版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/85301039
1 RDD的转换
1.1 groupByKey
- (k,v) => (k,Iterable)
package com.bigdataSpark.cn
import org.apache.spark.{SparkConf, SparkContext}
object GroupByKeyDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("GroupByKeyDemo")
conf.setMaster("local[2]")
val sc = new SparkContext(conf)
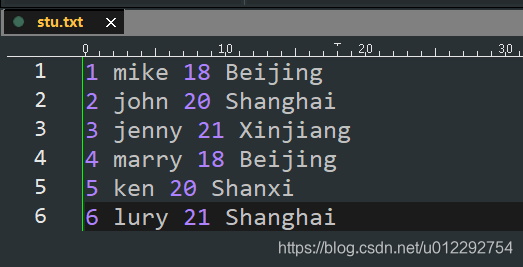
val rdd1 = sc.textFile("d:/stu.txt")
val rdd2 = rdd1.map(line => {
val key = line.split(" ")(3)
(key, line)
})
val rdd3 = rdd2.groupByKey()
rdd3.collect().foreach(t => {
val key = t._1
println(key + " :==========")
for (e <- t._2) {
println(e)
}
})
}
}


1.2 aggregateByKey
1.3 sortByKey
1.4 join
- (k,v).join(k,w) => (k,(v,w))
package com.bigdataSpark.cn
import org.apache.spark.{SparkConf, SparkContext}
object JoinDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("GroupByKeyDemo").setMaster("local[4]")
val sc = new SparkContext(conf)
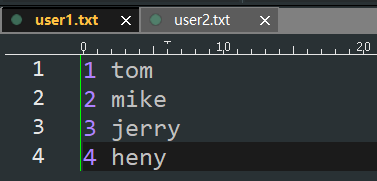
val nameRDD1 = sc.textFile("d:/user1.txt")
val nameRDD2 = nameRDD1.map(line => {
val arr = line.split(" ")
(arr(0).toInt, arr(1))
})
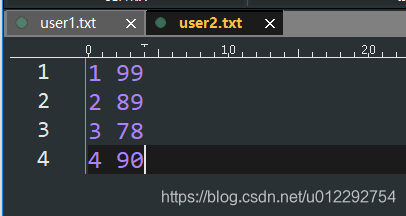
val scoreRDD1 = sc.textFile("d:/user2.txt")
val scoreRDD2 =scoreRDD1.map(line => {
val arr = line.split(" ")
(arr(0).toInt, arr(1).toInt)
})
val rdd = nameRDD2.join(scoreRDD2)
rdd.collect().foreach(t => {
println(t._1 + ":" + t._2)
})
}
}

1.5 cogroup 协分组
- (k,v).cogroup(k,w) => (k,(Iterable,Iterable))
1.6 笛卡尔积 cartesian
- RR[T] RDD[U] => RDD[(T,U)]
package com.bigdataSpark.cn
import org.apache.spark.{SparkConf, SparkContext}
object CartesianDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("cartesianDemo")
val sc = new SparkContext(conf)
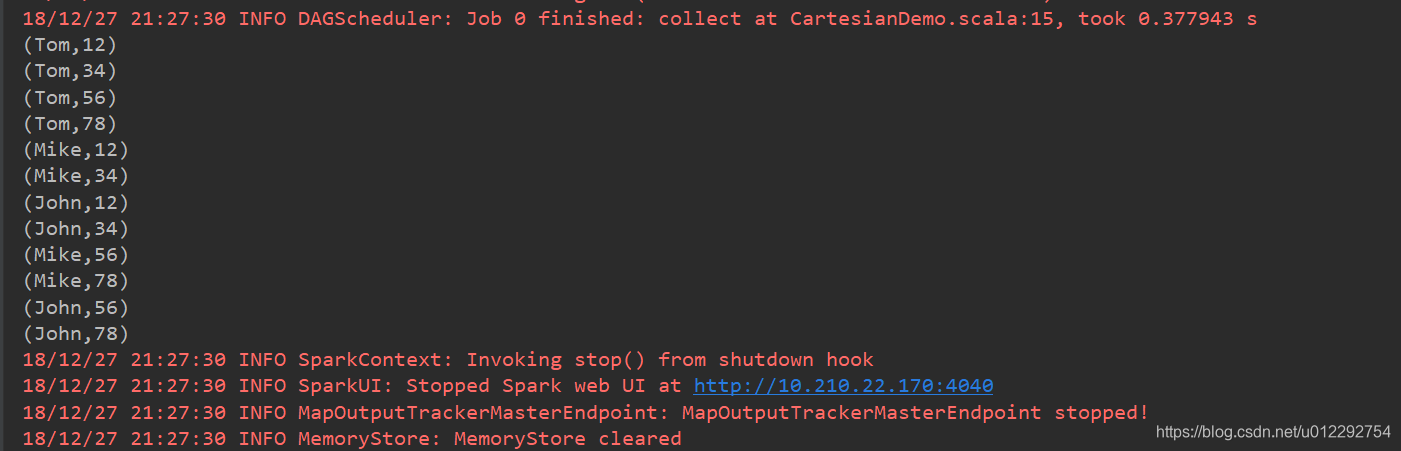
val rdd1 = sc.parallelize(Array("Tom", "Mike", "John"))
val rdd2 = sc.parallelize(Array("12", "34", "56", "78"))
val rdd = rdd1.cartesian(rdd2)
rdd.collect().foreach(t => {
println(t)
})
}
}
1.7 pipe

1.8 coalesce
- 降低 RDD 的分区