何为AdaBoost
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类器。使用adaboost分类器可以排除一些不必要的训练数据特征,并放在关键的训练数据上面
应用
对adaBoost算法的研究以及应用大多集中于分类问题,同时也出现了一些在回归问题上的应用。就其应用adaBoost系列主要解决了: 两类问题、多类单标签问题、多类多标签问题、大类单标签问题、回归问题。它用全部的训练样本进行学习。
过程分析
该算法其实是一个简单的弱分类算法提升过程,这个过程通过不断的训练,可以提高对数据的分类能
力。整个过程如下所示:
- 先通过对N个训练样本的学习得到第一个弱分类器;
- 将分错的样本和其他的新数据一起构成一个新的N个的训练样本,通过对这个样本的学习得到第二个弱分类器 ;
- 将1和2都分错了的样本加上其他的新样本构成另一个新的N个的训练样本,通过对这个样本的学习得到第三个弱分类器;
- 最终经过提升的强分类器。即某个数据被分为哪一类要由各分类器权值决定。
python案例
背景
该案例介绍了有关会员营销预测的实际应用。会员部门在做会员营销时,希望能通过数据预测在下一次营销活动时,响应活动会员的具体名单和响应概率,以此来制定针对性的营销策略。
本案例是一个常规性应用模型,业务部门希望通过建立好的模型周期性自动执行,也满足营销需要。同时,业务部门还希望基于现有的辅助决策平台将会员数据筛选和查看功能跟该模型结合起来应用。
数据集
案例数据位于order.xlsx中,包括2个sheet:sheet1为本次案例的训练集,sheet2为本次案例的预测集。以下是数据概况:
以下是本数据集的13个特征变量,包括:
- age:年龄,整数型变量
- total_pageviews:总页面浏览量,整数型变量
- edu:教育程度,分类型变量,值域[1,10]
- edu_ages:受教育年限,整数型变量
- user_level:用户等级,分类型变量,值域[1,7]
- industry:用户行业划分,分类型变量,值域[1,15]
- value_level:用户价值度分类,分类型变量,值域[1,6]
- act_level:用户活跃度分类,分类型变量,值域[1,5]
- sex:性别,值域为1或0
- blue_money:历史订单的蓝券用券订单金额(优惠券的一种),整数型变量
- red_money:历史订单的红券用券订单金额(优惠券的一种),整数型变量
- work_hours:工作时间长度,整数型变量
- region:地区,分类型变量,值域[1,41]
目标变量response,1代表用户有响应,0代表用户未响应。
import time # 导入自带时间库
import numpy as np # numpy库
import pandas as pd # pandas库
from sklearn.preprocessing import OneHotEncoder # 导入OneHotEncoder库
from sklearn.model_selection import StratifiedKFold, cross_val_score # 导入交叉检验算法
from sklearn.feature_selection import SelectPercentile, f_classif # 导入特征选择方法库
from sklearn.ensemble import AdaBoostClassifier # 导入集成算法
from sklearn.pipeline import Pipeline # 导入Pipeline库
from sklearn.metrics import accuracy_score # 准确率指标
import warnings
# 设置不显示提醒
warnings.filterwarnings('ignore')
# 读取要预测的数据集
df = pd.read_excel('order.xlsx', sheetname=0)
# 获取目标变量
y = df.response
# 获取训练数据集
df_X = df.drop('response', axis=1)
# shape
df_X.shape
# (39999, 13)
# 数据集基本情况
df_X.describe().T

# 个特征数据类型
df_X.dtypes
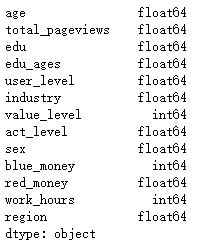
这里重点说下Dtypes输出,从输出结果可以看到,要做分类的特征包括edu、user_level、industry、act_level、sex、region都会识别为浮点型,而后面要做的二值化标志转换需要转换为int型,这里的结果为下面做转换提供了参考依据。
#缺失值
df_X.isnull().sum()
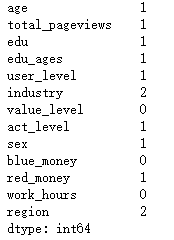
#缺失值
df_X.isnull().values.sum()
# 12
从NA Cols的结果可以看到除了value_level、blue_money和work_hours外,其他特征都有缺失值;从valid records for each Cols结果中分析发现,这些列的缺失值不多,完整数据记录是39999条而数据记录缺失最多的特征也只有2条而已;从Total number of NA lines is得到总的具有缺失值的记录是12条,由此我们判断缺失值情况不严重
# 样本均衡性审查
y.value_counts()
0 30415
1 9584
Name: response, dtype: int64
还算均衡没有出现相差太多
# 缺失值处理
# 字典:定义各个列数据转换方法,分类型的用中位数或众数,不然会出现小数
na_rules = {'age': df['age'].mean(),
'total_pageviews': df['total_pageviews'].mean(),
'edu': df['edu'].median(),
'edu_ages': df['edu_ages'].median(),
'user_level': df['user_level'].median(),
'industry': df['user_level'].median(),
'act_level': df['act_level'].median(),
'sex': df['sex'].median(),
'red_money': df['red_money'].mean(),
'region': df['region'].median()
}
X = df_X.fillna(na_rules) # 使用指定方法填充缺失值
# 做类型转换,把分类特征的类型给为整形,之后做one-hot
def type_con(df):
'''
转换目标列的数据为特定数据类型
:param df: 数据框
:return: 类型转换后的数据框
'''
var_list = {'edu': 'int32',
'user_level': 'int32',
'industry': 'int32',
'value_level': 'int32',
'act_level': 'int32',
'sex': 'int32',
'region': 'int32'
} # 字典:定义要转换的列及其数据类型
for var in var_list: # 循环读出列名和对应的数据类型
df[var] = df[var].astype(var_list[var]) # 数据类型转换
return df
X = type_con(X)
X.dtypes

# 数值转化,把类型变量做one-hot处理
def symbol_con(df, enc_object=None, train=True):
'''
将分类和顺序变量转换为二值化的标志变量
:param df: 数据框
:param enc_transform: sklearn的标志转换对象,训练阶段设置默认值为None;预测阶段使用从训练阶段获得的转换对象
:param train: 是否为训练阶段的判断状态,训练阶段为True,预测阶段为False
:return: 标志转换后的数据框、标志转换对象(如果是训练阶段)
'''
convert_cols = ['edu', 'user_level', 'industry', 'value_level', 'act_level', 'sex', 'region'] # 选择要做标志转换的列名
df_con = df[convert_cols] # 选择要做标志转换的数据
df_org = df[['age', 'total_pageviews', 'edu_ages', 'blue_money', 'red_money', 'work_hours']].values # 设置不作标志转换的列
if train == True: # 如果处于训练阶段
enc = OneHotEncoder() # 建立标志转换模型对象
enc.fit(df_con) # 训练模型
df_con_new = enc.transform(df_con).toarray() # 转换数据并输出为数组格式
new_matrix = np.hstack((df_con_new, df_org)) # 将未转换的数据与转换后的数据合并
return new_matrix, enc
else:
df_con_new = enc_object.transform(df_con).toarray() # 使用训练阶段获得的转换对象转换数据并输出为数组格式
new_matrix = np.hstack((df_con_new, df_org)) # 将未转换的数据与转换后的数据合并
return new_matrix
X, enc = symbol_con(X, None, True)
X.shape
# (39999, 92)
def get_best_model(X, y):
'''
结合交叉检验得到不同参数下的分类模型结果
:param X: 输入X(特征变量)
:param y: 预测y(目标变量)
:return: 特征选择模型对象
'''
transform = SelectPercentile(f_classif, percentile=50) # 使用f_classif方法选择特征最明显的50%数量的特征
model_adaboost = AdaBoostClassifier() # 建立AdaBoostClassifier模型对象
model_pipe = Pipeline(steps=[('ANOVA', transform), ('model_adaboost', model_adaboost)]) # 建立由特征选择和分类模型构成的“管道”对象
cv = StratifiedKFold(5) # 设置交叉检验次数
n_estimators = [20, 50, 80, 100] # 设置模型参数列表
score_methods = ['accuracy', 'f1', 'precision', 'recall', 'roc_auc'] # 设置交叉检验指标
mean_list = list() # 建立空列表用于存放不同参数方法、交叉检验评估指标的均值列表
std_list = list() # 建立空列表用于存放不同参数方法、交叉检验评估指标的标准差列表
for parameter in n_estimators: # 循环读出每个参数值
t1 = time.time() # 记录训练开始的时间
score_list = list() # 建立空列表用于存放不同交叉检验下各个评估指标的详细数据
print ('set parameters: %s' % parameter) # 打印当前模型使用的参数
for score_method in score_methods: # 循环读出每个交叉检验指标
model_pipe.set_params(model_adaboost__n_estimators=parameter) # 通过“管道”设置分类模型参数
score_tmp = cross_val_score(model_pipe, X, y, scoring=score_method, cv=cv) # 使用交叉检验计算指定指标的得分
score_list.append(score_tmp) # 将交叉检验得分存储到列表
score_matrix = pd.DataFrame(np.array(score_list), index=score_methods) # 将交叉检验详细数据转换为矩阵
score_mean = score_matrix.mean(axis=1).rename('mean') # 计算每个评估指标的均值
score_std = score_matrix.std(axis=1).rename('std') # 计算每个评估指标的标准差
score_pd = pd.concat([score_matrix, score_mean, score_std], axis=1) # 将原始详细数据和均值、标准差合并
mean_list.append(score_mean) # 将每个参数得到的各指标均值追加到列表
std_list.append(score_std) # 将每个参数得到的各指标标准差追加到列表
print (score_pd.round(2)) # 打印每个参数得到的交叉检验指标数据,只保留2位小数
print ('-' * 60)
t2 = time.time() # 计算每个参数下算法用时
tt = t2 - t1 # 计算时间间隔
print ('time: %s' % str(tt)) # 打印时间间隔
mean_matrix = np.array(mean_list).T # 建立所有参数得到的交叉检验的均值矩阵
std_matrix = np.array(std_list).T # 建立所有参数得到的交叉检验的标准差矩阵
mean_pd = pd.DataFrame(mean_matrix, index=score_methods, columns=n_estimators) # 将均值矩阵转换为数据框
std_pd = pd.DataFrame(std_matrix, index=score_methods, columns=n_estimators) # 将均值标准差转换为数据框
print ('Mean values for each parameter:')
print (mean_pd) # 打印输出均值矩阵
print ('Std values for each parameter:')
print (std_pd) # 打印输出标准差矩阵
print ('-' * 60)
return transform
# 分类模型训练
transform = get_best_model(X, y) # 获得最佳分类模型参数信息


但是对比各方面的评估指标,我们发现参数设置为80时的结果相对于100基本一致(其实小数点后面还有更多的位数能够体现出更多小模型器的结果会更好,但这种效果提升已经不明显)。
然后使用tranform对象对数据集X做特征选择得到最终建模特征数据X_final,最后使用AdaBoostClassifier模型以及最佳参数80做算法训练。
transform.fit(X, y) # 应用特征选择对象选择要参与建模的特征变量
X_final = transform.transform(X) # 获得具有显著性特征的特征变量
final_model = AdaBoostClassifier(n_estimators=100) # 从打印的参数均值和标准差信息中确定参数并建立分类模型对象
final_model.fit(X_final, y) # 训练模型
####新数据集做预测 ####
# 读取要预测的数据集
test_data = pd.read_excel('order.xlsx', sheetname=1)
# 获取最终的目标变量值
final_reponse = test_data['final_response']
# 获得预测的输入变量X
test_data = test_data.drop('final_response', axis=1)
# 查看缺失值
test_data.isnull().sum()
# 填充缺失值
X_test = test_data.fillna(na_rules)
X_test = type_con(X_test) # 数据类型转换
X_test = symbol_con(X_test, enc_object=enc, train=False) # 将分类和顺序数据转换为标志
X_test_final = transform.transform(X_test)
# 获取预测值标签
predict_labels = pd.DataFrame(final_model.predict(X_test_final), columns=['labels'])
# 获取预测概率
predict_labels_pro = pd.DataFrame(final_model.predict_proba(X_test_final), columns=['pro_0','pro_1'])
# 将预测标签、预测数据和原始数据合并
predict_pd = pd.concat((test_data, predict_labels, predict_labels_pro), axis=1)
predict_pd.head()

# 看一下准确率
accuracy_score(final_reponse, predict_labels)
0.86249010516792946
不高,还可以看
####将预测结果写入Excel####
writer = pd.ExcelWriter('order_result.xlsx') # 创建写入文件对象
predict_pd.to_excel(writer, 'data') # 将数据写入sheet1
writer.save() # 保存文件
由于本案例是一个预测性质的应用,其结果直接给到业务部门,因此没有分析型的数据结论。从最终的预测结果与真实应用结果的对照来看,业务部门对86.2%的准确率表示基本满意,能符合预期。
参考:
《python数据分析与数据化运营》 宋天龙