游戏玩家行为数据分析与预测
一、介绍项目背景与分析目标
一、需求和应用场景
随着游戏产业的不断发展,越来越多的游戏企业需要对游戏运营进行数据分析,以优化运营策略,提高用户留存率和收益。游戏运营情况分析可以帮助企业了解用户行为、收入来源、市场趋势等方面的信息,指导企业量身定制营销和用户管理策略。游戏运营情况分析需求的应用场景包括:
1. 游戏企业基于用户数据对游戏进行定向优化
游戏企业通过分析不同用户的游戏行为、留存率、付费习惯等数据,可精准定位不同用户群体的需求和习惯,针对不同用户提供个性化的游戏服务,优化用户体验,提高留存率和收益。
2. 市场营销策略的量身定制
游戏企业可以通过分析市场趋势和竞争情况,制定出更加精准的市场营销策略。根据用户的地域、年龄、性别、游戏偏好等特征,开发相应的游戏产品和营销方案,并针对用户需求进行优化。
3. 监控游戏运营状况,及时调整策略
游戏企业可以基于用户数据和游戏数据进行实时监控,掌握游戏的运营状况,及时调整策略,提高游戏的用户体验和盈利能力。
二、分析目标
以一个游戏运营情况分析项目为例,分析目标包括:
1. 用户行为分析
通过对用户数据进行分析,包括用户活跃时间、用户留存时间、用户等级分布、付费用户比例等,为游戏企业提供用户偏好及行为习惯的数据参考。基于用户行为分析,游戏企业可以更加精准地了解用户需求,优化游戏服务,提供更加优质的用户体验,提高留存率和付费率。
2. 游戏收入来源分析
通过对游戏收入来源数据进行分析,游戏企业可以了解不同收入来源之间的关联性,识别最主要的收入来源,了解为什么该收入来源最重要,可以分析提高每个渠道的付费习惯。这样的数据参考能够帮助游戏企业确定最主要的收入来源,并调整和优化收入来源的分配策略。
总之,游戏运营情况分析可帮助游戏企业了解游戏的运营情况,针对不同的问题制定合理的应对措施,优化运营策略,提高盈利能力。
二、数据集来源与说明
本次课程报告的全部数据来自数据城堡上的公开数据,链接为
本次数据集一共包涵两万余条数据,110个特征。为了便于分析选取其中的11个特征进行分析。
‘user_id’ 玩家唯一ID
‘avg_online_minutes’, 平均在线时长
‘pvp_battle_count’ 与玩家对战次数
‘pvp_lanch_count’ 主动发起与玩家对战的次数
'pvp_win_count 与玩家对战获胜的次数
‘pve_battle_count’ 与电脑对战次数
‘pve_lanch_count’, 主动发起与电脑对战的次数
‘pve_win_count’ 与电脑对战获胜次数
user_id 玩家唯一ID
pay_price 充值金额
pay_count 充值次数
prediction_pay_price 预测充值金额
三、大数据分析技术的应用
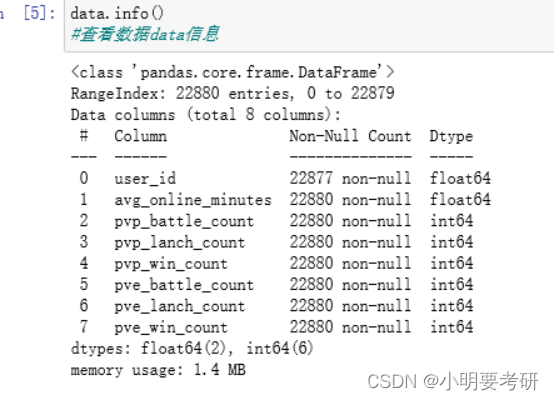
1、数据预处理的代码、注释说明及运行结果
1.导入数据集和库
df = pd.read_csv(’./data/game_player.csv’,encoding=‘gbk’)

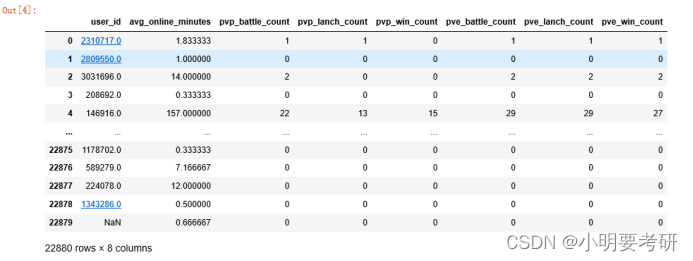
2.对需要的特征进行切片,
#切片提取需要的特征,并命名为data
data = df[
[
‘user_id’, #玩家唯一ID
'avg_online_minutes', #在线时长
'pvp_battle_count', #与玩家对战次数
'pvp_lanch_count', #主动与玩家对战的次数
'pvp_win_count', #与玩家对战获胜的次数
'pve_battle_count', #与电脑对战次数
'pve_lanch_count', #主动发起与电脑对战的次数
'pve_win_count' #与电脑对战获胜次数
]
]
Data
3.删除缺失值,并且去重
#删除缺失值
print(‘去除缺失的行前数据集形状为:’, data.shape)
data_1 = data.dropna(axis=0,how=‘any’)
print(‘去除缺失的行后数据集形状为:’, data_1.shape)
#如果使用shape会导致data1数组变为str字符串类型
#data1 = data_1[‘user_id’].drop_duplicates()
data1 = data_1.drop_duplicates()
print(‘使用drop_duplicates方法去重后游戏ID总数:’,len(data1))
并把处理出的数据集命名为data1
4.三特征的相似度矩阵
#求出与玩家对战次数,主动发起与玩家对战的次数,与玩家对战获胜的次数,三特征的pearson法相似度矩阵
corr_data1 = data[[‘pvp_battle_count’,‘pvp_lanch_count’,‘pvp_win_count’]].corr(method=‘pearson’)
print(‘与玩家对战次数,主动发起与玩家对战的次数,与玩家对战获胜的次数:\n’, corr_data1)

5.切出需要的新特征,命名为data2

6. 离差标准化
#离差标准化
#自定义离差标准化函数
def min_max_scale(data1):
data1 = (data1 - data1.min())/ (data1.max()- data1.min())
return data1
#对平均在线时间的离差标准化
time_min_max = min_max_scale(data1[‘avg_online_minutes’])
print(‘离差标准化前在线时间数据为:\n’,data1[‘avg_online_minutes’])
print(‘离差标准化后在线时间数据为:\n’,time_min_max)

7.内连接,外连接,保存预处理之后的数据集
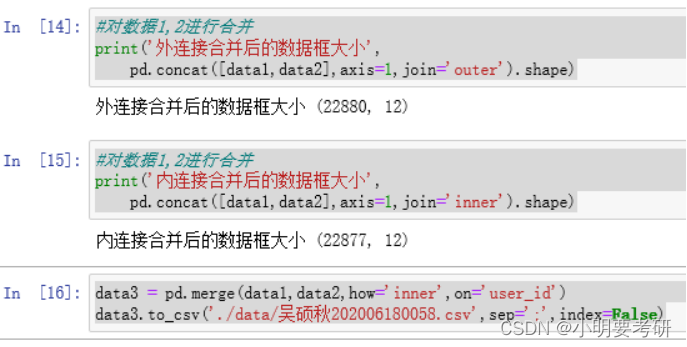
#对数据1,2进行合并
print(‘外连接合并后的数据框大小’,
pd.concat([data1,data2],axis=1,join=‘outer’).shape)
#对数据1,2进行合并
print(‘内连接合并后的数据框大小’,
pd.concat([data1,data2],axis=1,join=‘inner’).shape)
data3 = pd.merge(data1,data2,how=‘inner’,on=‘user_id’)
data3.to_csv(’./data/吴硕秋202006180058.csv’,sep=’;’,index=False)
二. 数据探索与特征构建
1.玩家活跃度分析
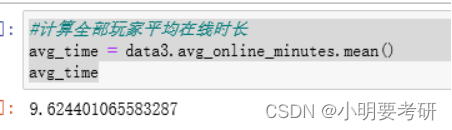
(1)计算全部玩家平均在线时长
avg_time = data3.avg_online_minutes.mean()
avg_time
(2)#计算付费玩家平均在线时长
pay_avg_time = data3[data3.pay_price > 0].avg_online_minutes.mean()
pay_avg_time

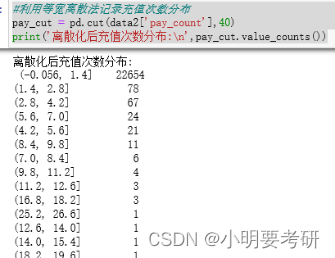
#利用等宽离散法记录充值次数分布
pay_cut = pd.cut(data2[‘pay_count’],40)
print(‘离散化后充值次数分布:\n’,pay_cut.value_counts())
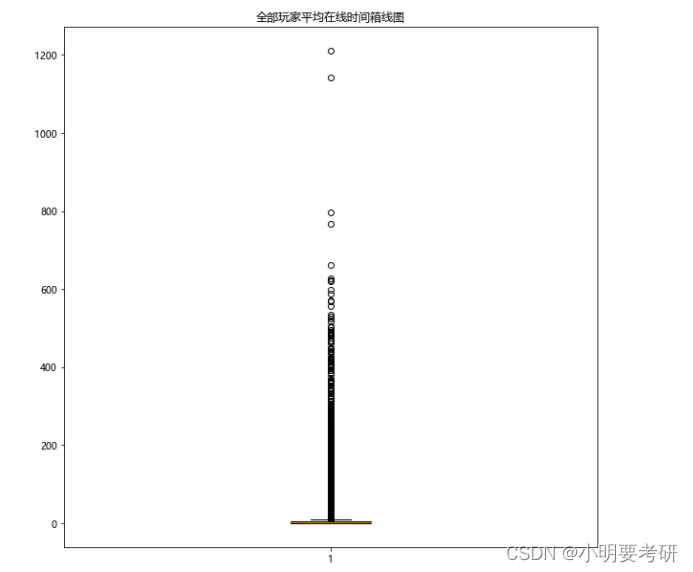
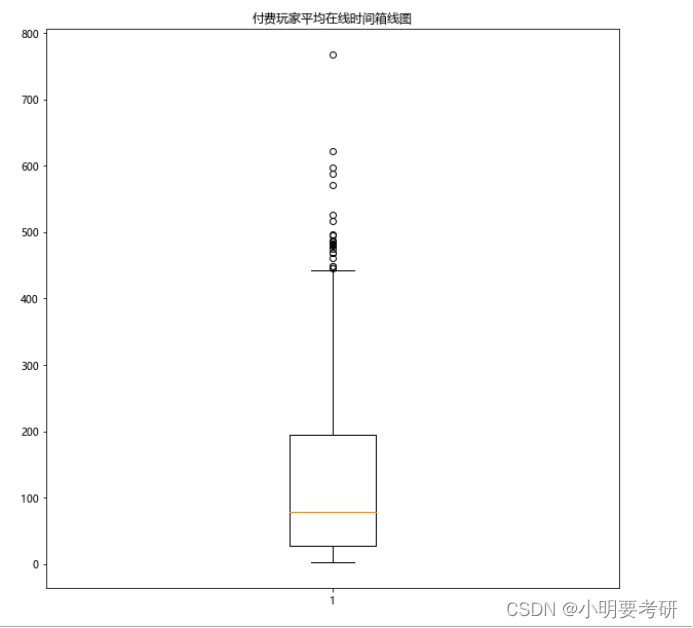
(3) 绘制玩家平均在线时间箱线图
绘制全部玩家平均在线时间箱线图
plt.figure(figsize=(10,10))
plt.boxplot(data3.avg_online_minutes)
plt.rcParams[‘font.sans-serif’]=[‘Microsoft YaHei’]
plt.rcParams[‘axes.unicode_minus’]=False
plt.title(‘全部玩家平均在线时间箱线图’)
plt.show()
绘制付费玩家平均在线时间箱线图
plt.figure(figsize=(10,10))
plt.boxplot(data3[data3.pay_price > 0].avg_online_minutes)
plt.rcParams[‘font.sans-serif’]=[‘Microsoft YaHei’]
plt.rcParams[‘axes.unicode_minus’]=False
plt.title(‘付费玩家平均在线时间箱线图’)
plt.show()
计算玩过玩家对抗游戏的玩家
pvp_avg_time =data3[data3.pvp_battle_count > 0].avg_online_minutes.mean()

评价
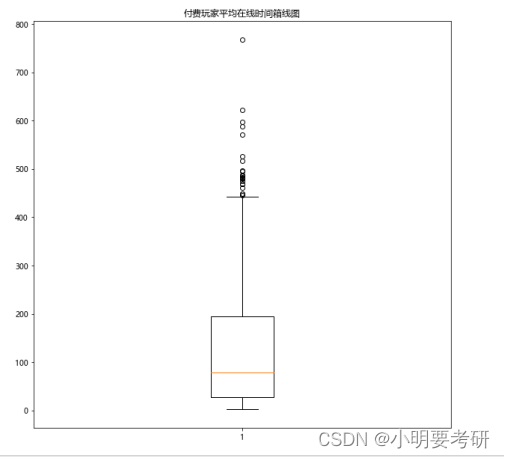
全部玩家的平均在线时长为9.6分钟,付费玩家的平均在线时长是135.8分钟,约是普通玩家的11倍,付费玩家拥有更高的活跃度。
2.玩家付费率分析
(1)获取付费次数超过0的玩家数量

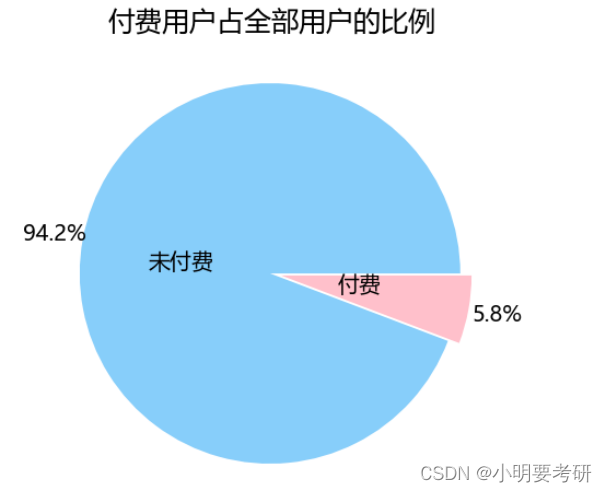
(2)绘制饼图
3.玩家付费情况分析与关联性探索
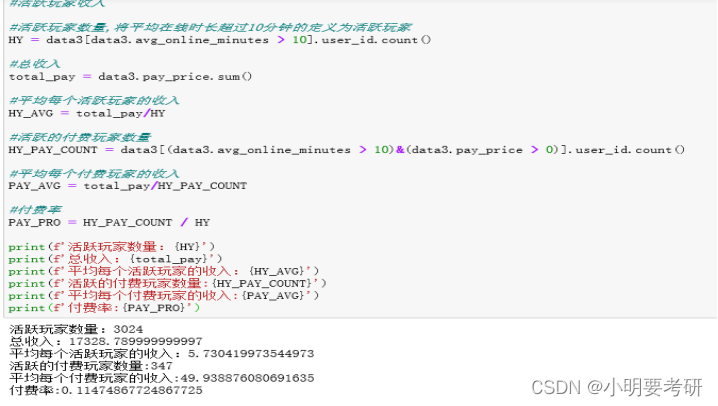
(1)定义HY, total_pay, HY_AVG, HY_PAY_COUNT, PAY_AVG, PAY_PRO
含义分别为 活跃玩家数量, 总收入, 平均每个活跃玩家的收入, 活跃的付费玩家数量, 平均每个付费玩家的收入, 付费率
(2)活跃玩家与充值金额的关系

该游戏付费率较低,还有进一步提高的空间,可以开展相关活动提高付费率。
该游戏付费玩家人均消费32,说明付费用户整体的消费能力强,后续可以对付费用户进一步分析,已保证它们的持续付费;
4.玩家游戏习惯分析
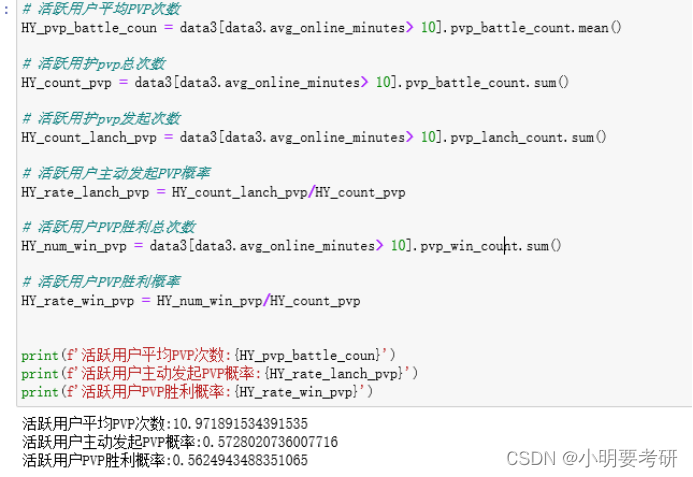
活跃用户平均PVP次数
HY_pvp_battle_coun = data3[data3.avg_online_minutes> 10].pvp_battle_count.mean()
活跃用护pvp总次数
HY_count_pvp = data3[data3.avg_online_minutes> 10].pvp_battle_count.sum()
活跃用护pvp发起次数
HY_count_lanch_pvp = data3[data3.avg_online_minutes> 10].pvp_lanch_count.sum()
活跃用户主动发起PVP概率
HY_rate_lanch_pvp = HY_count_lanch_pvp/HY_count_pvp
活跃用户PVP胜利总次数
HY_num_win_pvp = data3[data3.avg_online_minutes> 10].pvp_win_count.sum()
活跃用户PVP胜利概率
HY_rate_win_pvp = HY_num_win_pvp/HY_count_pvp
print(f’活跃用户平均PVP次数:{HY_pvp_battle_coun}’)
print(f’活跃用户主动发起PVP概率:{HY_rate_lanch_pvp}’)
print(f’活跃用户PVP胜利概率:{HY_rate_win_pvp}’)
(2)
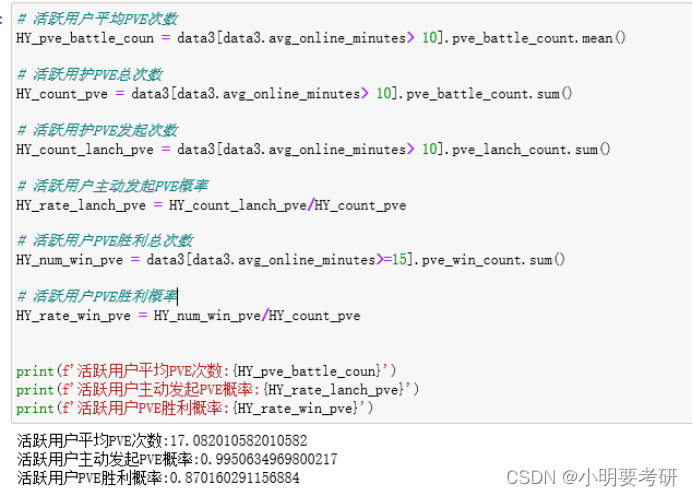
活跃用户平均PVE次数
HY_pve_battle_coun = data3[data3.avg_online_minutes> 10].pve_battle_count.mean()
活跃用护PVE总次数
HY_count_pve = data3[data3.avg_online_minutes> 10].pve_battle_count.sum()
活跃用护PVE发起次数
HY_count_lanch_pve = data3[data3.avg_online_minutes> 10].pve_lanch_count.sum()
活跃用户主动发起PVE概率
HY_rate_lanch_pve = HY_count_lanch_pve/HY_count_pve
活跃用户PVE胜利总次数
HY_num_win_pve = data3[data3.avg_online_minutes>=15].pve_win_count.sum()
活跃用户PVE胜利概率
HY_rate_win_pve = HY_num_win_pve/HY_count_pve
print(f’活跃用户平均PVE次数:{HY_pve_battle_coun}’)
print(f’活跃用户主动发起PVE概率:{HY_rate_lanch_pve}’)
print(f’活跃用户PVE胜利概率:{HY_rate_win_pve}’)
(3)
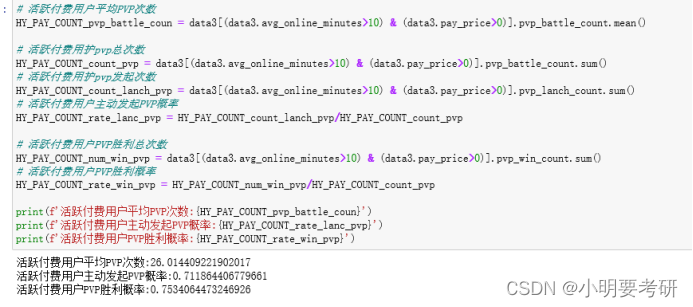
活跃付费用户平均PVP次数
HY_PAY_COUNT_pvp_battle_coun = data3[(data3.avg_online_minutes>10) & (data3.pay_price>0)].pvp_battle_count.mean()
活跃付费用护pvp总次数
HY_PAY_COUNT_count_pvp = data3[(data3.avg_online_minutes>10) & (data3.pay_price>0)].pvp_battle_count.sum()
活跃付费用护pvp发起次数
HY_PAY_COUNT_count_lanch_pvp = data3[(data3.avg_online_minutes>10) & (data3.pay_price>0)].pvp_lanch_count.sum()
活跃付费用户主动发起PVP概率
HY_PAY_COUNT_rate_lanc_pvp = HY_PAY_COUNT_count_lanch_pvp/HY_PAY_COUNT_count_pvp
活跃付费用户PVP胜利总次数
HY_PAY_COUNT_num_win_pvp = data3[(data3.avg_online_minutes>10) & (data3.pay_price>0)].pvp_win_count.sum()
活跃付费用户PVP胜利概率
HY_PAY_COUNT_rate_win_pvp = HY_PAY_COUNT_num_win_pvp/HY_PAY_COUNT_count_pvp
print(f’活跃付费用户平均PVP次数:{HY_PAY_COUNT_pvp_battle_coun}’)
print(f’活跃付费用户主动发起PVP概率:{HY_PAY_COUNT_rate_lanc_pvp}’)
print(f’活跃付费用户PVP胜利概率:{HY_PAY_COUNT_rate_win_pvp}’)
(4)
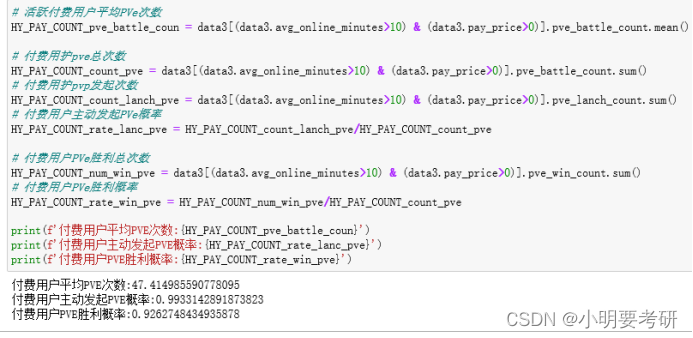
活跃付费用户平均PVe次数
HY_PAY_COUNT_pve_battle_coun = data3[(data3.avg_online_minutes>10) & (data3.pay_price>0)].pve_battle_count.mean()
付费用护pve总次数
HY_PAY_COUNT_count_pve = data3[(data3.avg_online_minutes>10) & (data3.pay_price>0)].pve_battle_count.sum()
付费用护pvp发起次数
HY_PAY_COUNT_count_lanch_pve = data3[(data3.avg_online_minutes>10) & (data3.pay_price>0)].pve_lanch_count.sum()
付费用户主动发起PVe概率
HY_PAY_COUNT_rate_lanc_pve = HY_PAY_COUNT_count_lanch_pve/HY_PAY_COUNT_count_pve
付费用户PVe胜利总次数
HY_PAY_COUNT_num_win_pve = data3[(data3.avg_online_minutes>10) & (data3.pay_price>0)].pve_win_count.sum()
付费用户PVe胜利概率
HY_PAY_COUNT_rate_win_pve = HY_PAY_COUNT_num_win_pve/HY_PAY_COUNT_count_pve
print(f’付费用户平均PVE次数:{HY_PAY_COUNT_pve_battle_coun}’)
print(f’付费用户主动发起PVE概率:{HY_PAY_COUNT_rate_lanc_pve}’)
print(f’付费用户PVE胜利概率:{HY_PAY_COUNT_rate_win_pve}’)
可视化
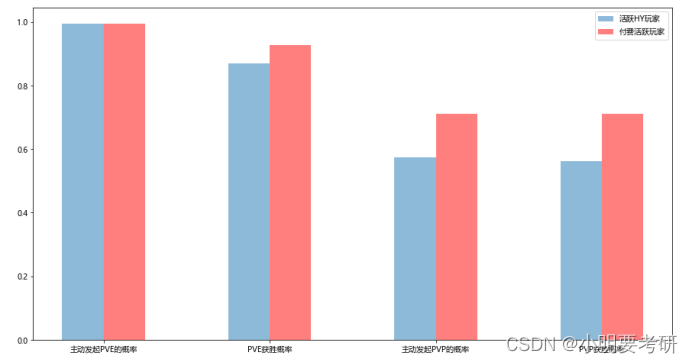
简评
1)活跃付费玩家的平均PVE次数和PVP次数都高于活跃玩家的,活跃付费玩家更愿意花时间在这个游戏上;
2)在PVP对战中,活跃付费玩家的获胜还率远超于活跃玩家,说明我们的游戏道具可以让APA享受到对战的获胜的乐趣;
三、分类模型的构建与评估的源代码、注释说明及运行结果
1.先构建特征热力矩阵图,了解各特征之间关系。
本部分需要完成回归模型和分类模型以及比较,故了解各特征关系尤为重要。在此之前创建一个新特征feature,将在线时间不满全体玩家平均在线时间一半的玩家定义为feature。并导入data3作为最后位一个特征。
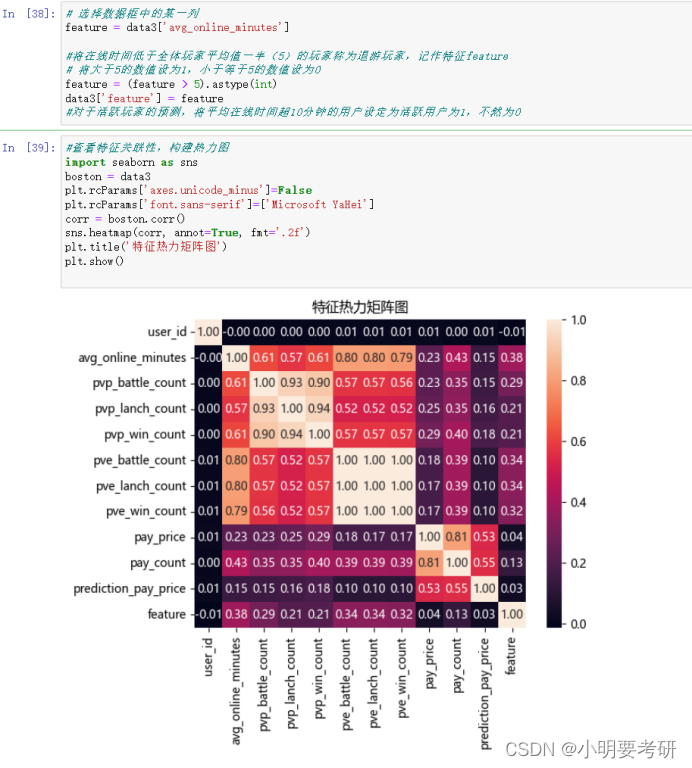
2.模型的构建数据集划分
选用上部分创建的新特征进行分析。
此部分划分数据标签,训练集测试集,并且标准化数据集,将数据集设置为算法可以直接调用的状态。
顺带绘制混淆矩阵。
划分数据标签
data3_data = data3.iloc[:, :-1]
data3_target = data3.iloc[:, -1]
#划分训练集和测试集
from sklearn.model_selection import train_test_split
data3_data_train, data3_data_test, data3_target_train, data3_target_test = train_test_split(data3_data, data3_target, test_size=0.2, random_state=66)
标准化数据集
from sklearn.preprocessing import StandardScaler
stdScale = StandardScaler().fit(data3_data_train)
data3_trainScaler = stdScale.transform(data3_data_train)
data3_testScaler = stdScale.transform(data3_data_test)
#混淆矩阵
from sklearn.metrics import confusion_matrix
def test_pre(pred):
hx = confusion_matrix(data3_target_test, pred)
print(‘混淆矩阵:\n’,hx)
#精确率
P = hx[1,1]/ (hx[0, 1] + hx[1,1])
print('精确率:\n',round(P, 3))
#召回率
R = hx[1,1]/ (hx[1, 0] + hx[1,1])
print('召回率:\n',round(P, 3))
#F1值
F1 = 2 * P * R /(P+R)
print('F1值:',round(F1, 3))
进行欠采样
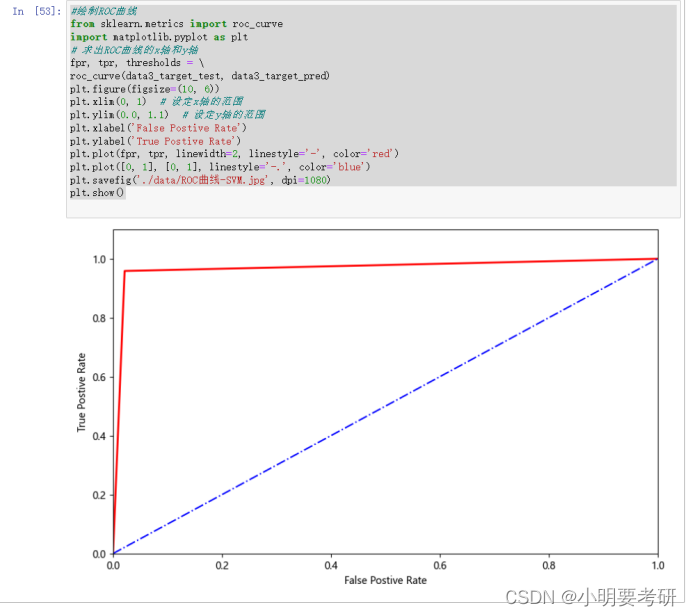
2. SVM算法构建分类模型,并评价,ROC
利用SVM算法对数据集预测,并显示前20个预测结果。预测得出正确结果2125,错误结果69准确率为96%

评价部分
F1值为0.98和0.94

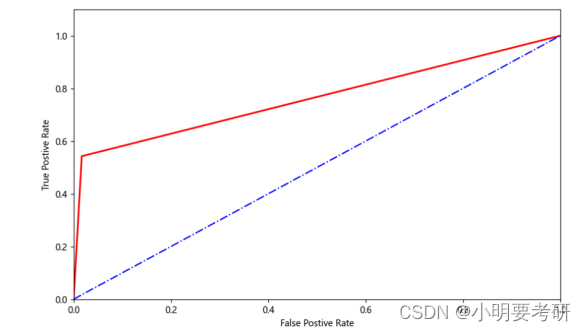
绘制ROC曲线
3.使用高斯朴素贝叶构建并评价
与SVM做法一致,差别只有算法不一样
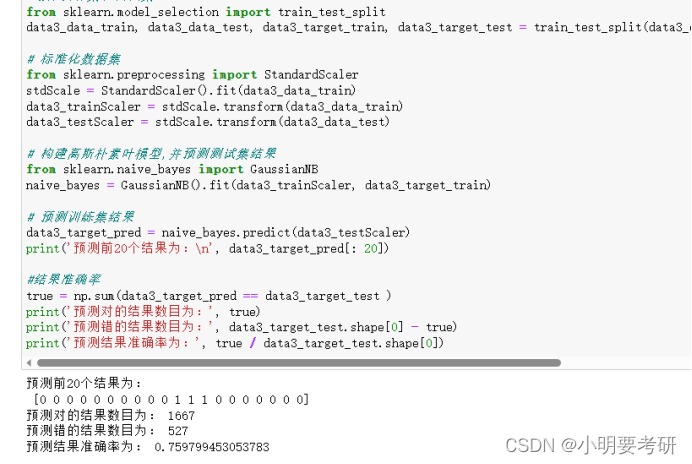
评价模型,
相比起SVM,该模型准确率稍低,为75%,而根据分类报告结果显示准确率为0.98和0.54,f1值为0.80和0.70相较svm模型来说有较大差距。各项数据都低了一部分。

绘制ROC曲线
四、回归模型的构建与评估的源代码、注释说明及运行结果
1.划分数据集
本次实验特征为“充值次数”
此部分划分数据标签,训练集测试集,并且标准化数据集,将数据集设置为算法可以直接调用的状态。

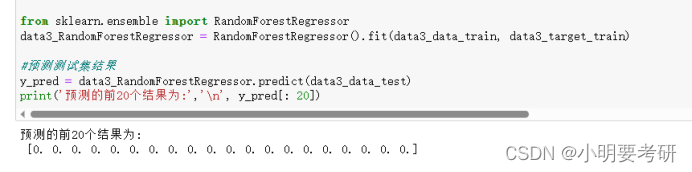
2.实验随机森林回归模型进行构建
使用回归森林树算法
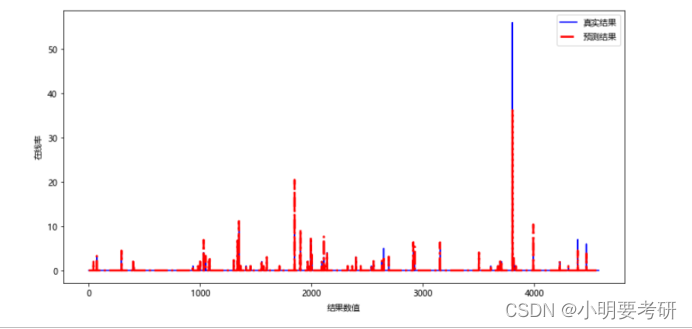
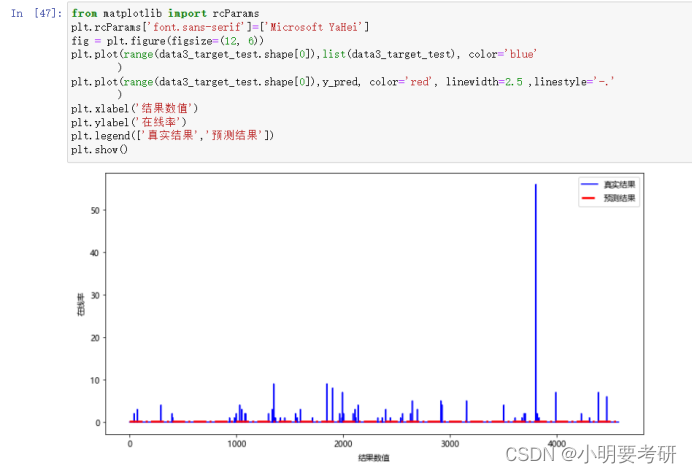
绘制回归结果可视化图
from matplotlib import rcParams
plt.rcParams[‘font.sans-serif’]=[‘Microsoft YaHei’]
fig = plt.figure(figsize=(12, 6))
plt.plot(range(data3_target_test.shape[0]),list(data3_target_test), color=‘blue’
)
plt.plot(range(data3_target_test.shape[0]),y_pred, color=‘red’, linewidth=2.5 ,linestyle=’-.’
)
plt.xlabel(‘结果数值’)
plt.ylabel(‘在线率’)
plt.legend([‘真实结果’,‘预测结果’])
plt.show()
打印并查看回归报告
导入报告,查看森林模型查看各项数据。

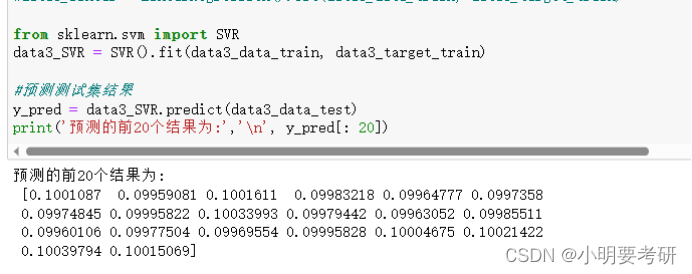
3.使用支持向量回归模型构建
模型构建
结果可视化
打印并查看回归报告
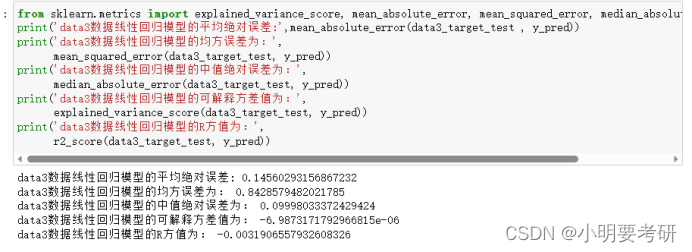
评价对比两个模型
随机森林法模型比起向量机模型,R方值更高,达到0.84,解释方差也是0.84。
五、各种模型分析结果的对比与说明
评价对比两个回归模型
随机森林法模型比起向量机模型,R方值更高,达到0.84,解释方差也是0.84。
分类模型对比评价
评价模型,相比起SVM,该模型准确率稍低,为75%,而根据分类报告结果显示准确率为0.98和0.54,f1值为0.80和0.70相较svm模型来说有较大差距。各项数据都低了一部分。
六、数据可视化技术的应用
1、第一种数据可视化技术运用的源代码及运行结果、简要说明
箱线图的绘制,箱线图是可以清晰展示数据五个统计量,最小值、下四分位数、中位数、上四分位数和最大值,并且简洁易懂。由于本次可视化为平均在线时间分析,需要多种指标综合对比,所以很适合箱线图的绘制。
绘制付费玩家平均在线时间箱线图
plt.figure(figsize=(10,10))
plt.boxplot(data3[data3.pay_price > 0].avg_online_minutes)
plt.rcParams[‘font.sans-serif’]=[‘Microsoft YaHei’]
plt.rcParams[‘axes.unicode_minus’]=False
plt.title(‘付费玩家平均在线时间箱线图’)
plt.show()
2、第二种数据可视化技术运用的源代码及运行结果、简要说明
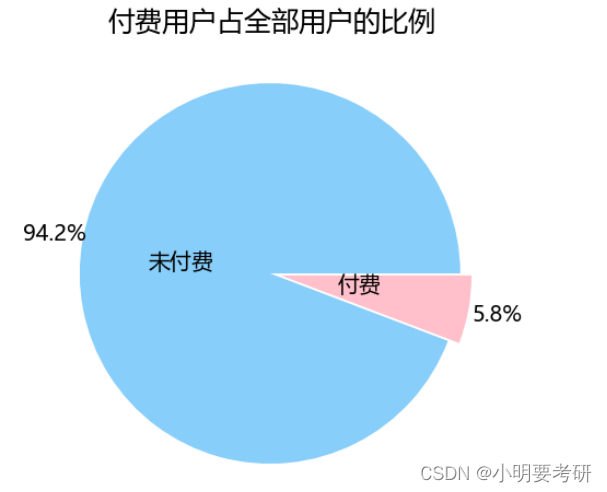
饼图的优势在于强调比例和易于理解,本次选择对比付费玩家和未付费玩家数量上的差距。对于这种小型数据集,饼图可以准确看出两者之间所占比例和差距。
制作占比的饼状图
plt.figure(figsize=(8,8))
绘图
patches,l_text,p_text = plt.pie([22877 - pay_num , pay_num],
labels=[‘未付费’,‘付费’],
labeldistance = 0.3,
colors=[’#87CEFA’,’#FFC0CB’],
explode=[0.01,0.05],
autopct=’%1.1f%%’,
pctdistance=1.15)
设置标签大小
for t in l_text:
t.set_size(20)
设置百分数字体大小
for t in p_text:
t.set_size(20)
设置标题
plt.title(‘付费用户占全部用户的比例’,size=25)
plt.show()
3.第三种数据可视化技术运用的源代码及运行结果、简要说明
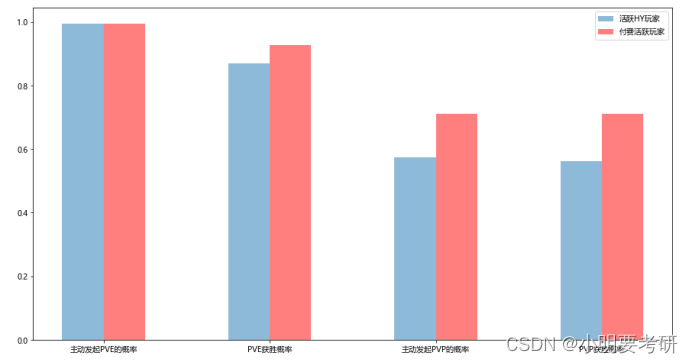
柱状图优势在于可以通过高度来表示不同类别间的数值差异,并且单一绘图的简洁高效使得比较容易。所以一图内很容易对各个数据进行不同的两两比较从而显示差距。
plt.figure(figsize=(15,8))
AU玩家
plt.bar([0.75,2.75,4.75,6.75],[HY_rate_lanch_pve, HY_rate_win_pve, HY_rate_lanch_pvp, HY_rate_win_pvp],width=0.5,alpha=0.5,label=‘活跃HY玩家’)
plt.bar([1.25,3.25,5.25,7.25],[ HY_PAY_COUNT_rate_lanc_pve,HY_PAY_COUNT_rate_win_pve , HY_PAY_COUNT_rate_lanc_pvp, HY_PAY_COUNT_rate_lanc_pvp],width=0.5,color=‘r’,alpha=0.5,label=‘付费活跃玩家’)
plt.xticks([1,3,5,7],[‘主动发起PVE的概率’,‘PVE获胜概率’,‘主动发起PVP的概率’,‘PVP获胜概率’])
plt.legend()
plt.show()
七、课程结论与心得
对于本次课程报告,将之前上课所学过的知识全部总结,融会贯通了起来。最主要包括数据预处理,探索性分析,回归模型和分类模型的创建都有了新的理解。
对于数据预处理,数据预处理是任何数据分析、机器学习或深度学习项目的重要步骤,其目的是确保无缺失数据、标准化、清晰和一致性的数据集,以便可以更好地进行各种分析、模型拟合或预测。数据清洗是数据预处理的第一步,包括去除重复值、解决缺失值和异常值处理。然后是特征处理是数据预处理的另一个重要部分,特征处理包括选择、提取和转换数据特征。在第一步清洗后,需要梳理数据,并精细特征提取。在进行大规模数据分析和机器学习阶段之前,数据预处理的成功非常重要,因为它有助于提高准确性,并最大程度地清楚样本的噪声和推动最终结果的决定性。
对于探索性分析,在数据预处理和建模阶段之前,深入了解数据集的所有细节,并获得尽可能多的信息和潜在利害关系,以便有效地规划下一步的算法和建模任务,并减少风险。
回归模型是预测数值变量的常见有监督学习任务,不仅可以提高数据的准确性和精度,而且在很多实际问题中都发挥着重要作用。理解不同类型的回归模型和评估标准,并掌握优化策略技能,将有更好地选择、构建和验证模型并取得更好的预测结果。
分类模型是一种常见的有监督学习任务,不仅可以提高数据的分类精度和准确性,而且在很多实际问题中都发挥着重要作用。理解分类模型的分类类型和评估指标,并掌握优化技巧和方法。
对于大作业的收获,最主要还是细节性的问题,例如预处理时对于数据的去重,必须使用drop而非list或者其他,因为只有drop不会改变数组的结构。其次就是关于分类部分,在预测前必须画出热力图查看各个特征相关性,以便于直观理解。
