项目介绍
- 数据来源:kaggle银行营销数据
- 工具:Python、Jupyter Notebook
本项目采取的是kaggle银行营销的数据源,主要是预测客户是否会订购银行的产品,但是,这次我将使用numpy、pandas、matplotlib数据分析三件套,基于源数据,深入分析影响银行三大业务—存款、贷款、营销产品的因素,分析结果可能不是很完善, Try my best!
我的理解
这是第一次自己比较正式的使用Python进行数据分析,所以在进行数据分析之前,需要理清自己的分析思路:首先是对于这份数据的理解,确定数据分析目标: 我到底需要分析这个数据的什么?需要得出什么样的结论?我的答案是:想要获得与银行存款、贷款和营销产品相关的主要用户群体及它们之间的影响因素,为下次银行活动提供数据支持;其次,有了目标,我需要如何做?我主要分为3步:
- 了解数据:解析源数据
- 数据处理:去除垃圾数据及不可用数据
- 目标数据分析:针对项目的分析目标,进行数据可视化,对比分析
最后,对数据分析进行总结,给出自己的思考看法。
了解数据
源数据解析
首先,查看源数据,发现每一行的数据都使用 “;” 隔开,表头含义如下:

部分源数据展示:

源数据概况
导入需要的工具包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
读入数据

data = pd.read_csv(r"D:\Desktop\train.csv",sep=";")
展示前五条数据
data.head()
| age | job | marital | education | default | balance | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 58 | management | married | tertiary | no | 2143 | yes | no | unknown | 5 | may | 261 | 1 | -1 | 0 | unknown | no |
| 1 | 44 | technician | single | secondary | no | 29 | yes | no | unknown | 5 | may | 151 | 1 | -1 | 0 | unknown | no |
| 2 | 33 | entrepreneur | married | secondary | no | 2 | yes | yes | unknown | 5 | may | 76 | 1 | -1 | 0 | unknown | no |
| 3 | 47 | blue-collar | married | unknown | no | 1506 | yes | no | unknown | 5 | may | 92 | 1 | -1 | 0 | unknown | no |
| 4 | 33 | unknown | single | unknown | no | 1 | no | no | unknown | 5 | may | 198 | 1 | -1 | 0 | unknown | no |
展示后五条数据
data.tail()
| age | job | marital | education | default | balance | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 45206 | 51 | technician | married | tertiary | no | 825 | no | no | cellular | 17 | nov | 977 | 3 | -1 | 0 | unknown | yes |
| 45207 | 71 | retired | divorced | primary | no | 1729 | no | no | cellular | 17 | nov | 456 | 2 | -1 | 0 | unknown | yes |
| 45208 | 72 | retired | married | secondary | no | 5715 | no | no | cellular | 17 | nov | 1127 | 5 | 184 | 3 | success | yes |
| 45209 | 57 | blue-collar | married | secondary | no | 668 | no | no | telephone | 17 | nov | 508 | 4 | -1 | 0 | unknown | no |
| 45210 | 37 | entrepreneur | married | secondary | no | 2971 | no | no | cellular | 17 | nov | 361 | 2 | 188 | 11 | other | no |
数据信息
包括数据的index,列名、空值和非空值计数等,可以为我们后面的数据处理和数据可视化分析做好铺垫。
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 45211 entries, 0 to 45210
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 age 45211 non-null int64
1 job 45211 non-null object
2 marital 45211 non-null object
3 education 45211 non-null object
4 default 45211 non-null object
5 balance 45211 non-null int64
6 housing 45211 non-null object
7 loan 45211 non-null object
8 contact 45211 non-null object
9 day 45211 non-null int64
10 month 45211 non-null object
11 duration 45211 non-null int64
12 campaign 45211 non-null int64
13 pdays 45211 non-null int64
14 previous 45211 non-null int64
15 poutcome 45211 non-null object
16 y 45211 non-null object
dtypes: int64(7), object(10)
memory usage: 5.9+ MB
数据描述
包括了一些数值类型的数据描述,包括计数、平均值等,让我们更好的理解源数据
data.describe()
| age | balance | day | duration | campaign | pdays | previous | |
|---|---|---|---|---|---|---|---|
| count | 45211.000000 | 45211.000000 | 45211.000000 | 45211.000000 | 45211.000000 | 45211.000000 | 45211.000000 |
| mean | 40.936210 | 1362.272058 | 15.806419 | 258.163080 | 2.763841 | 40.197828 | 0.580323 |
| std | 10.618762 | 3044.765829 | 8.322476 | 257.527812 | 3.098021 | 100.128746 | 2.303441 |
| min | 18.000000 | -8019.000000 | 1.000000 | 0.000000 | 1.000000 | -1.000000 | 0.000000 |
| 25% | 33.000000 | 72.000000 | 8.000000 | 103.000000 | 1.000000 | -1.000000 | 0.000000 |
| 50% | 39.000000 | 448.000000 | 16.000000 | 180.000000 | 2.000000 | -1.000000 | 0.000000 |
| 75% | 48.000000 | 1428.000000 | 21.000000 | 319.000000 | 3.000000 | -1.000000 | 0.000000 |
| max | 95.000000 | 102127.000000 | 31.000000 | 4918.000000 | 63.000000 | 871.000000 | 275.000000 |
数据处理
经过上一步的数据预览,我们发现源数据并没有出现空值,又为我们的工作减轻了负担,接下来我们就对数据的重复值、异常值及一些我们不需要的数据进行处理(其实并无其他垃圾数据):
删除previous、day、month三列数据
data.drop(columns=["day", "month", "previous"], inplace=True, axis=1)
查找重复值
data.duplicated().value_counts()
False 45211
dtype: int64
查找异常值—年龄大于120
data[data["age"] >= 120].count()
数据分析
数据展示分析
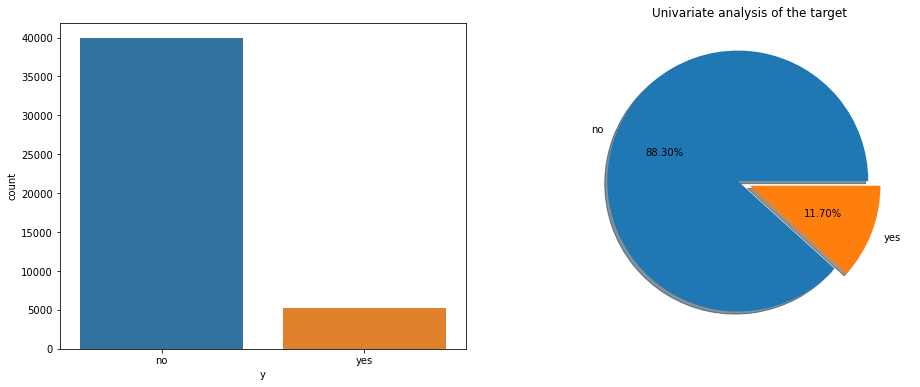
订购银行产品数据分析
可以看到,大量客户并不愿意订购银行提供的产品,只有11.7%的人说可以,这种巨大的差距可以表明人们的立场,大多数人更喜欢第三方平台或其他的金融产品(以我们为例:支付宝),后面将会更加深入研究影响人们订阅银行产品的原因。
data.y.value_counts()
no 39922
yes 5289
Name: y, dtype: int64
# 数据概况---人们是否愿意订购银行产品(Target)
# 画布*2
fig, axes = plt.subplots(nrows = 1,ncols = 2,figsize = (16,6))
# 饼图传入参数
y_pct = data.y.value_counts()*100/len(data)
# 条形图
plt.title("Univariate analysis of the target")
sns.countplot(x = "y", data = data, order = data["y"].value_counts().index, ax = axes[0])
# 饼状图
axes[1].pie(x = y_pct, autopct='%1.2f%%', labels = y_pct.index, shadow = True, explode=(0.1,0))
plt.show()
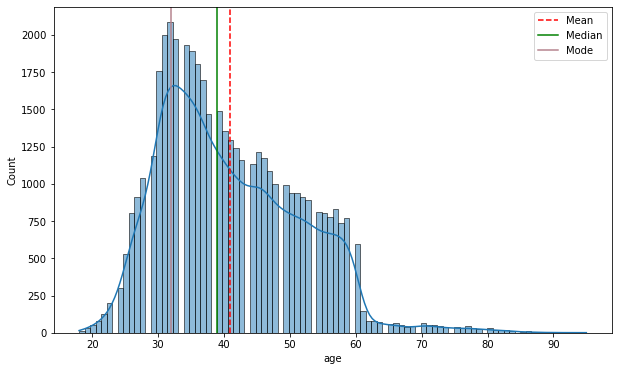
客户群体—年龄特征
从下kde分布图中可以看出,客户年龄峰值出现在30-40岁之间,这个年纪人们工作效率或者更愿意参与银行的活动,其次客户主要分布在30-60岁之间,可以集中把主要用户群体放在30-60岁的客户
# 数据概况---年龄分布
mean = data.age.mean()
median = data.age.median()
mode = data.age.mode().values[0]
plt.figure(figsize = (10, 6))
sns.histplot(data = data, x = data.age, kde = True)
plt.axvline(mean, color='r', linestyle='--', label="Mean")
plt.axvline(median, color='g', linestyle='-', label="Median")
plt.axvline(mode, color='#b5838d', linestyle='-', label="Mode")
plt.legend()
plt.show()
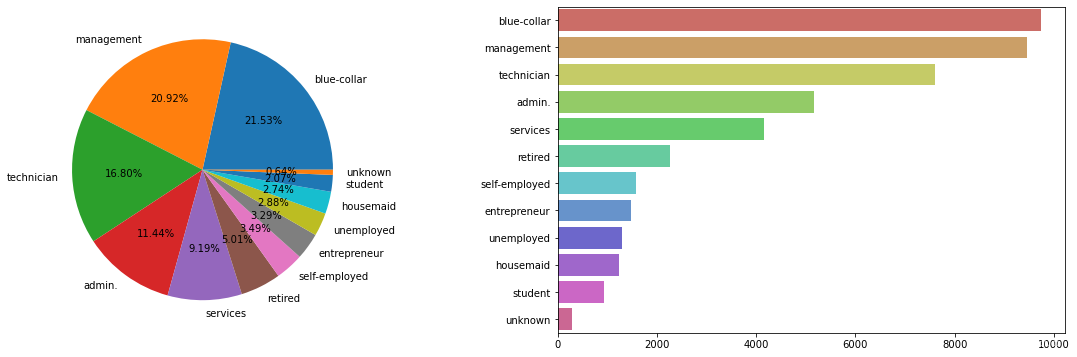
客户群体—工作种类
用户的工作类型和收入都会影响到人们存款、贷款及订阅产品的积极性。从图中可以看出,主要的用户群体是蓝领、管理者、技术人员、行政人员、和服务类工作人员,他们占据了8成以上的数量,从工作性质上也可以看出,他们更加需要银行提供的产品帮助,用于理财等。
data.job.value_counts()
blue-collar 9732
management 9458
technician 7597
admin. 5171
services 4154
retired 2264
self-employed 1579
entrepreneur 1487
unemployed 1303
housemaid 1240
student 938
unknown 288
Name: job, dtype: int64
# 数据概况---职位分布
job_pct = data.job.value_counts()*100/len(data)
fig, axes = plt.subplots(nrows = 1,ncols = 2,figsize = (20,6))
axes[0].pie(x=job_pct,autopct='%1.2f%%',labels = job_pct.index)
sns.barplot(x=data.job.value_counts().values, y=data['job'].value_counts().index, palette="hls",ax = axes[1])
plt.show()
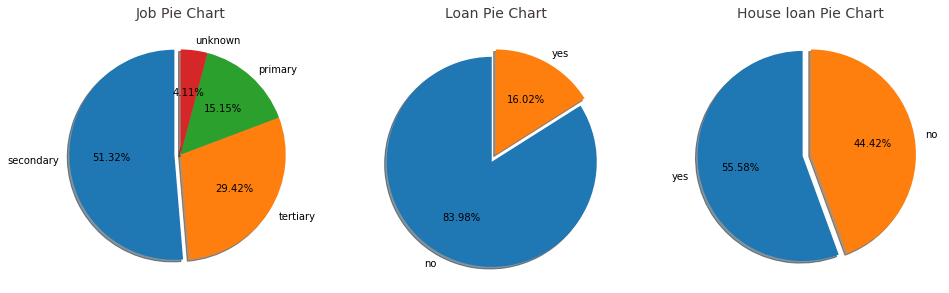
客户群体—教育程度、个人贷款、房贷
不同教育程度的用户,他们接受银行营销产品的效果也完全不同,从图中可以看出,用户主要还是以中等教育为主,占比达到了50%以上,其次是高等教育的人群,将近30%。再从个人贷款和房贷方面来分析,没有个人贷款的人数占大多数,可以理解,因为具有个人贷款的客户可能没有富于的钱用于订阅银行产品,因此,可以把主要客户群体放在无个人贷款群体上。而房贷的有无数量相当,因为买房也可以看做是一种特殊的投资,所以有无房贷差别不大。
data.education.value_counts()
secondary 23202
tertiary 13301
primary 6851
unknown 1857
Name: education, dtype: int64
data.loan.value_counts()
no 37967
yes 7244
Name: loan, dtype: int64
# 数据概况---教育程度、贷款与否
edu_pct = data.education.value_counts()*100/len(data)
loan_pct = data.loan.value_counts()*100/len(data)
housing_pct = data.housing.value_counts()*100/len(data)
fig, axes = plt.subplots(nrows = 1,ncols = 3,figsize = (16,6))
axes[0].pie(x=edu_pct,autopct='%1.2f%%',shadow = True,explode=(0.06,0,0,0),startangle=90,labels = edu_pct.index)
axes[0].set_title('Job Pie Chart', fontdict={
'fontsize': 14, 'color':'#41393E'})
axes[1].pie(x=loan_pct,autopct='%1.2f%%',shadow = True,explode=(0.08,0),startangle=90,labels = loan_pct.index)
axes[1].set_title('Loan Pie Chart', fontdict={
'fontsize': 14,'color':'#41393E'})
axes[2].pie(x=housing_pct,autopct='%1.2f%%',shadow = True,explode=(0.08,0),startangle=90,labels = housing_pct.index)
axes[2].set_title('House loan Pie Chart', fontdict={
'fontsize': 14,'color':'#41393E'})
plt.show()
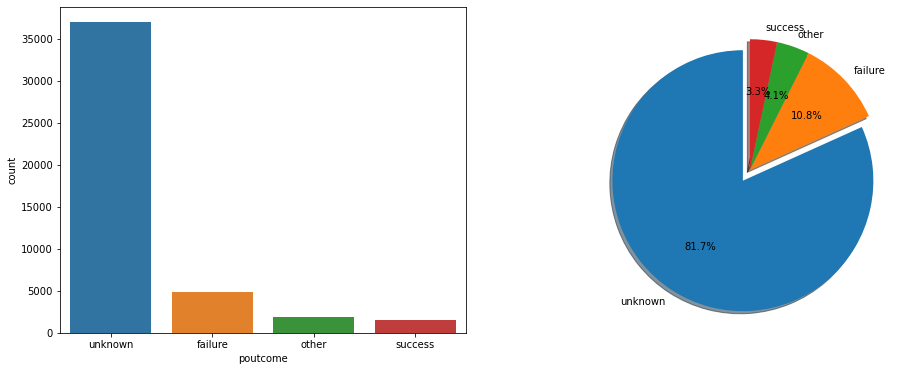
前次活动数据分析
从下饼图和柱状图数据可以看出,绝大部分用户在上次活动中是unkonwn,成功的人数是最少的,间接说明了潜在用户群体庞大。
# 数据概况---前一次活动结果
precome_pct = data.poutcome.value_counts()*100/len(data)
fig, axes = plt.subplots(nrows = 1,ncols = 2,figsize = (16,6))
sns.countplot(x = "poutcome", data = data, order = data.poutcome.value_counts().index, ax = axes[0])
axes[1].pie(x = precome_pct, autopct = '%1.1f%%',shadow = True,explode=(0.1,0,0,0),startangle=90,labels = precome_pct.index)
plt.show()
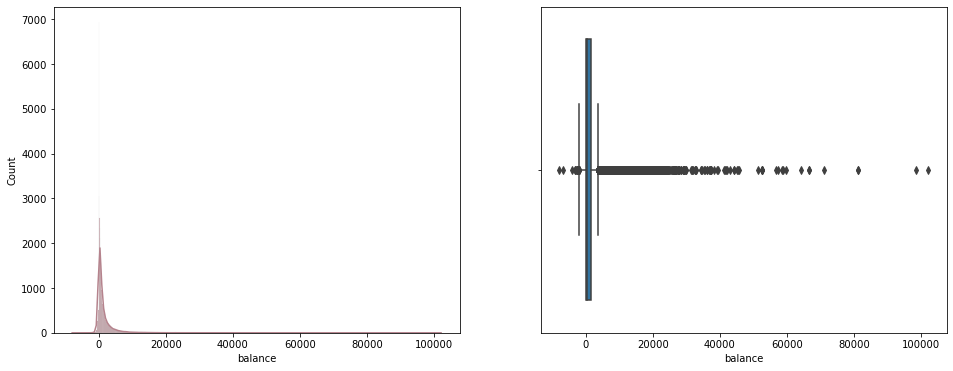
年余额分析
存款也是银行的主要业务之一,可以看到客户主要年余额峰值在1000-2000欧元左右,还有少部分人年余额超过10000欧元以上,由此可见,用户的贫富差距还是挺大的,大量财富掌握在少数人手中。还有极少部分人余额是负值,推断应该是信誉极差的用户。
Q1,Q3 = np.percentile(data.balance,[25,75])
IQR = Q3 - Q1
Q1,Q3,IQR
(72.0, 1428.0, 1356.0)
# 数据概况---存款信息
fig, axes = plt.subplots(nrows = 1,ncols = 2,figsize = (16,6))
sns.histplot(data=data, x='balance', kde=True, color='#b5838d', ax=axes[0])
sns.boxplot(x = data.balance, ax = axes[1])
plt.show()
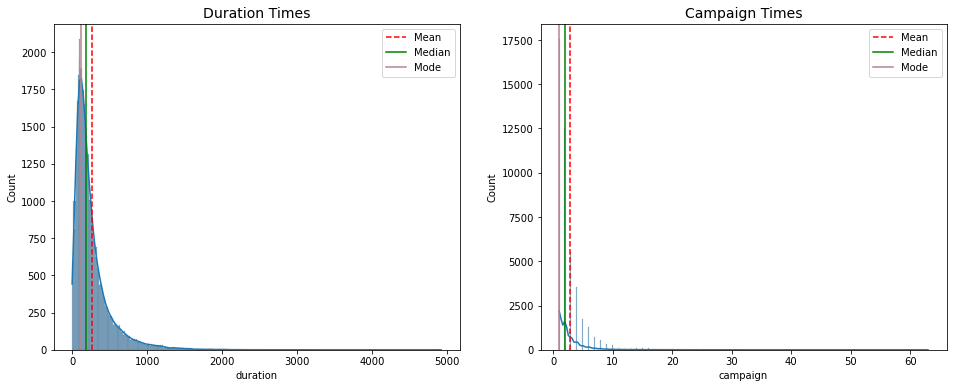
最后通话时长及活动联系次数分析
一般来说,营销产品还是取决于销售人员的推销效果,为此做出kde分布图。可以看到绝大部分用户通话时长在1000s以内,通话次数在10次以内,但是还存在通话时长超过1小时,通话次数超过60次的情况,一般存在三种情况:尊贵的会员、难缠的用户、老年人理解较差,可以适当减少这部分情况的发生概率,将更多数时间花在更有潜力的用户群体身上。
# 数据概况---通话时长及活动联系次数
fig, axes = plt.subplots(nrows = 1,ncols = 2,figsize = (16,6))
# 通话时间
mean_dura = data.duration.mean()
median_dura = data.duration.median()
mode_dura = data.duration.mode().values[0]
# 联系次数
mean_camp = data.campaign.mean()
median_camp = data.campaign.median()
mode_camp = data.campaign.mode().values[0]
sns.histplot(data = data, x = data.duration, kde = True, ax = axes[0])
axes[0].set_title('Duration Times', fontdict={
'fontsize': 14})
axes[0].axvline(mean_dura, color='r', linestyle='--', label="Mean")
axes[0].axvline(median_dura, color='g', linestyle='-', label="Median")
axes[0].axvline(mode_dura, color='#b5838d', linestyle='-', label="Mode")
axes[0].legend()
sns.histplot(data = data, x = data.campaign, kde = True, ax = axes[1])
axes[1].set_title('Campaign Times', fontdict={
'fontsize': 14})
axes[1].axvline(mean_camp, color='r', linestyle='--', label="Mean")
axes[1].axvline(median_camp, color='g', linestyle='-', label="Median")
axes[1].axvline(mode_camp, color='#b5838d', linestyle='-', label="Mode")
axes[1].legend()
plt.show()
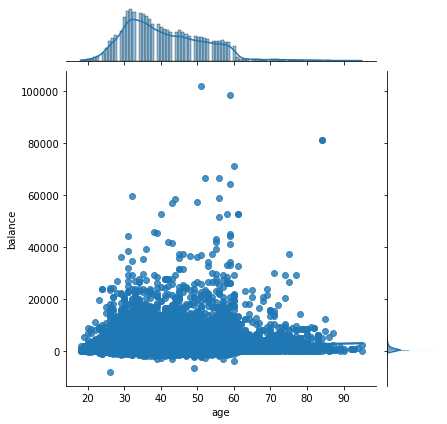
影响因素分析
年龄与存款的联系
不同年龄段对存款的需求不同。我做出下联合分布图,并指定类型为回归分析,我们发现年存款在2000欧元左右的人数最多,并且各个年龄段的都有,主要集中在30-60岁之间,60岁以上的选择存款的人数相对较少,并且可以依稀看出置信区间应该也是在2000-3000欧元左右。
# 存款和年龄之间的关系
sns.jointplot(x="age", y="balance", data=data,kind = "reg")
plt.show()
年龄、存款、订购银行产品意愿
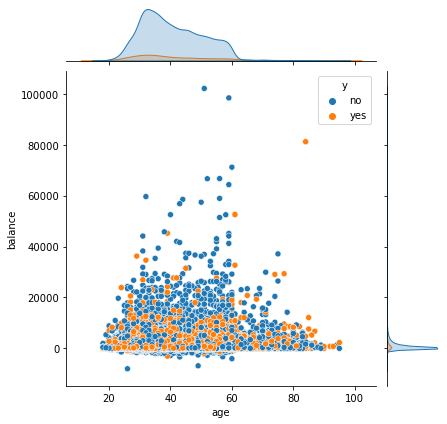
我们使用联合分布图将订购产品意愿作为核密度图分类,可以看出三者之间的关系,发现愿意订购银行产品的主要是30-40岁之间,存款20000欧元以内的,其中还有存款为负数的,应该注意他们的信用情况,避免不必要的损失;并且,绝大部分人还是不愿意订购银行产品,应该加强产品质量,提高优惠力度,收拢客户。
# 存款和年龄是否影响人们订购银行产品
sns.jointplot(x="age", y="balance",hue = "y",data=data)
plt.show()
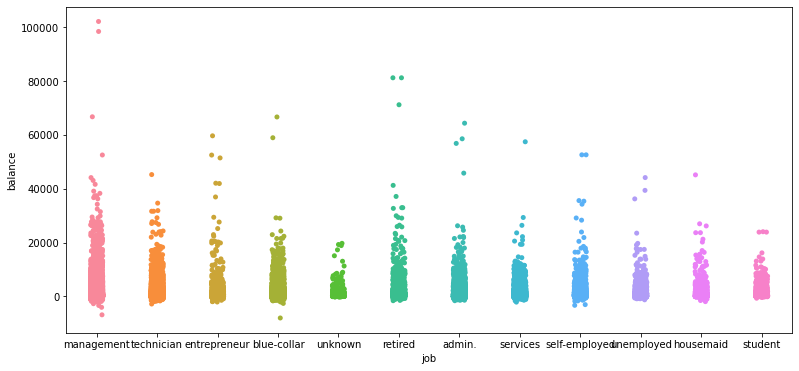
职业分析
不同职业对银行业务需求不同。我们先对不同职业的存款情况进行总体分析,然后在对其中前三个订阅银行产品的人数较多的职业进行分析,因为那是我们的主要客户。
职业与存款
由于职业是分类类型数据,所以我们采用分类散点图进行分析,从散点图可以看出管理者、技术人员、蓝领、退休者四个职业类型的工作人员存款人数较多,而管理者还有存款超10万欧元的人数,而未知类型的工作类型者人数最少。
# 工作和存款的关系
plt.figure(figsize = (13,6))
sns.stripplot(x = data.job, y = data.balance)
plt.show()
我们使用箱线图将存款人数前五的工作类型进行展示分析,发现他们都有存款金额超过箱线图上限的,但是管理者职位的人员相对较多,金额大者也更加密集,我们还发现了只有行政人员并没有下限异常的数值。
plt.figure(figsize = (12,6))
top_jobs = (data.job.value_counts().sort_values(ascending=False).head(5).index.values)
sns.boxplot(y="job", x="balance", data=data[data.job.isin(top_jobs)], orient="h")
plt.show()

职业与银行订阅产品
我们发现在订阅银行产品的各个职业中,管理者、技术人员和蓝领三种类型的工作人员人数最多,而unknown、客房服务员和企业家三种类型工作人员最少,下面我们将对订阅银行产品人数前三的职业进行分析,确定我们主要用户群体。
# 工作对订购银行产品的影响
plt.figure(figsize = (10,6))
sns.countplot(data = data,y = data.job,hue = data.y,orient = "h",order = data.job.value_counts().index)
plt.show()

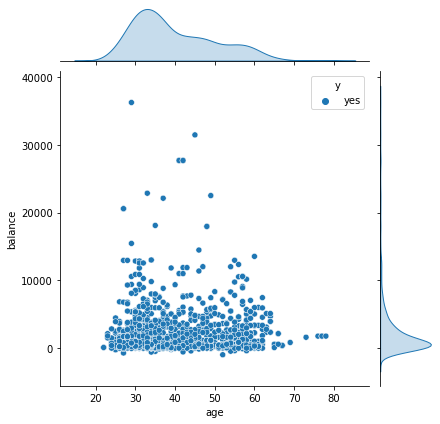
职业分析—管理者
可以从下面直方图看出,管理者婚姻状态大部分是已婚或者单身,他们的绝大部分是接受过高等教育的人群,并且在订购银行产品的管理者人群中,他们集中分布在20-60岁之间,其中30-40岁分布最密集,因此下次活动推广时,可以优先寻找接受过高等教育的单身或者已婚,年龄在30-40岁的管理者,他们更有可能会订购我们的产品。
# 分析职业---管理员
manage = data[(data["job"] == "management")]
manage_yes = manage[(manage["y"] == "yes")]
fig, axes = plt.subplots(nrows = 1,ncols = 2,figsize = (16,6))
sns.histplot(manage_yes["marital"],ax = axes[0])
sns.histplot(manage_yes["education"],ax = axes[1])
plt.show()
sns.jointplot(x = "age", y = "balance",hue = "y",data = manage_yes)
plt.show()
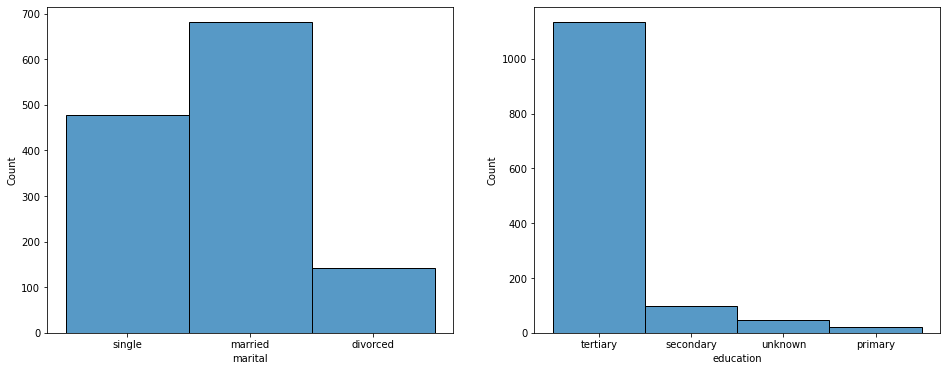
职业分析—技术人员
从下面的联合分布图和直方图可以看出,技术人员职业类型与管理者特征相似,大多都是已婚或者单身状态,订购银行产品的人群集中分布在20-60岁之间,其中30-40岁人群最为集中,不同的是,技术人员更多的学历是中等教育,其次是高等教育,他们接触到的社会层次可能没有那么高,也是银行营销策略的主要群体之一。
# 分析职业---技术人员
tech = data[(data["job"] == "technician")]
tech_yes = tech[(tech["y"] == "yes")]
fig, axes = plt.subplots(nrows = 1,ncols = 2,figsize = (16,6))
sns.histplot(tech_yes["marital"],ax = axes[0])
sns.histplot(tech_yes["education"],ax = axes[1])
plt.show()
sns.jointplot(x = "age", y = "balance",hue = "y",data = tech_yes)
plt.show()
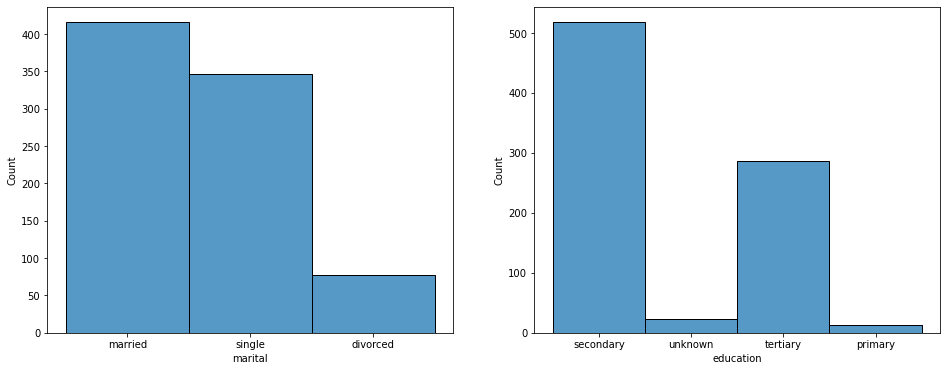
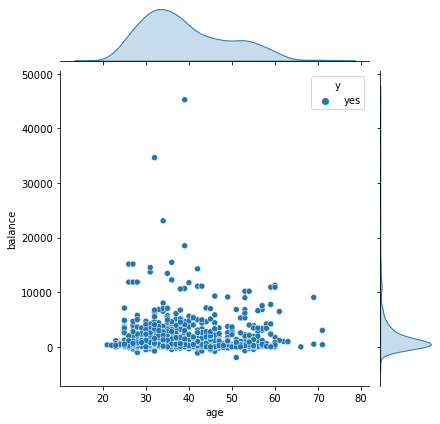
职业分析 —蓝领
蓝领职业特征与上面两者相似,但教育也有很大一部分是初等教育阶段,年龄分布相对来说比较松散,没有管理者和技术人员职业那么集中。
# 分析职业---蓝领
bc = data[(data["job"] == "blue-collar")]
bc_yes = bc[(bc["y"] == "yes")]
fig, axes = plt.subplots(nrows = 1,ncols = 2,figsize = (16,6))
sns.histplot(bc_yes["marital"],ax = axes[0])
sns.histplot(bc_yes["education"],ax = axes[1])
plt.show()
sns.jointplot(x = "age", y = "balance",hue = "y",data = bc_yes)
plt.show()
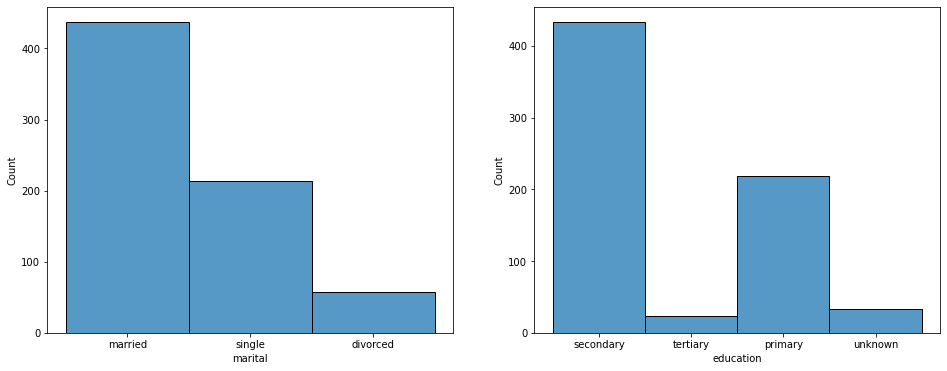
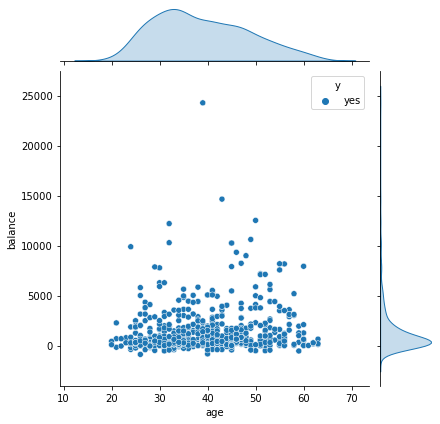
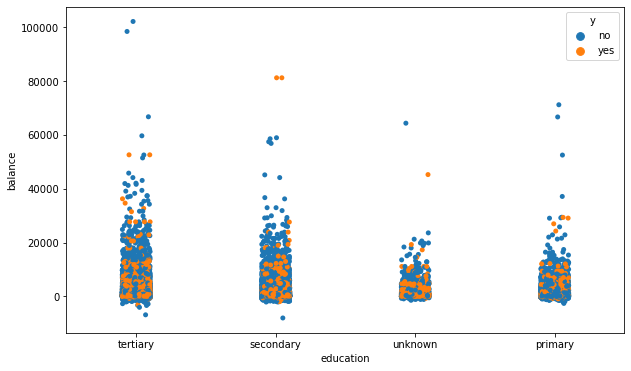
教育水平、存款及订购银行产品
无论是存款、贷款还是订阅产品,跟一个人接收的教育程度都息息相关,所以我们分别使用散点图和联合分布图对人群教育程度进行分析。
散点图
可以看到接受过高等教育和中等教育的人群,无论在存款金额还是在订阅银行产品都有巨大的优势,但值得注意的是,unknown订阅产品的人数也比较多,需要跟进他们的信息,提供更好的服务,留下潜在客户。
# 教育水平和存款及订购银行产品的关系
plt.figure(figsize = (10,6))
sns.stripplot(x = data.education, y = data.balance, hue = data.y)
plt.show()
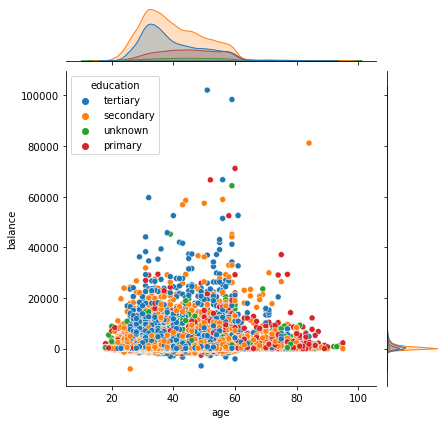
 联合分布图
联合分布图
我们以接收的教育程度作为分类,具体的分析出他们所处的年龄段和存款多少,可以发现,绝大部分人的学历都是中等教育和高等教育,其中接收中等教育的人群是最多的,他们的年龄段都集中在20-60岁左右,顶峰在30-40岁之间,存款一般在20000欧元以下。
# 存款、教育和年龄三者的关系
sns.jointplot(x = "age", y = "balance", hue = "education", data = data)
plt.show()
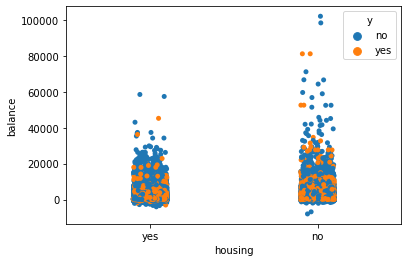
房子贷款、存款和订购银行产品
我们探索房贷会不会也是影响银行主要业务的因素之一。可以发现有无房贷与银行存款和订阅产品并无太大关系,他们的数量占比相当。
# 房子贷款和存款及订购银行产品的关系
sns.stripplot(x = data.housing, y = data.balance, hue = data.y)
plt.show()
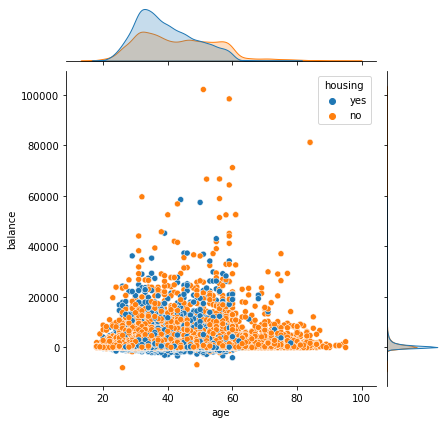
sns.jointplot(x = "age", y = "balance",hue = "housing",data = data)
plt.show()
个人贷款
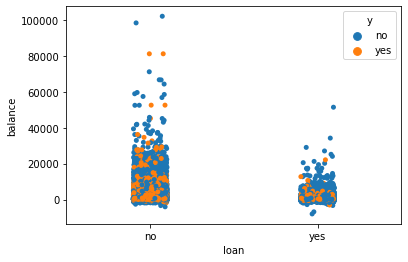
一个人经济状况也会影响他们对银行业务的支持程度。我们可以发现没有个人贷款的人群他们更愿意订购银行产品,并且存款相对来说更多,所以可以把主要关注对象放在没有个人贷款的人群上
# 个人贷款
sns.stripplot(x = "loan", y = "balance", hue = "y",data = data)
sns.jointplot(x ="age" , y = "balance",hue = "loan",data = data)
plt.show()
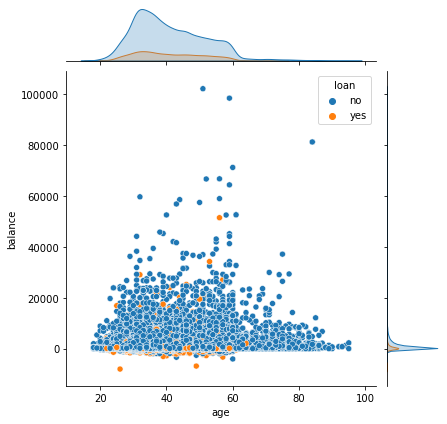
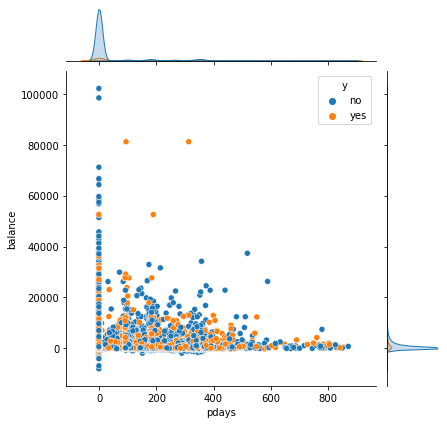
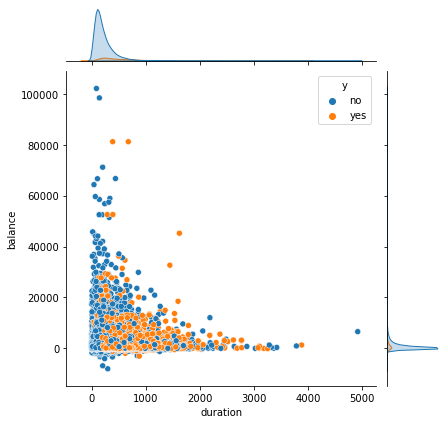
最后联系日距今时长和通话时长
推销手段和服务态度也有可能会影响客户的决定。可以看到最后联系日距今天数对于客户的影响不大,而通话时间在1000s左右,客户更加愿意订阅银行产品,所以应该注意通话时间,既要保证向客户介绍完全,时间又不能太长,1000s左右最佳。
# 上次联系时间
sns.jointplot(x = "pdays", y = "balance",hue = "y",data = data)
sns.jointplot(x="duration", y="balance", hue = "y", data=data)
plt.show()
多个数字变量分布关系
# 数字类型分析
sns.pairplot(data = data[["age", "balance", "duration", "campaign", "y"]], hue = 'y')
plt.show()
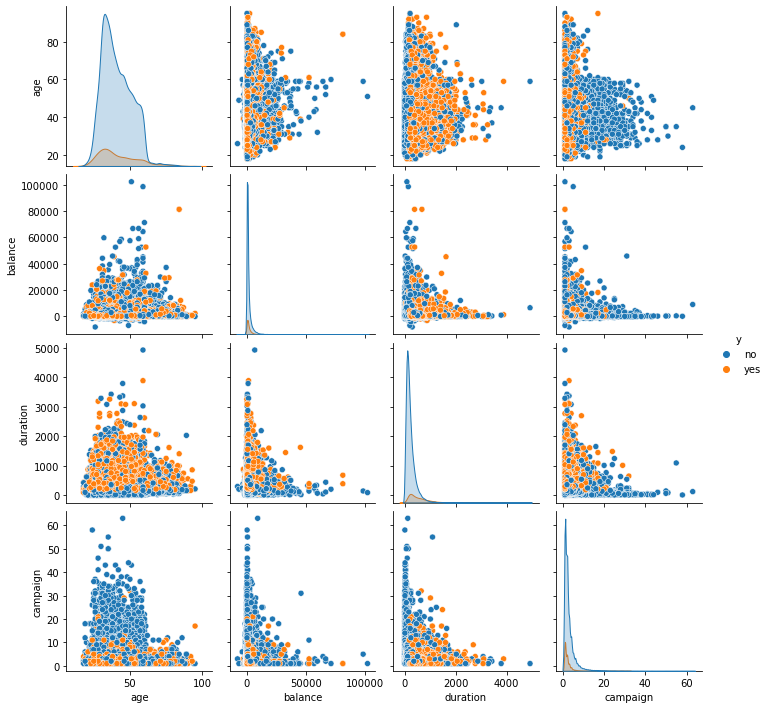
分析总结
经过上述分析,为了加强客户群体对银行的业务的支持力度,增加客户订阅银行相关产品的概率,他们应该具备以下一些特征:
- 首先应该选择管理者、技术人员、蓝领、行政人员这几类职业的工作人员,他们更有可能加入银行业务
- 其次,应该在这些职业中重点关注高等教育和中等教育的人群
- 第三,他们的婚姻状态应该是已婚或者未婚,这两个婚姻状态在订购银行业务占比最高
- 他们的年龄主要分布在20-60岁,分布最密集的是30-40岁的区间
- 他们最好没有个人贷款,至于房贷,那是无所谓的,因为买房也类似一种投资
- 营销活动的通话时间最好控制在1000s之内