//此文档的目的是帮助更多初学Python的Programmers少造轮子,致力于顺藤摸瓜。因水平所限,如有缺漏以及不严谨之处,请各位多多指教。
//任何人都可以轻而易举地掌握DataFrame。你所需要的只是一个脑子,和有记事本程序的电脑。
什么是DataFrame?
首先给出官网的定义,是不是有点眼熟?
没错,它就是来源于大名鼎鼎pandas库的内建方法。

首先我们先搞清楚它是做什么的?在入门阶段,我们简单把它理解为一个表格型数据结构。
它含有一组有序的index,大致可看成共享同一个index的series集合。
>>> d = {'col1': [1, 2], 'col2': [3, 4]}
>>> df = pd.DataFrame(data=d)
>>> df
col1 col2
0 1 3
1 2 4data : numpy数组,字典或DataFrame
字典可以包括序列,数组,或长得像列表的元素。
index : 数组的列标,如上:[0,1]
如果未指定下标,则采用默认下标。
columns : 数组的行标,如上:[col1,col2]
如果未指定行标,则采用默认行标。
dtype : 强制性数据类型
只能有一种哦,也可以空着。
copy : 布尔值,默认情况下是FALSE
Copy data from inputs. Only affects DataFrame / 2d ndarray input
到这里,你就已经入门了!但如果你想继续了解一些属性,看下面吧:
T |
转置索引和列。 |
at |
访问行/列标签对的单个值。 |
axes |
返回表示DataFrame轴的列表。 |
blocks |
(已弃用)as_blocks()的内部属性,属性同义词 |
columns |
DataFrame的列标签。 |
dtypes |
返回DataFrame中的dtypes。 |
empty |
指示DataFrame是否为空。 |
ftypes |
返回DataFrame中的ftypes(稀疏/密集和dtype的指示)。 |
iat |
按整数位置访问行/列对的单个值。 |
iloc |
纯粹基于整数位置的索引,用于按位置选择。 |
index |
DataFrame的索引(行标签)。 |
ix |
主要基于标签位置的索引器,具有整数位置回退。 |
loc |
通过标签或布尔数组访问一组行和列。 |
ndim |
返回表示轴/数组维数的int。 |
shape |
返回表示DataFrame维度的元组。 |
size |
返回一个int,表示此对象中的元素数。 |
style |
返回Styler对象的属性,该对象包含用于为DataFrame构建样式化HTML表示的方法。 |
values |
返回DataFrame的Numpy表示。 |
既然有了关键字,那肯定要被用到方法(Function)里:
篇幅限制,这里只提到一些比较常用的方法。
abs() |
返回具有每个元素的绝对数值的Series / DataFrame。 |
add(其他[,轴,级别,fill_value]) |
添加数据帧和其他元素(二元运算符添加)。 |
add_prefix(字首) |
带有字符串前缀的前缀标签。 |
add_suffix(后缀) |
带有字符串后缀的后缀标签。 |
agg(func [,轴]) |
使用指定轴上的一个或多个操作进行聚合。 |
aggregate(func [,轴]) |
使用指定轴上的一个或多个操作进行聚合。 |
align(其他[,join,axis,level,copy,...]) |
使用指定的每个轴索引的连接方法将轴上的两个对象对齐 |
all([轴,bool_only,skipna,等级]) |
返回是否所有元素都是True,可能是在轴上。 |
any([轴,bool_only,skipna,等级]) |
返回任何元素在请求的轴上是否为True。 |
append(其他[,ignore_index,...]) |
将其他行附加到此帧的末尾,返回一个新对象。 |
apply(func [,axis,broadcast,raw,reduce,...]) |
沿DataFrame的轴应用函数。 |
applymap(FUNC) |
将函数元素应用于Dataframe。 |
as_blocks([复制]) |
(已弃用)将帧转换为dtype - >构造函数类型的dict,每个类型都具有同类dtype。 |
as_matrix([列]) |
(DEPRECATED)将帧转换为Numpy数组表示。 |
asfreq(freq [,方法,how,normalize,...]) |
将TimeSeries转换为指定的频率。 |
asof(其中[,子集]) |
获取没有任何NaN的最后一行(或者在没有NaN的情况下考虑仅使用DataFrame情况下的列子集的最后一行) |
assign(** kwargs) |
将新列分配给DataFrame,返回一个新对象(副本),并将新列添加到原始列中。 |
astype(dtype [,copy,errors]) |
将pandas对象转换为指定的dtype dtype。 |
现在,尝试写一个简单的DataFrame?
举个例子,建立几款潮品笔记本的价格列表如下。
import pandas as pd#DataFrame来源于此
import numpy as np#因为numpy的数组比较好用,所以我们用np的数组方法
data=np.array([('MacBook',10200),('XPS15',15800),('Surface',6400)])#建立一个np的数组,建立一个“关键词-价格对”
frame=pd.DataFrame(data,index=range(1,4),columns=['name','price'])#建立一个以data为源的DataFrame,其行标为name和price,列标为1~3
print(frame)直接复制这段代码于Python的IDLE,Python.org下载就可以。
如果你和我一样使用macOS,打开Terminal,输入Python并回车。
将以上代码键入即可运行~
使用Windows的朋友可以到Python.org下载一个IDLE,
同样的键入代码运行即可。
你会得到这样的运行结果:
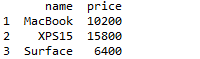
可以输入frame.index,或frame.columns快速获取列标与行标。
接下来揭示Python的效率精妙之处:
如果你想找出所有的价格,只需要键入 frame.price ,即可得到所有的价格。
同样的,只需要输入frame.name,即可得到所有的名字。
如果你想把name列全部改为 ‘SCAR~’,键入 frame['name']='SCAR~' 回车即可。
假设你有一个几万人的公司,有天想整理一个名单列表。如果用EXCEL,一般的电脑估计操作起来会很卡。
而你需要做的只是在命令行里输入:
company.name
回车即可~
DataFrame还有很多奇妙的函数,上面列出的部分。实际上是一个庞大的函数集合体。
如果你开始对Python感兴趣,切记不要造轮子~很多方法,前人已经实现,调用就可以了。(笔者平均每天造5个轮子cry~)
意犹未尽,不够深度?
下篇文章介绍DataFrame进阶教程,彻底吃透DataFrame库。