则的数据尽量打乱成无规则的数据。而在MapReduce中,Shuffle更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便reduce端接收处理。其在MapReduce中所处的工作阶段是map输出后到reduce接收前,具体可以分为map端和reduce端前后两个部分。
在Shuffle之前,也就是在map阶段,MapReduce会对要处理的数据进行分片(split)操作,为每一个分片分配一个MapTask任务。接下来map会对每一个分片中的每一行数据进行处理得到键值对(key,value)此时得到的键值对又叫做“中间结果”。此后便进入reduce阶段,由此可以看出Shuffle阶段的作用是处理“中间结果”。
由于Shuffle涉及到了磁盘的读写和网络的传输,因此Shuffle性能的高低直接影响到了整个程序的运行效率。
MapReduce Shuffle
Hadoop的核心思想是MapReduce,但Shuffle又是MapReduce的核心。Shuffle的主要工作是从Map结束到Reduce开始之间的过程。Shuffle阶段又可以分为Map端的Shuffle和Reduce端的Shuffle。
Map端的Shuffle
下图是MapReduce Shuffle的官方流程:
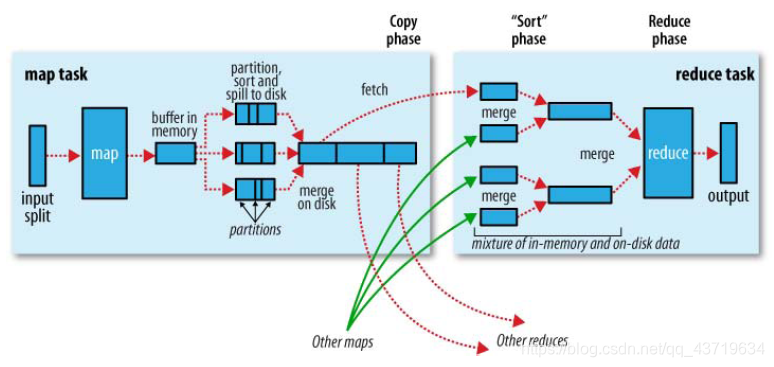
因为频繁的磁盘I/O操作会严重的降低效率,因此“中间结果”不会立马写入磁盘,而是优先存储到map节点的“环形内存缓冲区”,在写入的过程中进行分区(partition),也就是对于每个键值对来说,都增加了一个partition属性值,然后连同键值对一起序列化成字节数组写入到缓冲区(缓冲区采用的就是字节数组,默认大小为100M)。
当写入的数据量达到预先设置的阙值后便会启动溢写出线程将缓冲区中的那部分数据溢出写(spill)到磁盘的临时文件中,并在写入前根据key进行排序(sort)和合并(combine,可选操作)。
溢出写过程按轮询方式将缓冲区中的内容写到mapreduce.cluster.local.dir属性指定的本地目录中。当整个map任务完成溢出写后,会对磁盘中这个map任务产生的所有临时文件(spill文件)进行归并(merge)操作生成最终的正式输出文件,此时的归并是将所有spill文件中的相同partition合并到一起,并对各个partition中的数据再进行一次排序(sort),生成key和对应的value-list,文件归并时,如果溢写文件数量超过参数min.num.spills.for.combine的值(默认为3)时,可以再次进行合并。
至此map端的工作已经全部结束,最终生成的文件也会存储在TaskTracker能够访问的位置。每个reduce task不间断的通过RPC从JobTracker那里获取map task是否完成的信息,如果得到的信息是map task已经完成,那么Shuffle的后半段开始启动。
Reduce端的shuffle
当mapreduce任务提交后,reduce task就不断通过RPC从JobTracker那里获取map task是否完成的信息,如果获知某台TaskTracker上的map task执行完成,Shuffle的后半段过程就开始启动。Reduce端的shuffle主要包括三个阶段,copy、merge和reduce。
每个reduce task负责处理一个分区的文件,以下是reduce task的处理流程:
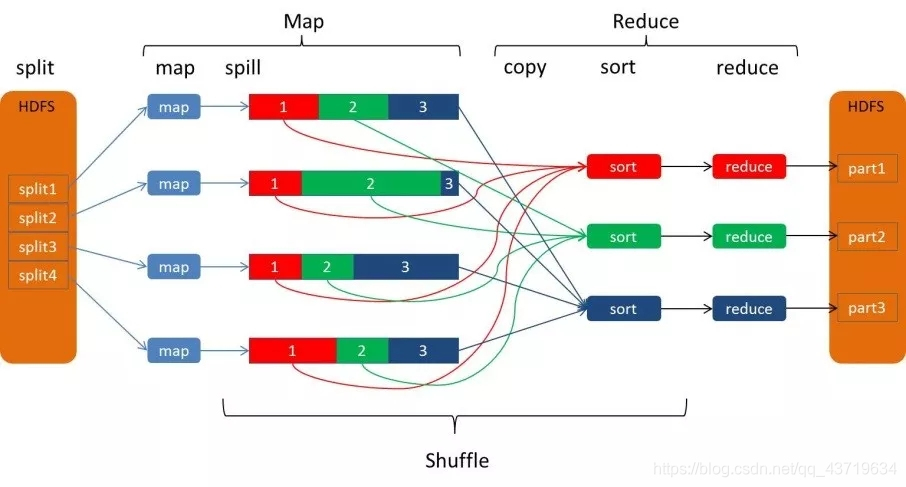 reduce task从每个map task的结果文件中拉取对应分区的数据。因为数据在map阶段已经是分好区了,并且会有一个额外的索引文件记录每个分区的起始偏移量。所以reduce task取数的时候直接根据偏移量去拉取数据就ok。
reduce task从每个map task的结果文件中拉取对应分区的数据。因为数据在map阶段已经是分好区了,并且会有一个额外的索引文件记录每个分区的起始偏移量。所以reduce task取数的时候直接根据偏移量去拉取数据就ok。
reduce task从每个map task拉取分区数据的时候会进行再次合并,排序,按照自定义的reducer的逻辑代码去处理。
最后就是Reduce过程了,在这个过程中产生了最终的输出结果,并将其写到HDFS上。
为什么要排序?
key存在combine操作,排序之后相同的key放到一块显然方便做合并操作。
reduce task是按key去处理数据的。 如果没有排序那必须从所有数据中把当前相同key的所有value数据拿出来,然后进行reduce逻辑处理。显然每个key到这个逻辑都需要做一次全量数据扫描,影响性能,有了排序很方便的得到一个key对于的value集合。
reduce task按key去处理数据时,如果key按顺序排序,那么reduce task就按key顺序去读取,显然当读到的key是文件末尾的key那么就标志数据处理完毕。如果没有排序那还得有其他逻辑来记录哪些key处理完了,哪些key没有处理完。
虽有千万种理由需要这么做,但是很耗资源,并且像排序其实我们有些业务并不需要排序。
为什么要文件合并?
因为内存放不下就会溢写文件,就会发生多次溢写,形成很多小文件,如果不合并,显然会小文件泛滥,集群需要资源开销去管理这些小文件数据。
任务去读取文件的数增多,打开的文件句柄数也会增多。
mapreduce是全局有序。单个文件有序,不代表全局有序,只有把小文件合并一起排序才会全局有序。
