第四章、深层神经网络
维基百科定义深度学习:“一类通过多层非线性变换对高复杂性数据建模算法的合集”。深度学习包含着两个重要的特性:多层与非线性。
线性模型最大的局限性是:能够解决的问题有限。
激活函数实现去线性化
相当于以往的神经元结构中输出为所有输入的加权和,置换为输出通过一个非线性函数。

上图则是常用的非线性激活函数(Sigmoid)
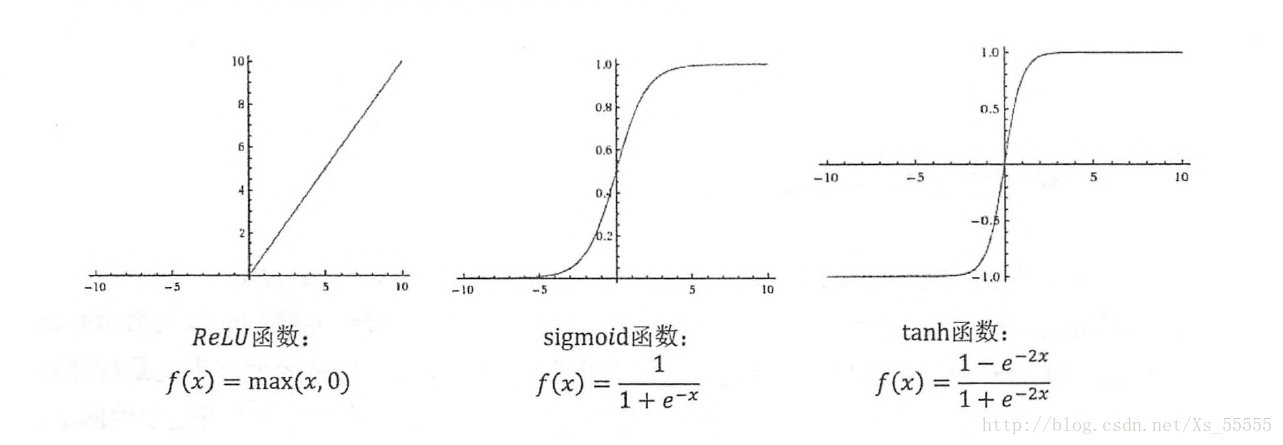
下图则是比较常用的三种激活函数: ReLU、Sigmoid、tach
损失函数的定义
神经网络模型的效果以及优化目标是通过损失函数(loss functions)来定义的。
经典的损失函数
交叉熵(cross entropy)

其中p(x) 是用来表示正确答案的概率分布,q(x)用来表示预测值的概率分布。
交叉熵不是对称的,其刻画的是通过概率分布q 来表达概率分布p 的困难程度,换言之,其刻画的是两个概率分布之间的距离,也就是说交叉熵越小,两个概率分布越接近,结果越好。
其中要用到的两个函数
tf.redece_mean(y,X)
均方误差(MSE,mean squared error)

注意 tensorflow 1.0 中 tf.select() 函数被 tf.where() 函数取代。其用法不变。
即:
tf.where(condation, x, y)tf.greater(x1, x2)
下面附上书上 4.2.2 的代码
import tensorflow as tf
from numpy.random import RandomState
batch_size = 8
x = tf.placeholder(tf.float32, shape=(None, 2), name="x-input")
y_ = tf.placeholder(tf.float32, shape=(None, 1), name="y-input")
w1 = tf.Variable(tf.random_normal([2, 1], stddev=1, seed=1))
y = tf.matmul(x, w1)
loss_less = 10
loss_more = 1
loss = tf.reduce_sum(tf.where(tf.greater(y, y_),(y-y_) * loss_more, (y_-y) * loss_less))
train_step = tf.train.AdamOptimizer(0.001).minimize(loss)
rdm = RandomState(1)
data_size = 128
X = rdm.rand(data_size, 2)
Y = [[x1 + x2 + rdm.rand()/10.0 - 0.05] for (x1, x2) in X]
with tf.Session() as sess:
init_op = tf.initialize_all_variables()
sess.run(init_op)
STEP = 5000
for i in range(STEP):
start = (i * batch_size) % data_size
end = min(data_size, start + batch_size)
sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]})
print(sess.run(w1))
1. tf.select() 函数更新并未更新。(tf.where)
2. 最有一行 print(sess.run(w1)) 的位置对齐错误。