一、前言
近期在阅读何凯明大神的Rethinking ImageNet Pre-training论文,论文中对比了深度学习提分小trick——pre-training和随机初始化之间对于任务性能的差别,实验证明预训练仅提高收敛速度但不能提高模型性能,同时预训练也不能防止过拟合。这就比较有意思了,正好我对预训练还有些不了解,正好趁着这个机会整理一下。
二、预训练+微调
1.预训练
现阶段,常见的模型训练有两种方式:
- Training From Scratch(就白手起家,啥都不用,随机初始化模型,带入数据集进行训练)
- Using Pre-trained Model(使用预训练模型)。
下面这一段纯属个人瞎想,不必当真。
这里面Training From Scratch我想大家应该都司空见惯吧,好接下来简单介绍一下预训练是啥。
简单的说,从字面上看,预训练模型(pre-training model)是先通过一批语料进行训练模型,然后在这个初步训练好的模型基础上,再继续训练或者另作他用。这就是预训练的直观表达(是不是贼直观)。那么,这个预训练模型有啥要求吗?是什么模型都能拿过来直接用吗?我想这个问题不太好回答,毕竟一个黑盒模型,啥模型是一个好模型,得靠实验结果说了算。不过,由于深度学习往往数据量越多、模型越复杂啥的,提取到的特征也就越具有代表性。而ImageNet数据量非常多,所以常用在ImageNet上跑的模型作为预训练模型。
为啥要搞预训练呢?因为现阶段,我们要跑的任务往往数据量比较少(毕竟标数据集是个麻烦活),而有些预训练模型往往在大型数据集进行训练,得到的特征具有代表性。特征具有代表性,我们可以直接拿过来用,这样就可以简化模型,减少运行时间(当然,如果要是算上预训练时间,那可能就不算减少了)。特征和模型结构和模型权重挂钩,所以常见的预训练方法大部分都是保留了部分预训练模型的结构或者模型参数。
下面,放一张图,对比一下Training From Scratch、Using Pre-trained Model对于模型的训练效果。

这个图是我将要在第三部分讲的论文里面的原图。简单说明一下这个图,纵坐标是评价指标(越高越好)、横坐标是迭代次数。这个图作者跑了5次,每次的迭代次数不一样,同时学习率调整也不一样(学习率调整策略为在跑一次的过程中的后几千个迭代是调整一下学习率,这就导致每条曲线有5个小分支,分别代表每次训练的后几千个迭代结果)。pre-train表示预训练,random init为随机初始化也就是Training From Scratch
从上面这个表可以看出,使用预训练相较于Training From Scratch,收敛更快,Training From Scratch需要更多的时间去收敛。根据何凯明大神在论文里面说,预训练和Training From Scratch的最终结果差不多。
迁移学习实战猫狗大战这个博客里面说Using Pre-trained Model常见的有三种方法。
-
Transfer Learning
-
Extract Feature Vector
-
Fine-tune
其实 “Transfer Learning” 和 “Fine-tune” 并没有严格的区分,含义可以相互交换,只不过后者似乎更常用于形容迁移学习的后期微调中。
emm,这里面的Fine-tune和Transfer Learning我是听说过的,但Extract Feature Vector是啥东西我就不晓得了。
2.微调
微调,字面意思简单的调整,调整的对象有预训练模型的网络结构和模型参数。调整方法和目标任务的情况(常见的参考对象为目标任务的数据集大小和预训练模型采用数据集的相似度)有关。

卷积神经网络(CNN)入门讲解这篇博客拿CNN举例,说明了为啥需要去微调。
- 卷积神经网络的浅层卷积提取基础特征,比如边缘,轮廓等基础特征。深层卷积层提取抽象特征,比如整个脸型。
- 预训练模型往往采用大型数据集做训练,已经具备了提取浅层基础特征和深层抽象特征的能力。
因为浅层特征提取到的基础特征在不同任务上也同样适用,故如果数据集相似度较低则可以使用预训练模型的浅层网络和其权重(也就是冻结浅层网络),相似度较高则可以考虑使用预训练模型的浅层和深层网络和其权重。这样便可以提高网络收敛速度。

那么使用微调有啥子注意事项呢?
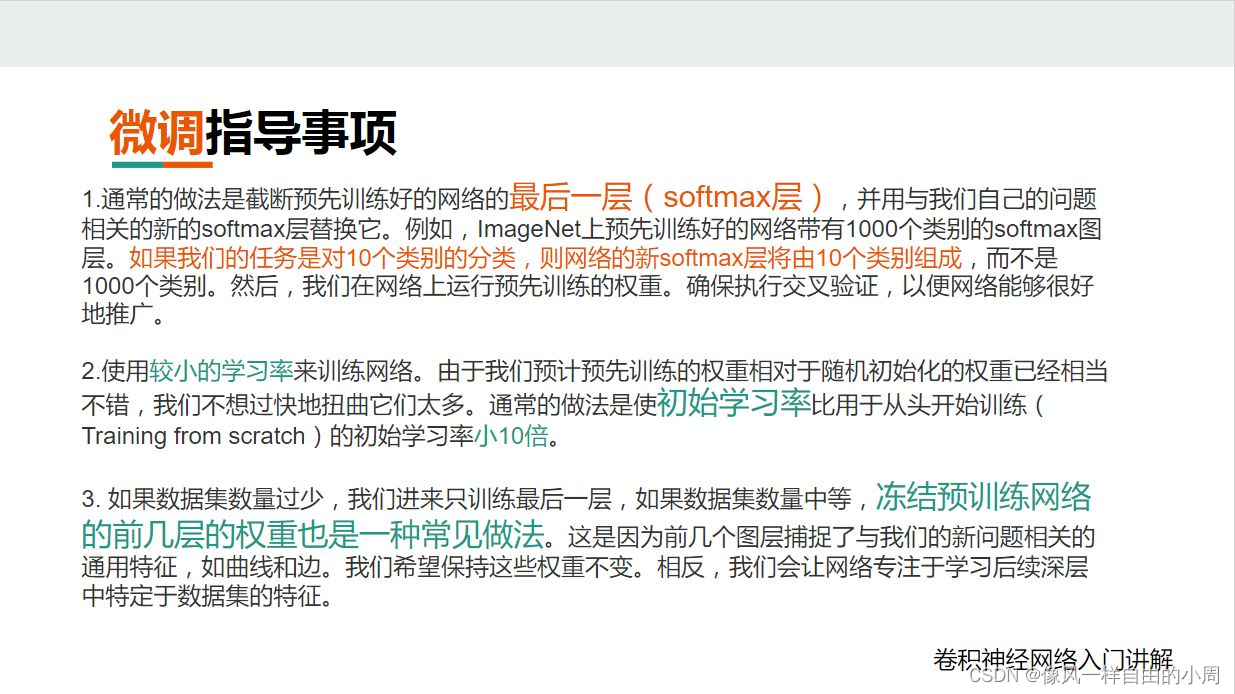
最后,介绍一个常用的名词——下游任务:利用预训练模型去微调的一些任务(例如前述文本分类)被称为下游任务(down-stream)。
3.Pytroch实现
这里简单说一下微调如何实现,我想微调的难点就在如何进行冻结网络层。
pytroch冻结某些层的常用方法这篇博客简单描述了如何使用Pytroch实现冻结网络某些层。
三、Rethinking ImageNet Pre-training论文笔记
这篇论文干的事情比较简单,就是比较了从头开始训练和预训练之间的差别。比较方法也较为粗暴,实验论证。最后作者得到的结论为:
- 在不改变模型架构的情况下,可以从头开始对目标任务进行训练
- 从头开始训练模型需要更多迭代才能充分收敛
- 在许多情况下,从头开始训练一个模型并不比ImageNet预训练差
- ImageNet预训练加速了目标任务的收敛
- 除非我们输入非常小的数据范围,否则ImageNet预训练并不一定有助于减少过拟合
- 如果目标任务对定位任务比分类更敏感,则ImageNet预训练帮助较小
这些结论部分我已经在第一部分预训练选取了一个论文中的实验结果图进行了说明。
关于如果目标任务对定位任务比分了更敏感,则ImageNet预训练帮助较小作者在论文中用关键点检测这一个任务进行了说明。

可以看到在这个图中,一开始预训练收敛速度快,但随着迭代次数变多,从头开始训练赶超了预训练结果。
此外,作者在论文中提到
- 忽略归一化的(例如BN层)可能会个人一种误解,即检测器很难从头开始训练。因为数据集大小或者设备限制导致每次训练只能采用小Batchsize,而小批量大小会严重降低BN层的准确性。故作者在论文中又引出了另外两种归一化策略Group Normalization(GN)和Synchoronized Batch Normalization(SyncBN)来提高模型性能
作者还对比了一些增强Baseline的trick对于结果的影响
- 数据增强方式,该方式会导致迭代到收敛的次数变多,但更强的数据增强方式可以缓解数据不足的问题。
- Cascade R-CNN
- Test-time augmentation
作者在论文对比了使用更小的数据集对于预训练和从头开始训练的影响。结果如下

最后,作者讨论了四个问题:
- ImageNet 预训练是否有必要?
不会——如果我们有足够的目标数据(和计算)。我们的实验表明,ImageNet 可以帮助加快收敛速度,但不一定会提高准确性,除非目标数据集太小(例如,<10k COCO 图像)。如果数据集规模足够大,直接在目标数据上训练就足够了。展望未来,这表明收集目标数据的注释(而不是预训练数据)对于提高目标任务性能更有用。 - ImageNet有帮助吗?
是的。 ImageNet 预训练一直是计算机视觉社区进步的关键辅助任务。它使人们能够在更大规模的数据可用之前看到显着的改进(例如,很长一段时间在 VOC 中)。它还在很大程度上有助于规避目标数据中的优化问题(例如,在缺乏规范化/初始化方法的情况下)。此外,ImageNet 预训练缩短了研究周期,从而更容易获得令人鼓舞的结果——预训练模型如今广泛免费提供,预训练成本无需重复支付,预训练权重微调收敛更快比从头开始。我们相信,这些优势仍将使 ImageNet 无疑对计算机视觉研究有所帮助。 - 我们需要大数据集吗?
- 我们应该最求普遍的表现吗 这个翻译感觉怪怪的,我也不晓得作者要表达啥意思