版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/85330431
1 Spark SQL
- 编程方式:(1)SQL;(2) DataFrame API
scala> case class Customer(id:Int,name:String,age:Int)
defined class Customer
scala> val arr = Array("1,Mike,20","2,Mary,19","3,Jerry,23")
arr: Array[String] = Array(1,Mike,20, 2,Mary,19, 3,Jerry,23)
scala> val rdd1 = sc.parallelize(arr)
rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[1] at parallelize at <console>:26
scala> rdd1.collect
res1: Array[String] = Array(1,Mike,20, 2,Mary,19, 3,Jerry,23)
scala> :paste
// Entering paste mode (ctrl-D to finish)
rdd1.map(e=>{
val arr = e.split(",")
Customer(arr(0).toInt,arr(1),arr(2).toInt)
})
// Exiting paste mode, now interpreting.
res2: org.apache.spark.rdd.RDD[Customer] = MapPartitionsRDD[2] at map at <console>:31
scala> val rdd2 = res2
rdd2: org.apache.spark.rdd.RDD[Customer] = MapPartitionsRDD[2] at map at <console>:31
scala> rdd2.collect
res3: Array[Customer] = Array(Customer(1,Mike,20), Customer(2,Mary,19), Customer(3,Jerry,23))
scala> val df = spark.createDataFrame(rdd2)
18/12/28 18:38:10 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
df: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> df.printSchema
root
|-- id: integer (nullable = false)
|-- name: string (nullable = true)
|-- age: integer (nullable = false)
scala> df.show
+---+-----+---+
| id| name|age|
+---+-----+---+
| 1| Mike| 20|
| 2| Mary| 19|
| 3|Jerry| 23|
+---+-----+---+
scala> df.createTempView("customer")
scala> val df2 = spark.sql("select * from customer")
df2: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> df2.show
+---+-----+---+
| id| name|age|
+---+-----+---+
| 1| Mike| 20|
| 2| Mary| 19|
| 3|Jerry| 23|
+---+-----+---+
scala> val df2 = spark.sql("select * from customer where id <2")
df2: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> df2.show
+---+----+---+
| id|name|age|
+---+----+---+
| 1|Mike| 20|
+---+----+---+
scala> val df1 = spark.sql("select * from customer where id < 2")
df1: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> df1.show
+---+----+---+
| id|name|age|
+---+----+---+
| 1|Mike| 20|
+---+----+---+
scala> val df2 = spark.sql("select * from customer where id > 2")
df2: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> df2.show
+---+-----+---+
| id| name|age|
+---+-----+---+
| 3|Jerry| 23|
+---+-----+---+
// union => 纵向连接
scala> val dff = spark.sql("select * from c1 union select * from c2")
dff: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> dff.show
+---+-----+---+
| id| name|age|
+---+-----+---+
| 3|Jerry| 23|
| 1| Mike| 20|
+---+-----+---+
2 Spark SQL 读取 json 文件
Dataset<Row> === DataFrame,类似于table的操作SparkSession.read().json()SparkSession.write().json()
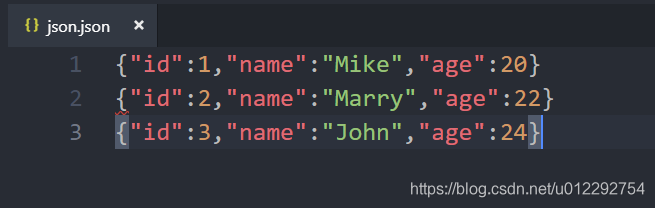
2.1 Spark SQL Java 版本
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class SQLJava {
public static void main(String[] args) {
SparkSession session = SparkSession.builder()
.appName("SQLJava")
.config("spark.master", "local[2]")
.getOrCreate();
Dataset<Row> df = session.read().json("d:/json.json");
df.createOrReplaceTempView("stu");
df = session.sql("select * from stu");
df.show();
}
}
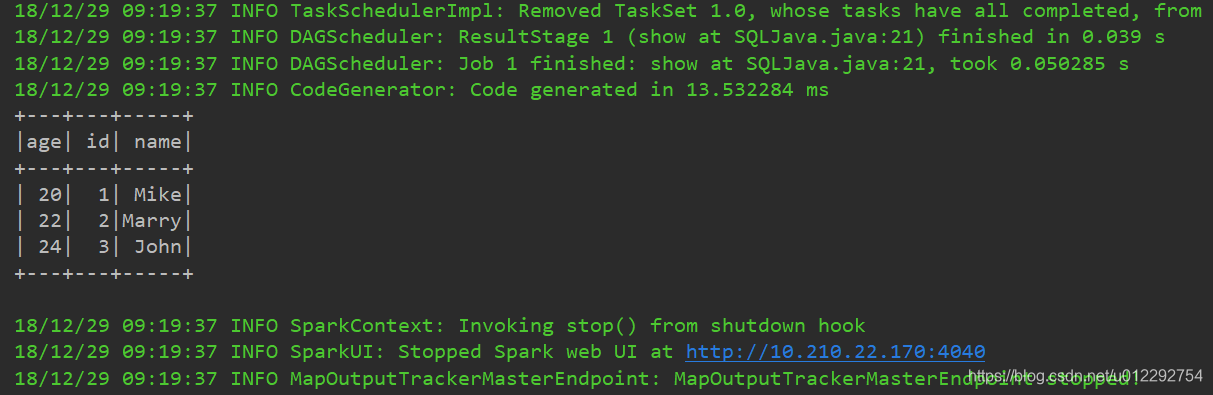
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import java.util.function.Consumer;
public class SQLJava {
public static void main(String[] args) {
SparkSession session = SparkSession.builder()
.appName("SQLJava")
.config("spark.master", "local[2]")
.getOrCreate();
Dataset<Row> df1 = session.read().json("d:/json.json");
df1.createOrReplaceTempView("stu");
df1 = session.sql("select * from stu");
df1.show();
Dataset<Row> df2 = session.sql("select * from stu where age > 20");
df2.show();
System.out.println("=============================");
//聚合查询
Dataset<Row> dfCount = session.sql("select count(*) from stu");
dfCount.show();
/*
* DataFrame 转换为 RDD
* */
JavaRDD<Row> rdd = df1.toJavaRDD();
rdd.collect().forEach(new Consumer<Row>() {
public void accept(Row row) {
Long id = row.getAs("id");
String name = row.getAs("name");
Long age = row.getAs("age");
System.out.println(id + "-" + name + "-" + age);
}
});
}
}