数据预处理:如何处理数据中的缺失值
假设有 100 个样本和 20 个特征 ,这些数据都是机器收集回来的。若机器上的某个传感器损坏导致一个特征无效时该怎么办?此时是否要扔掉整个数据?这种情况下,另外19 个特征怎么办?它们是否还可用?答案是肯定的。因为有时候数据相当昂贵,扔掉和重新获取都是不可取的,所以必须采用一些方法来解决这个问题。
在预处理阶段需要做两件事: 第一,所有的缺失值必须用一个实数值来替换,因为我们使用的numpy数据类型不允许包含缺失值。这里选择实数 0 来替换所有缺失值,恰好能适用于Logistic回归。这样做的直觉在于,我们需要的是一个在更新时不会影响系数的值。回归系数的更新公式如下:
weights = weights + alpha * error * dataMatrix[randIndex]
如果dataMatrix的某特征对应值为 0,那么该特征的系数将不做更新,即:
weights = weights
另外,由于sigmoid(0) = 0.5,即它对结果的预测不具有任何倾向性,因此上述做法也不会对误差项造成任何影响。基于上述原因,将缺失值用 0 代替既可以保留现有数据,也不需要对优化算法进行修改。此外,该数据集中的特征取值一般不为 0,因此在某种意义上说它也满足“特殊值”这个要求。
预处理中做的第二件事是,如果在测试数据集中发现了一条数据的类别标签已经缺失,那么我们的简单做法是将该条数据丢弃。这是因为类别标签与特征不同,很难确定采用某个合适的值来替换。采用Logistic回归进行分类时这种做法是合理的,而如果采用类似kNN的方法就可能不太可行。预处理后的数据参见[1]的相关代码集。原始数据参见:http://archive.ics.uci.edu/ml/datasets/Horse+Colic
代码示例
更新到 logRegres.py,参见【机器学习笔记2】def classifyVector(inX, weights):
prob = sigmoid(sum(inX*weights))
if prob > 0.5: return 1.0
else: return 0.0
def colicTest():
frTrain = open('horseColicTraining.txt'); frTest = open('horseColicTest.txt')
trainingSet = []; trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr =[]
for i in range(21):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[21]))
trainWeights, weights_arr = stocGradAscent1(array(trainingSet), trainingLabels, 1000)
errorCount = 0; numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr =[]
for i in range(21):
lineArr.append(float(currLine[i]))
if int(classifyVector(array(lineArr), trainWeights))!= int(currLine[21]):
errorCount += 1
errorRate = (float(errorCount)/numTestVec)
print("the error rate of this test is: %f" % errorRate)
return errorRate
def multiTest():
numTests = 10; errorSum=0.0
for k in range(numTests):
errorSum += colicTest()
print("after %d iterations the average error rate is: %f" % (numTests, errorSum/float(numTests)))
main.py
import logRegres errorRate = logRegres.multiTest()
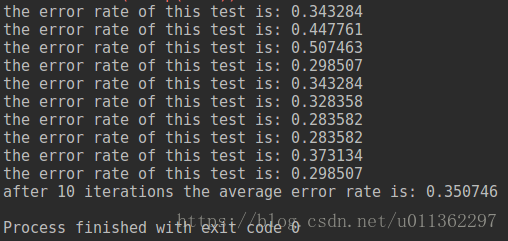
实验结果如下:
参考文献
[2] Peter. 机器学习实战