版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/85271871
1 Spark 集群模式
local: spark-shell --master local,默认的standlone
1.复制 spark 目录到其他主机
2.配置其他主机的环境变量
3.配置 master 节点的 slaves 文件
4.启动 spark集群,start-all.sh
5.WebUI: 8080
YARN模式mesos模式
2 Spark集群完全分布式 standlone
spark-env.sh
export JAVA_HOME=/usr/apps/jdk1.8.0_181-amd64
export SCALA_HOME=/home/hadoop/apps/scala-2.11.12
SPARK_MASTER_HOST=node1
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1g
SPARK_WORKER_INSTANCES=1
slaves
node1
node2
node3
- 启动
[hadoop@node1 spark-2.2.2-bin-2.6.0-cdh5.7.0]$ ./sbin/start-all.sh
浏览器访问 http://node1:8080/
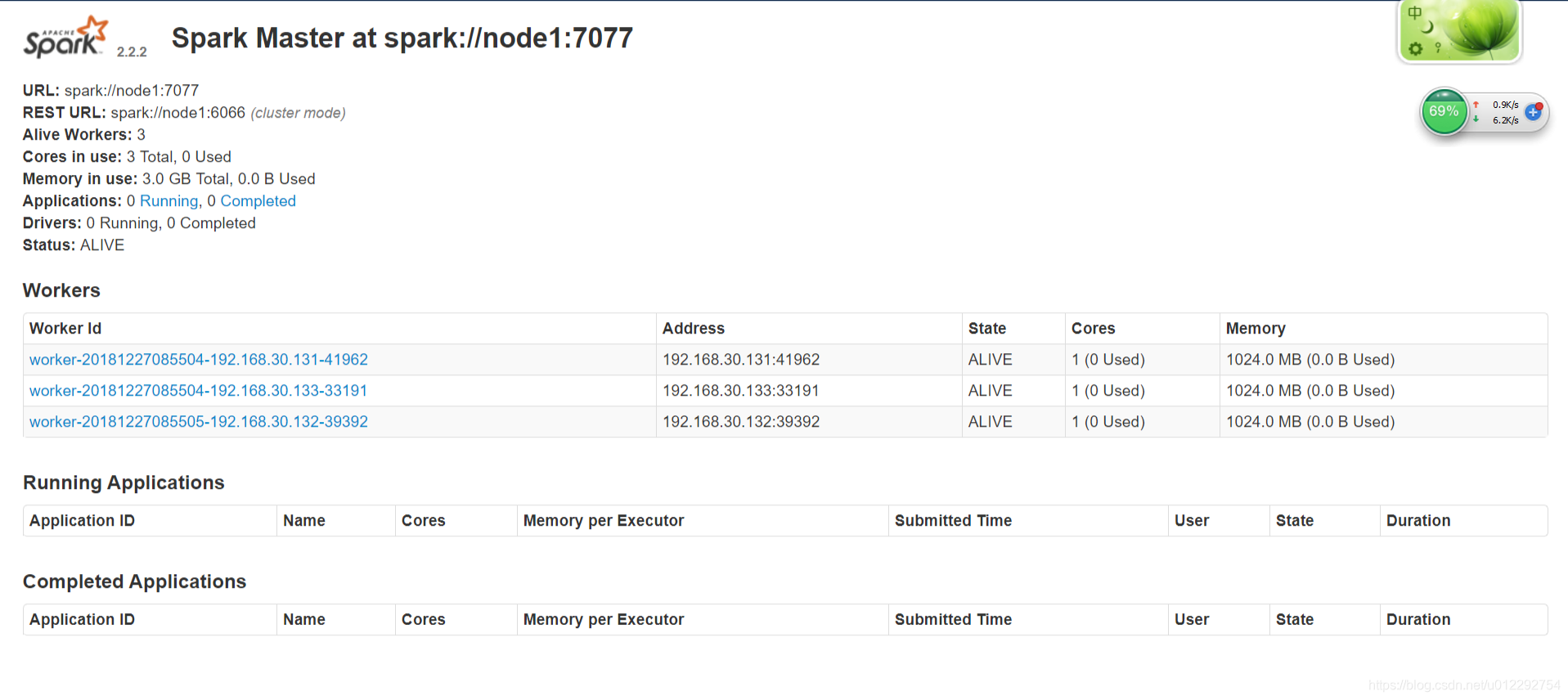
2.1 start-all.sh 脚本分析
sbin/spark-config.shsbin/spark-master.shsbin/spark-slaves.sh