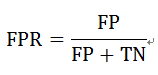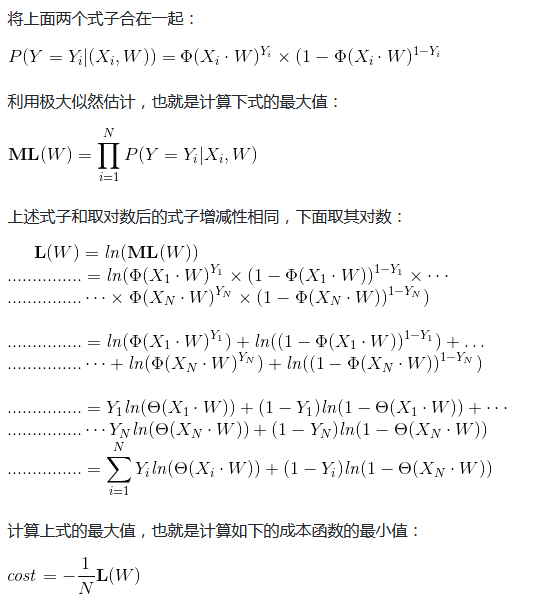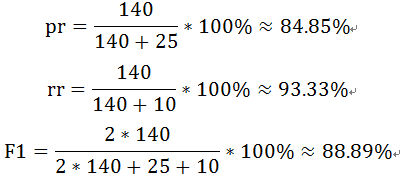
逻辑回归的输出结果是判定二分类的,在实际问题中可用来解决二分类问题,当然也可利用多次的oneVSother来解决多分类问题。
现在我们有270人的身体指标数据,包括年龄、性别、心率最大值、以及是否患有心脏病等数据。现在我们要利用逻辑回归来判断一个人是否患有心脏病。也就是根据逻辑回归的输出判定一条数据是类1,还是类0。本例中患心脏病为类0。
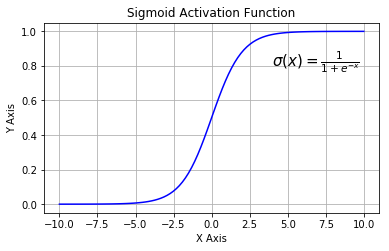
逻辑回归最关键的就是理解Sigmoid函数,也称为Logistic函数,其表达式、图像分别为:
通过图像可以更好的理解为什么被称为Logistic函数。
不难看出,此函数的输出是0-1之间的数。针对单条数据,我们这么考虑这个问题,把这个函数的输出值看作属于类1的概率,如果这条数据是类1,我们就让这个函数的值接近1;如果这条数据是类0,我们就让1减去这个函数的值接近1。多条数据的说明见下文。
下面介绍如何评价一个分类器的好坏:在评价时,一般把两种类别称为正类和负类。其中我们比较关心的类别是正类,例如本例中我们把没有心脏病的看作正类。
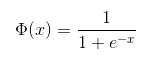
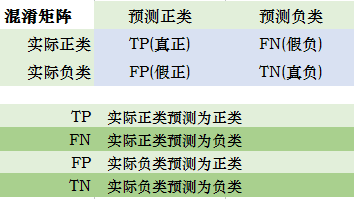
一、混淆矩阵法
其中准确率(ar):预测类别正确的样本占所有样本的比例;
精确率(pr)/查准率:正类样本中预测正确的与所有预测为正类的样本数的比;
召回率(rr)/查全率:正类样本中预测正确的占所有实际正类的比例;
综合考量:F度量(Fa):精确率和召回率的加权调和平均值,其形式为:
当a=1时,F1是精确率和召回率的调和均值,
二、ROC曲线[二分类]
绘制ROC曲线,需要用到以下2个定义:
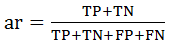
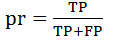
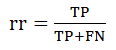
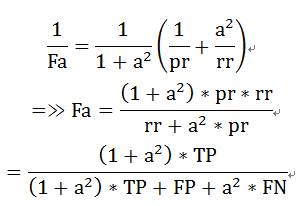
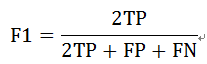
False Positive Rate(FPR,假正率):所有实际为负类的样本中,被错误地判断为正类的比例。
True Positive Rate(TPR,真正率):所有实际为正类的样本中,被正确地判断为正类的比例。
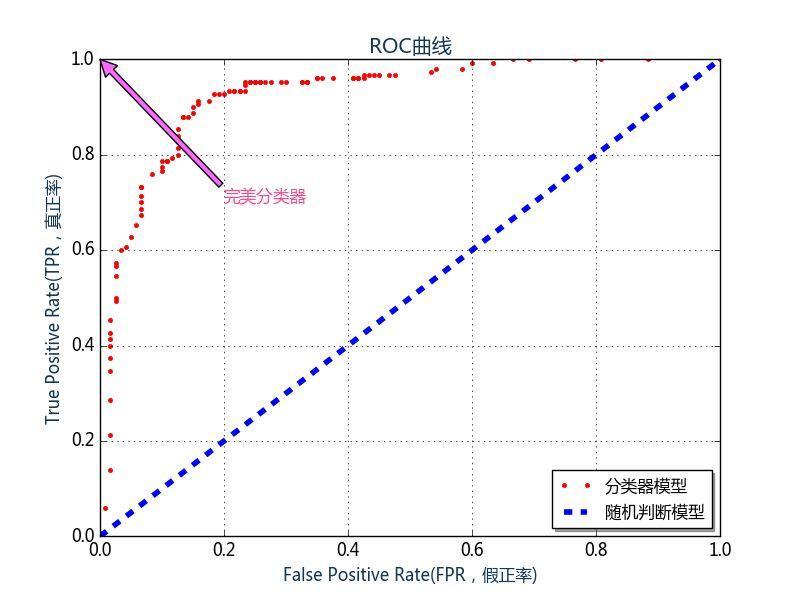
以逻辑回归为例,因为函数的输出值是一个0到1之间的数,并不是确切的0或者1,在这里面,其实是有一个阈值的。本例中这个阈值就是0.5[后文会提到]。也就是说如果函数的输出值大于等于0.5,则说明预测的为类1,否则的话,预测的为类0。因此设置不同的阈值,分类器最终的预测结果就不同。每一个阈值,都会对应一个不同的FPR和TPR,将FPR从的值小到大排列,组成X轴,对应的TPR为Y轴,构成ROC曲线。见下图:
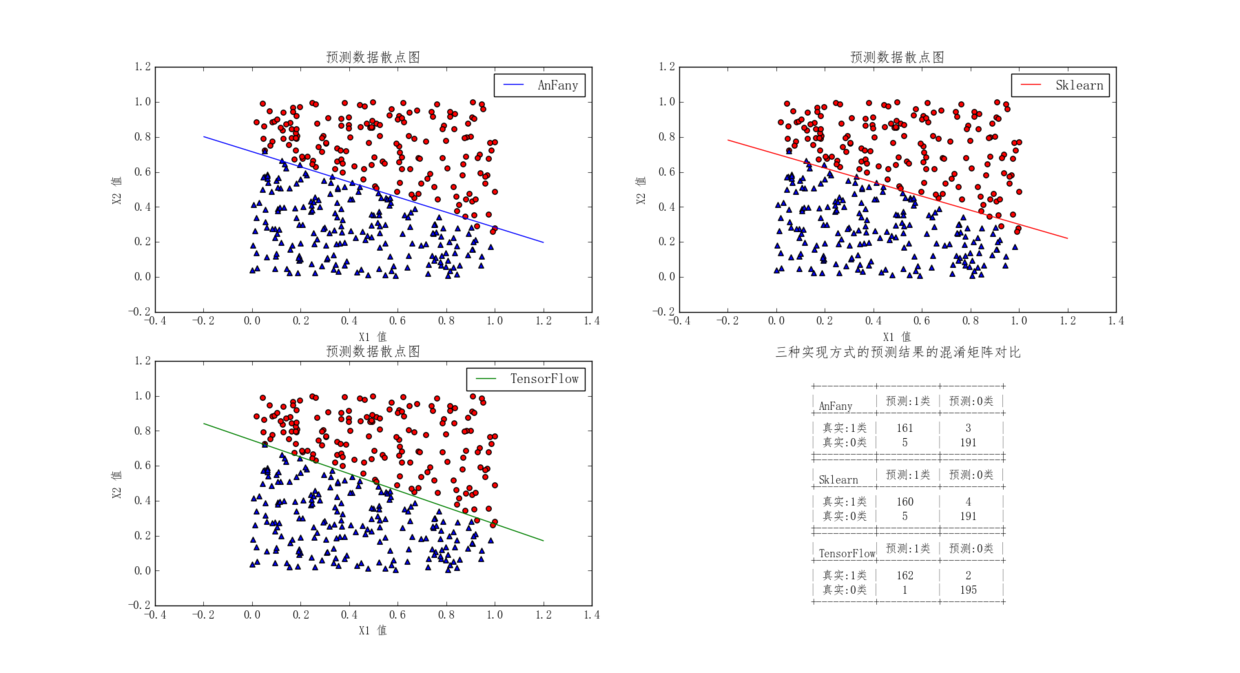
实例:心脏病预测
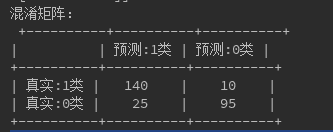
下面给出阈值为0.5时,分类器得到的混淆矩阵:
通过计算可以得到:
源码下载,扫描关注微信订阅号pythonfan, 获取更多实例和代码。