!git clone https://github.com/kb22/Heart-Disease-Prediction
!ls Heart-Disease-Prediction
!cat Heart-Disease-Prediction/Heart
机器学习 - 预测心脏病
K近邻、支持向量机、决策树、随机森林
0 导入相关库
# 基础
import numpy as np # 处理数组
import pandas as pd # 读取数据&&DataFrame
import matplotlib.pyplot as plt # 制图
from matplotlib import rcParams # 定义参数
from matplotlib.cm import rainbow # 配置颜色
%matplotlib inline
import warnings
warnings.filterwarnings('ignore') # 忽略警告信息
# 预处理数据
from sklearn.model_selection import train_test_split # 切割数据集
from sklearn.preprocessing import StandardScaler # 特征缩放
# 机器学习
from sklearn.neighbors import KNeighborsClassifier # K近邻
from sklearn.svm import SVC # 支持向量机
from sklearn.tree import DecisionTreeClassifier # 决策树
from sklearn.ensemble import RandomForestClassifier # 随机森林
1 导入数据集
dataset = pd.read_csv('Heart-Disease-Prediction/dataset.csv')
dataset.info() # 查看各列数据类型

特征:13个属性 & 1个标签
dataset.describe() # 描述统计相关信息

age(max): 77 && chol(max): 564 -> 特征缩放
dataset.head()
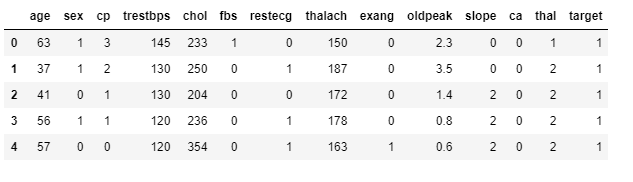
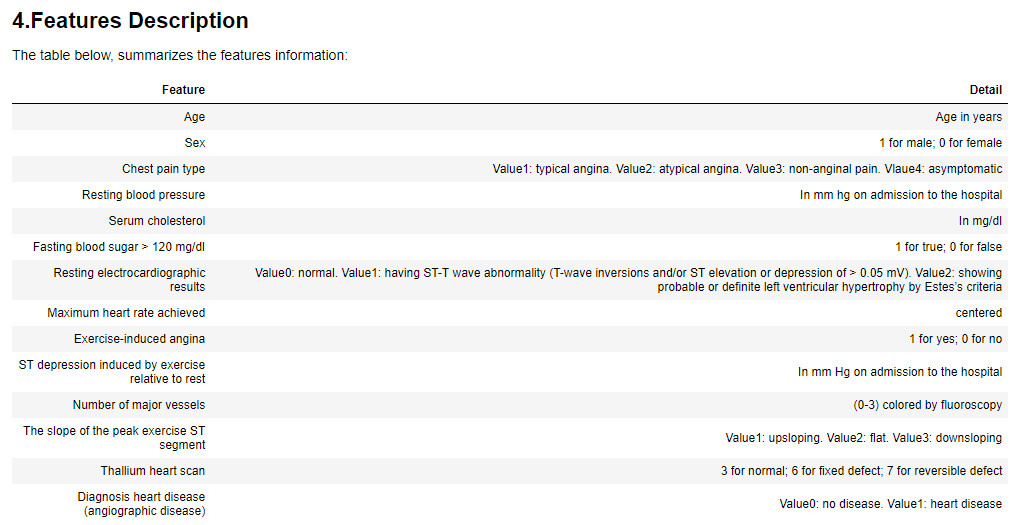
特征描述
2 理解数据
2.1 相关性矩阵
rcParams['figure.figsize'] = 14, 12 #图形大小
plt.matshow(dataset.corr()) # 相关矩阵
yticks = plt.yticks(np.arange(dataset.shape[1]), dataset.columns) # 将名称添加到矩阵
xticks = plt.xticks(np.arange(dataset.shape[1]), dataset.columns)
plt.colorbar()

观察发现,13个性征与标均与无明显相关性,正负相关均存在。
2.2 直方图
查看数据分布情况 -> 特征缩放
hist = dataset.hist()

2.3 target柱状图
dataset['target'].unique() #
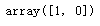
dataset[‘target’].value_counts() #

rcParams['figure.figsize'] = 8, 6 # 图形大小
plt.bar(dataset['target'].unique(), dataset['target'].value_counts(), color=['red', 'green']) # 柱状图
plt.xticks([0, 1])
plt.ylabel('Target Classes')
plt.ylabel('Count')
plt.title('Count of each Target Class')

3 特征变换
对分类特征进行变换,将每个特征转换为用1和0的两个虚拟变量(哑变量)
age:‘男’ -> ‘1’, ‘女’ -> ‘0’
# 哑变量
dataset = pd.get_dummies(dataset, columns=['sex', 'cp', 'fbs', 'restecg', 'exang', 'slope', 'ca', 'thal'])
# 特征变换
ss = StandardScaler()
columns_to_scale = ['age', 'trestbps', 'chol', 'thalach', 'oldpeak']
dataset[columns_to_scale] = ss.fit_transform(dataset[columns_to_scale])
dataset.head()

dataset.columns

4 机器学习
训练集:67% 测试集:33%
y = dataset['target']
X = dataset.drop(['target'], axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)
4.1 K近邻分类
计算参数n_neighbors从1-20的评估分数
knn_scores = []
for k in range(1, 21):
knn_classifier = KNeighborsClassifier(n_neighbors=k)
knn_classifier.fit(X_train, y_train)
knn_scores.append(knn_classifier.score(X_test, y_test))
print(knn_scores)
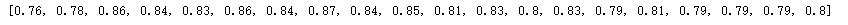
最近邻个数&评估分数(折线图)
plt.plot([k for k in range(1, 21)], knn_scores, color='blue')
for i in range(1, 21):
plt.text(i, knn_scores[i-1], (i, knn_scores[i-1]))
xticks = plt.xticks([i for i in range(1, 21)])
plt.xlabel('Number of Neighbors (n_neighbors)')
plt.ylabel('Scores')
plt.title('K Neighbors Classifier scores for different K values')

4.2 支持向量机分类
通过调整数据点与超平面之间的距离,形成一个尽可能分离不同类别的超平面
kernel : ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’
svc_scores = []
kernels = ['linear', 'poly', 'rbf', 'sigmoid'] # 'precomputed'
for i in range(len(kernels)):
svc_classifier = SVC(kernel=kernels[i])
svc_classifier.fit(X_train, y_train)
svc_scores.append(svc_classifier.score(X_test, y_test))
svc_scores

内核&评估分数(柱状图)
colors = rainbow(np.linspace(0, 1, len(kernels))) # 色彩
plt.bar(kernels, svc_scores, color=colors)
for i in range(len(kernels)):
plt.text(i, svc_scores[i], svc_scores[i])
plt.xlabel('Kernels')
plt.ylabel('Scores')
plt.title('Support Vector Classifier scores for different kernels')

4.3 决策树分类
创建一个决策树,为每个数据点分配所属类
max_features : The number of features to consider when looking for the best split(1-30)# 特征变化后数据集特征数量
dtc_scores = []
for i in range(1, len(X.columns)+1):
dtc_classifier = DecisionTreeClassifier(max_features=i, random_state=0)
dtc_classifier.fit(X_train, y_train)
dtc_scores.append(dtc_classifier.score(X_test, y_test))
print(dtc_scores)

最大特征数&评估函数(折线图)
plt.plot([i for i in range(1, len(X.columns)+1)], dtc_scores, color='blue')
for i in range(1, len(X.columns)+1):
plt.text(i, dtc_scores[i-1], (i, dtc_scores[i-1]))
xticks = plt.xticks([i for i in range(1, len(X.columns)+1)])
plt.xlabel('Max Features')
plt.ylabel('Scores')
plt.title('Decision Tree Classifier scores for different number of maximum features')

4.4 随机森林分类
决策树(从总特征中随机选择特征构成) -> 随机森林
n_estimators : The number of trees in the forest ([10, 100, 200, 500, 1000])
rfc_scores = []
estimators = [10, 100, 200, 500, 1000]
for i in estimators:
rfc_classifier = RandomForestClassifier(n_estimators=i, random_state=0)
rfc_classifier.fit(X_train, y_train)
rfc_scores.append(rfc_classifier.score(X_test, y_test))
rfc_scores
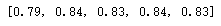
colors = rainbow(np.linspace(0, 1, len(estimators))) # 色彩
plt.bar(estimators, rfc_scores, color=colors, width=0.8)
for i in range(len(estimators)):
plt.text(i, rfc_scores[i], rfc_scores[i])
plt.xlabel('Number of estimators')
plt.ylabel('Scores')
plt.title('Random Forest Classifier scores for different of estimators')

colors = rainbow(np.linspace(0, 1, len(estimators))) # 色彩
plt.bar([i for i in range(len(estimators))], rfc_scores, color=colors, width=0.8)
for i in range(len(estimators)):
plt.text(i, rfc_scores[i], rfc_scores[i])
plt.xlabel('Number of estimators')
plt.ylabel('Scores')
plt.title('Random Forest Classifier scores for different of estimators')

colors = rainbow(np.linspace(0, 1, len(estimators))) # 色彩
plt.bar([i for i in range(len(estimators))], rfc_scores, color=colors, width=0.8)
for i in range(len(estimators)):
plt.text(i, rfc_scores[i], rfc_scores[i])
plt.xticks(ticks=[i for i in range(len(estimators))], labels=[str(estimator) for estimator in estimators])
plt.xlabel('Number of estimators')
plt.ylabel('Scores')
plt.title('Random Forest Classifier scores for different of estimators')

5 机器学习大比拼
5.1 网格搜索
from sklearn.model_selection import GridSearchCV
tree = DecisionTreeClassifier()
parameters ={'max_depth':np.arange(5,20,1)}
tree_grid = GridSearchCV(tree,parameters,cv=5)
# tree_grid.fit(X_test, y_test)
# tree_grid.fit(X_train, y_train)
tree_grid.fit(X, y)
print(tree_grid.best_params_)
print(tree_grid.best_score_)

5.2 大比拼
!pip install lightgbm
!pip install xgboost
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
import lightgbm as LightGBM
import time
rf = RandomForestClassifier()
ada = AdaBoostClassifier()
gbdt = GradientBoostingClassifier()
mdl_xgb = XGBClassifier(n_estimators=200,max_depth=6,learning_rate=0.3)
mdl_lgb = LightGBM.LGBMClassifier(num_leaves=127,n_estimators=200,max_depth=6,learning_rate=0.3,reg_alpha=0.05)
model_strlist = ['RandomForest','AdaBoost','GBDT', 'XgBoost', 'LightGBM']
train_ = []
test_ = []
time_ = []
for num,model in enumerate([rf,ada,gbdt,mdl_xgb,mdl_lgb]):
a=time.time()
model.fit(X_train, y_train)
train_acc=model.score(X_train, y_train)
test_acc=model.score(X_test, y_test)
b=time.time()-a
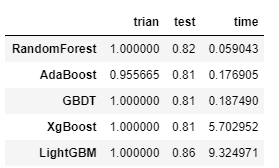
print("{} train/test accuracies : {}/{} time: {} ".format(model_strlist[num],str(train_acc)[:5],str(test_acc)[:5],b))
train_.append(train_acc)
test_.append(test_acc)
time_.append(b)
stat = {}
stat['trian'] = train_
stat['test'] = test_
stat['time'] = time_
stat = pd.DataFrame(stat,index=['RandomForest','AdaBoost','GBDT', 'XgBoost', 'LightGBM'])
stat
Heart-Disease-Prediction
搭建心脏病预测案例
Kaggle 心脏病分类预测数据分析案例
基于心电图的心脏病诊断
