版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/lyf52010/article/details/80470295


交叉熵


权值和偏置值的调整与 无关,另外,梯度公式中的 表示输出值与实 际值的误差。所以当误差越大时,梯度就越大,参数w和b的调整就越快,训练的速度也就越快。 如果输出神经元是线性的,那么二次代价函数就是一种合适的选择。如果输出神经元是S型函数, 那么比较适合用交叉熵代价函数
初始化权值:tf.truncated_normal(shape=[10,10], mean=0, stddev=1)一般效果比较好
tf.truncated_normal(shape, mean, stddev) :shape表示生成张量的维度,mean是均值,stddev是标准差。这个函数产生正太分布,均值和标准差自己设定。这是一个截断的产生正太分布的函数,就是说产生正太分布的值如果与均值的差值大于两倍的标准差,那就重新生成。和一般的正太分布的产生随机数据比起来,这个函数产生的随机数与均值的差距不会超过两倍的标准差,但是一般的别的函数是可能的。
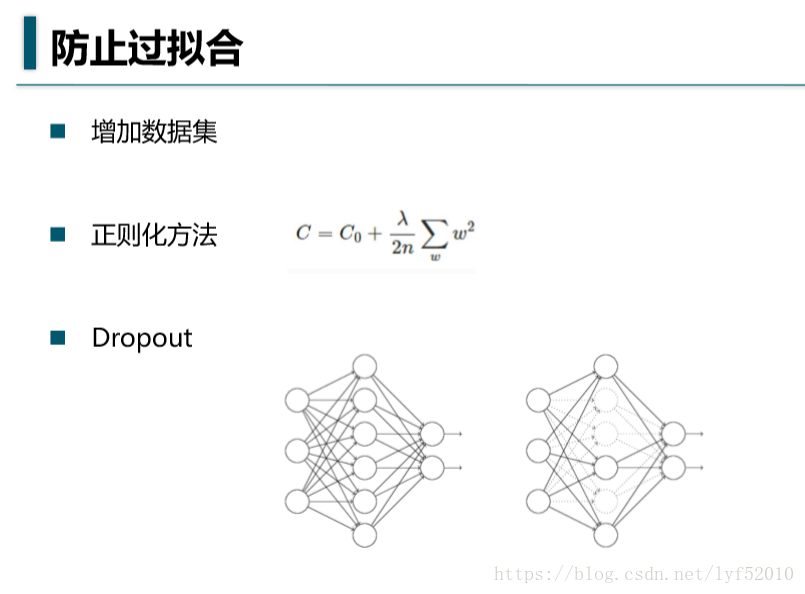
1:keep_prob = tf.placeholder(tf.float32)
2.sess.run(mini_loss,feed_dict={x:batch_xs,y:batch_ys,keep_prob:0.7})