
前言
本项目基于Kaggle上公开的数据集,旨在对心脏病和慢性肾病进行深入的特征筛选和提取。它利用了随机森林机器学习模型,通过对这些特征进行训练,能够预测是否患有这些疾病。不仅如此,该项目还会根据患者的症状或需求,提供相关的药物推荐,从而实现了一款实用性强的智能医疗助手。
首先,项目收集了来自Kaggle的公开数据集,这些数据包含了与心脏病和慢性肾病相关的丰富信息。然后,通过数据预处理和特征工程,从这些数据中提取出最相关的特征,以用于机器学习模型的训练。
接下来,项目采用了随机森林机器学习模型,这是一种强大的分类算法。通过使用训练数据,模型能够学习不同特征与心脏病和慢性肾病之间的关联。一旦模型经过训练,它可以对新的患者数据进行预测,判断患者是否有这些疾病。
除了疾病预测,该项目还具备一个药物推荐系统。基于患者的症状、需求和疾病诊断,系统会推荐适合的药物和治疗方案,以提供更全面的医疗支持。
综合来看,这个项目不仅可以预测心脏病和慢性肾病,还可以提供个性化的治疗建议。这种智能医疗助手有望提高医疗决策的准确性,为患者提供更好的医疗体验,并对医疗资源的合理分配起到积极作用。
总体设计
本部分包括系统整体结构图和系统流程图。
运行环境
Python环境
需要Python 3.6及以上配置,在Windows环境下推荐下载Anaconda完成Python所需环境的配置,下载地址为https://www.anaconda.com/,也可下载虚拟机在Linux环境下运行代码。
依赖库
使用下面命令安装:
pip install pandas
模块实现
本项目包括2个功能,每个功能有3个模块:疾病预测、药物推荐、模块应用,下面分别给出各模块的功能介绍及相关代码。
1. 疾病预测
本模块是一个小型健康预测系统,预测两种疾病心脏病和慢性肾病。
2. 药物推荐
本模块是一个小型药物推荐系统,对800余种症状提供药物推荐。
1)数据预处理
UCI ML药品评论数据集来源:https://www.kaggle.com/jessicali9530/kuc-hackathon-winter-2018 。包括超20多万条不同用户在某一种症状下服用某药物后的评论,并根据效果从1~10进行打分。通过分析该数据集,可以对用户症状推荐大众认可的药物。
加载数据集和数据预处理,大部分通过Pandas实现,相关代码如下:
#导入相应库函数
import pandas as pd
#读取评论数据集
train = pd.read_csv('../Thursday9 10 11/drugsComTrain_raw.csv')
test = pd.read_csv('../Thursday9 10 11/drugsComTest_raw.csv')
会自动从csv数据源读取相应的数据,如图所示。

数据集中有用户ID (UniqueID) 、症状( condition)、服用的药物(drugName) 、服用该药物后的评论(review)、打分(rating) ,其他用户对该用户评论的点赞数(usefulCount) 。
本项目根据用户对药物的打分判断是否推荐在该症状下服用此药物。打分为1分和10分可以认为用户不推荐和推荐该药物。然而,用户对药物的打分不只是1分和10分,一般来说,对一种药物有时有效但见效慢、好用但昂贵、有所缓解但效果不明显、副作用不容忽视等。打4分不一定代
表评价者的否定态度,打6分也不一定意味着评价者支持。
#通过Pandas的统计,全部评论数为
print('全部评论数:')
print(len(train))
print(len(test))
print('两端评分有:')
print(len(train))
print(len(test))
样本总量如图所示。

打1分和10分的评论总量如图5所示。

用户打分分布图如图6所示。
# 打分
train.rating.hist(bins=10)
plt.title('Distribution of Ratings')
plt.xlabel('Rating')
plt.ylabel('Count')
plt.xticks([i for i in range(1, 11)]);
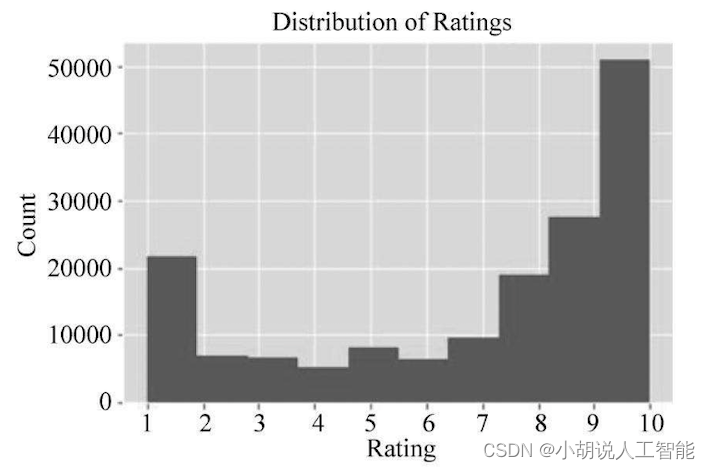
图5和图6可以看出,超过一半的用户打1分和10分,样本数据量足够机器学习用户情感,使用学习到的情感,分析打分在2~9分的用户就是内心深处支持与否。打分为1分和10分的评论情感分析学习如图7所示。
#取出评分为1和10两端的数据
train=train[train.rating.isin([1,10])]
test=test[test.rating.isin([1,10])]

评论(review)中,句子两端有引号,编写函数将引号删除。
def remove_enclosing_quotes(s):
if s[0] == '"' and s[-1] == '"':
return s[1:-1]
else:
return s
#调用写好的函数,删除双引号
train.review = train.review.apply(remove_enclosing_quotes)
test.review = test.review.apply(remove_enclosing_quotes
发现一句话中经常出现不合时宜的符号,该数据集是网络爬虫爬取的,所以有很多字符表示成ASCII码,防止被误识别为分隔,使用正则表达式从审阅文本中删除这些符号。
评论(review) 中,句子两端有引号,编写函数将引号删除。
import re
train.review = train.review.apply(lambda x: re.sub(r'&#\d+;',r'', x))
test.review = test.review.apply(lambda x: re.sub(r'&#\d+;',r'', x))
预测的标签是喜欢与不喜欢,但是drugName和condition种类很多,写进程序中可以简化工作量,所以需要将drugName和condition列前置到review中,并将完整的字符串保存为text列。
#定义函数
def combine_text_columns(data_frame, text_cols):
text_data = data_frame[text_cols]
text_data.fillna("", inplace=True)
return text_data.apply(lambda x: " ".join(x), axis=1)
#将drugName和condition列前置到review中
text_cols = ['drugName', 'condition', 'review']
train['text'] = combine_text_columns(train, text_cols)
test['text'] = combine_text_columns(test, text_cols)
CountVectorizer类将文本中的词语转换为词频矩阵。通过分词后把所有文档中的全部词作为一个字典,将每行的词用0、1矩阵表示。并且每行的长度相同,长度为字典的长度,在词典中存在,置为1,否则为0。由于大部分文本只用词汇表中很少一部分词,因此,词向量中有大量的0,说明词向量是稀疏的,在实际应用中使用稀疏矩阵存储。
#过滤规则,token的正则表达式
TOKENS_ALPHANUMERIC = '[A-Za-z0-9]+(?=\\s+)'
#CountVectorizer对象的实例化,停用词选为english内置的英语停用词
vec_alphanumeric = CountVectorizer(token_pattern=TOKENS_ALPHANUMERIC, ngram_range=(1,2), lowercase=True, stop_words='english', min_df=2, max_df=0.99)
#fit_transform是fit和transform的组合,对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值、最小值等,对trainData转换成transform,实现数据的标准化、归一化
X = vec_alphanumeric.fit_transform(train.text)
#1和10是两类,从5分开还是6分开无所谓,因为当前数据集中只有1分和10分
train['binary_rating'] = train['rating'] > 5
y = train.binary_rating
#使用Scikit-learn的train_test_split自动划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, stratify=y, test_size=0.1)
#UCI ML药品评论预处理完成
2)模型训练及应用
相关代码如下:
#使用逻辑斯蒂回归训练模型
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, stratify=y, test_size=0.1)
clf_lr = LogisticRegression(penalty='l2', C=100).fit(X_train, y_train)
#在测试集检验模型准确度
pred = clf_lr.predict(X_test)
#输出模型准确度
print("Accuracy on training set: {}".format(clf_lr.score(X_train, y_train)))
print("Accuracy on test set: {}".format(clf_lr.score(X_test, y_test)))
仅取出打分为1分和10分的评论进行情感分析学习,如图8所示,打分2~9分的评论如图9所示,代入模型分析评论情感为支持或不支持如图10所示。



由于是评1分和10分,所以正确率高,接下来将训练好的模型应用到打分为2~9分的评论中。
#读取2~9分的评论
Train_0 = train_0[train.rating.isin([2,3,4,5,6, 7,8,9])]
Train_0.head()
将评论经过数据预处理后,带入训练好的模型,得到评论感情分类。
pred_0 = clf_lr.predict(X_0)
#输出最终判决结果
print(pred_0)
#输出结果到csv文件中
import csv
data =pred_0
with open('medicine.csv','r') as csvFile: #此处的csv是源表
rows = csv.reader(csvFile)
with open('2.csv','w',newline='support') as f:#这里csv是最后输出得到的新表
writer = csv.writer(f)
i = 0
for row in rows:
row.append(data[i])
print(i)
i = i + 1
writer.writerow(row)
3)模型应用
将两个csv文件合并成一个, 本项目对某一特定症状选取支持率前三名的药物。
help_dict = {
}
#unique方法不重复的记录所有症状,遍历
import csv
headers = ['condition','medicine_1','medicine_2','medicine_3']
with open('cure.csv','a',newline='') as f:
f_csv = csv.writer(f)
f_csv.writerow(headers)
for i in train.condition.unique():
temp_ls = []
#遍历这个症状所提到,且被认同的药物
for j in train[train.condition == i & train.support==True ].drugName.unique():
#如果这种药物至少10个人提及,则记录下来
if np.sum(train.drugName == j) >= 10:
temp_ls.append((j, np.sum(train[train.drugName == j].rating) / np.sum(train.drugName == j)))
#针对症状i,从好到坏将刚刚提到的药进行排名
help_dict[i] = pd.DataFrame(data=temp_ls, columns=['drug', 'average_rating']).sort_values(by='average_rating', ascending=False).reset_index(drop=True) rows=[(i,help_dict[i].iloc[0:1].drug,help_dict[i].iloc[1:2].drug,help_dict[i].iloc[2:3].drug)]
f_csv.writerows(rows)
f.close()
#最终完成遍历时,在编译界面有一个反馈
print('ok')
得到一个csv数据库,但是数据库中除了特定的药物名称,还有一些特殊字符,通过编写Python脚本文件将它们清理干净。
其它相关博客
-
基于随机森林+小型智能健康推荐助手(心脏病+慢性肾病健康预测+药物推荐)——机器学习算法应用(含Python工程源码)+数据集(一)
-
基于随机森林+小型智能健康推荐助手(心脏病+慢性肾病健康预测+药物推荐)——机器学习算法应用(含Python工程源码)+数据集(三)
工程源代码下载
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。