分布式集群搭建:http://blog.51cto.com/14048416/2327802
上面试spark普通的分布式集群搭建,存在master节点的单点故障问题。Hadoop2.x开始,已经使用zookeeper解决了单点故障。同样的策略,spark也利用了zookeeper解决了spark集群的单点故障问题。
1. 集群的规划(这里使用3台机器测试)

2.具体搭建步骤:
① 如果已经使用,并启动了spark分布式集群,请手动停止:
$SPARK_HOME/sbin/stop-all.sh
②配置并启动zookeeper集群:http://blog.51cto.com/14048416/2336178
③修改 $SPARK_HOME/conf 目录中的 spark-env.sh 配置文件
如果是之前有分布式集群的话:删除:**export SPARK_MASTER_HOST=xxx**
加入:
export SPARK_DAEMON_JAVA_OPTS= "-Dspark.deploy.recoveryMode=ZOOKEEPER - Dspark.deploy.zookeeper.url=hadoop01,hadoop02,hadoop03 - Dspark.deploy.zookeeper.dir=/spark"相关参数解释:
-Dspark.deploy.recoveryMode=ZOOKEEPER:说明整个集群状态是通过zookeeper来维护的,整个集群状态的恢复,也是通过zookeeper来维护的。就是说用 zookeeper 做了 Spark 的 HA 配置,Master(Active)挂掉的话, Master(standby)要想变成 Master(Active)的话,Master(Standby)就要像 zookeeper 读取 整个集群状态信息,然后进行恢复所有 Worker 和 Driver 的状态信息,和所有的 Application 状态信息。
-Dspark.deploy.zookeeper.url:将所有配置了 zookeeper,并且在这台机器上有可能做 master(Active)的机器都配置进来
-Dspark.deploy.zookeeper.dir:zookeeper中保存 spark 的元数据的znode,保存了 spark 的作业运行状态; zookeeper 会保存 spark 集群的所有的状态信息,包括所有的 Workers 信息,所有的 Applactions 信息,所有的 Driver 信息,如果集群。
④如果hadoop集群是高可用集群的话,一定要将core-site.xml 和 hdfs-site.xml放置$SPARK_HOME/conf 目录中,然后同步所有的spark节点。
⑤同步配置文件:
这里是在已经安装了spark分布式的基础上,只同步spark-env.sh即可:(spark集分布式集群的安装:http://blog.51cto.com/14048416/2327802)
scp -r $SPARK_HOME/confspark-env.sh hadoop02:$SPARK_HOME/conf
scp -r $SPARK_HOME/confspark-env.sh hadoop03:$SPARK_HOME/conf
⑥启动集群:
$SPARK_HOME/sbin/start-all.sh
注意:
此时,通过观察启动日志,或者检查 hadoop02 上是否包含有 master 进程等都可以得知 hadoop02 上的 master 并不会自动启动,所以需要手动启动 那么在 hadoop02 执行命令进行启动:$SPARK_HOME/sbin/start-master.sh
⑦验证集群的高可用:
主节点(active)hadoop01: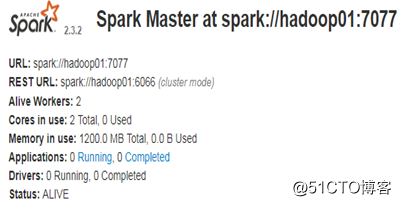
从节点(standby)hadoop02: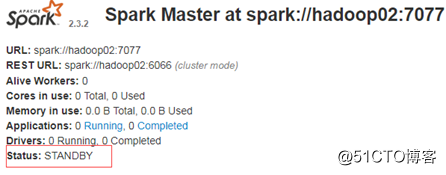
2.永久配置spark集群的日志级别:
我们运行的 spark 程序运行的情况来看,可以看到大量的 INFO 级别的日志信息。淹没了 我们需要运行输出结果。可以通过修改 Spark 配置文件来 Spark 日志级别。
具体步骤:
进入:cd $SPARK_HOME/conf
准备log4j.properties:cp log4j.properties.template log4j.properties
配置日志级别: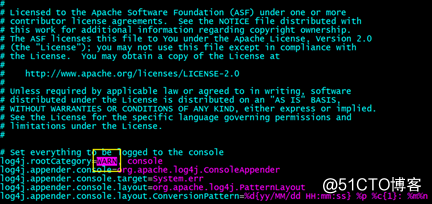
把 INFO 改成你想要的级别:主要有 ERROR, WARN, INFO, DEBUG 几种
重启集群即可。
3.spark的shell的基本使用:
(1)利用 Spark 自带的例子程序执行一个求 PI(蒙特卡洛算法)的程序:
$SPARK_HOME/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop02:7077 \
--executor-memory 512m \
--total-executor-cores 3 \
$SPARK_HOME/examples/jars/spark-examples_2.11-2.3.0.jar \
100(2)启动spark shell
启动local模式:[hadoop@hadoop01 ~]$ spark-shell
启动集群模式:
$SPARK_HOME/bin/spark-shell \
--master spark://hadoop02:7077,hadoop04:7077 \ #指定 Master 的地址
--executor-memory 512M \ #指定每个 worker 可用内存为 512M
--total-executor-cores 2 #指定整个集群使用的 cup 核数为 2 个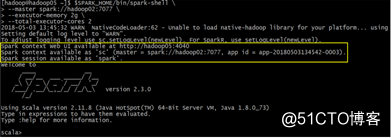
注意:
- 在运行时:executor-memory 不能超过集群的节点的内存。
- total-executor-cores:不要超过 spark 集群能够提供的总 cpu cores,否则会使用全部。最好不要使用 全部。否则其他程序由于没有 cpu core 可用,就不能正常运行。
(3)解决内存资源不足
如果底层使用的yarn的任务资源管理:
修改yarn-site.xml:
加入:
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
</property> 之后在重启yarn即可。