声明:参考书目《机器学习实战》作者: Peter Harrington 出版社: 人民邮电出版社 译者: 李锐 / 李鹏 / 曲亚东 / 王斌
参考博客 Jack-Cui 作者个人网站:http://cuijiahua.com/
公式:
K近邻算法的一般步骤
- 收集数据:可以使用任何方法
- 准备数据:使用Python解析、预处理数据。
- 分析数据:可以使用很多方法对数据进行分析,例如使用Matplotlib将数据可视化。
- 测试算法:计算错误率。
- 使用算法:错误率在可接受范围内,就可以运行k-近邻算法进行分类。
海伦女士一直使用在线约会网站寻找适合自己的约会对象。尽管约会网站会推荐不同的任选,但她并不是喜欢每一个人。经过一番总结,她发现自己交往过的人可以进行如下分类:
- 不喜欢的人
- 魅力一般的人
- 极具魅力的人
海伦收集约会数据已经有了一段时间,她把这些数据存放在文本文件datingTestSet.txt中,每个样本数据占据一行,总共有1000行。数据地址:DataSet。
数据主要包括四行,三种特征以及一个标签:其中第一组数据数量级远大于其他两组数据,如果直接将原始数据放入公式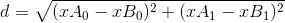
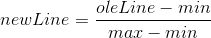

所以我们的目的这次就很清楚了,
- 首先将数据从文本导入,进行预处理,将其放置到矩阵中
- 将矩阵中的数据进行归一化处理
- 将需要进行判断的数据输入,并与DataSet中所有数据进行欧式距离计算
- 选取欧氏距离最小的前 k 个数据,将其中距离最小的数据你的类别作为本次输入数据的类别
#-*-cording:UTF-8-*-
import numpy as np
#将数据从文本读入矩阵中 filename 为文件所在的地址
def ReadFile(filename):
#打开文本并读取文本中的内容
fr = open(filename)
ReadLines = fr.readlines()
#记录文本行数是为了创建一个可以正好放入所有数据的矩阵
Len_File = len(ReadLines)
#创建一个全零矩阵大小为 Len_File * 3
Array_return = np.zeros((Len_File,3))
#创建一个列表,用于存放标签
ClassLables = []
#index用于记录存放在数组里面数据的位置的
index = 0
#逐行读取文本内容
for line in ReadLines:
#去除空格跟换行符
line = line.strip()
line = line.split('\t')
#将每行数据的前三个赋值给矩阵对应的行。数据第四个为标签
Array_return[index, : ] = line[0:3]
#按标签将数据进行分类,1代表不喜欢,2第还行,3表示还不错
if line[-1] == 'didntLike':
ClassLables.append(1)
elif line[-1] == 'smallDoses':
ClassLables.append(2)
elif line[-1] == 'largeDoses':
ClassLables.append(3)
index += 1
return Array_return, ClassLables
#归一化处理 DataSet为输入的数据集
#公式为 newValue= (oleValue - min)/(max - min)
def AutoNorm(DataSet):
#shape[0]返回的是Dataset的行数,shape[1]返回的是列数
array_len = DataSet.shape[0]
#输出DataSet行里面的最大最小值
min_value = DataSet.min(axis=0)
max_value = DataSet.max(axis=0)
value_range = max_value - min_value
#newArray = np.zeros(np.shape(DataSet))
#np.tile 是将min_value在行方向上复制 array_len 次,在列方向上复制1 次
newArray = DataSet - np.tile(min_value,(array_len,1))
newArray = newArray / np.tile(value_range,(array_len,1))
return newArray,value_range, min_value
#K近邻处理算法
#公式为 diatance ={ (x1-x2)^2 - (y1-y2)^2 }^0.5
#Data为你给的数据,DataSet为数据集,Labes为标签,K为你选择的样本数
def Classify(Data, DataSet, Lables, k):
#获取DataSet的行数,用以创建矩阵
LenData = DataSet.shape[0]
#创建一个矩阵,这个矩阵是由你给的 1*3矩阵复制成 LenData*3的矩阵减去DataSet矩阵得到的
ArryMat = np.tile(Data, (LenData, 1)) - DataSet
#将矩阵开方,其实是将矩阵内每个元素进行开方处理
SqlMat = ArryMat ** 2
#将矩阵按照列方向进行相加,变成一个LenData*1的矩阵
SumMat = SqlMat.sum(axis=1)
#将矩阵开根号处理
DistanceMat = SumMat ** 0.5
#将矩阵元素按从小到大排序,即数值越小说明距离越短,也就是越接近这个类别
SortDistance = DistanceMat.argsort()
#创建一个字典用来存放对应类别的个数
ClassCount = {}
for i in range(k):
#返回Lables
votoLables = Lables[SortDistance[i]]
#字典的get函数dict.get(key, default=None)如果没有找到对应的值,那么就会返回你设定的值,或者默认值。这里我们设置为 0
ClassCount[votoLables] = ClassCount.get(votoLables,0) + 1
#将字典里按照从大到小排序
SortClassCount = sorted(ClassCount.items(), reverse=True)
#返回最大值
return SortClassCount[0][0]
if __name__ == "__main__":
filename = "C:/Users/lpp/Desktop/datingTestSet.txt"
DataSet, Lables = ReadFile(filename)
Array, value_range, min_value = AutoNorm(DataSet)
precentTats = float(input("玩视频游戏所耗时间百分比:"))
ffMiles = float(input("每年获得的飞行常客里程数:"))
iceCream = float(input("每周消费的冰激淋公升数:"))
data = np.array([precentTats, ffMiles, iceCream])
ClassCount = Classify(data, Array, Lables, 1)
if ClassCount == 1:
print("不喜欢")
elif ClassCount == 2:
print("感兴趣")
elif ClassCount == 3:
print("非常喜欢")