前几节我们大概的介绍了学习算法,即GIS和IIS的算法,这两个算法在最大熵模型中讲的比较详细,想要深入理解这两个算法,需要你理解动态规划算法。这里的条件随机场实际上是根据最大熵模型的思想过来的,因为通过前面我们可以看出CRF算法的目标公式就是按照最大熵算法构造而来的,不同的是特征函数的选取不同,但是都是大同小异,因此这里大家需要对最大熵模型深入理解,而条件随机场是根据隐马尔可夫过来的,在他的基础上加上概率图模型和团的思想简单来讲就是把可观测符号的独立性假设去掉了,同时引入判断当前的转态和前一个状态有关,这是符合语言特性的,因此,他们的关系大家应该搞清楚,只有这样我们在遇到实际问题时才能辨别出问题是适合哪个算法模型,或者问题出在哪里,所有这一部分很重要,本节将详细讲解CRF是如何预测的。
条件随机场的预测算法
我们先把条件随机场的目标公式拿过来,首先是定义式,然后是简化向量式和矩阵式,具体定义请参考前文或者李航的书:
定义式:

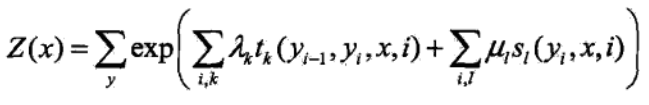
简化向量式:
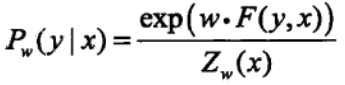

矩阵式:
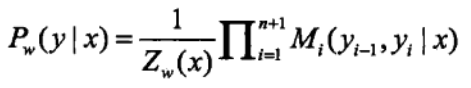
![]()
上面都是条件随机场的目标函数,定义式有两个参数,分别是对转移状态和位置的特征的权值参数,简化向量式是为了方便计算把两个参数合二为一了,原理还是一样的,矩阵式是为了适合编程进行的调整,其中我们通过最大熵模型的求解算法IIS进行求解
我们都知道隐马尔可夫的三个基本问题,其中第二个问题是通过可观测的信号进行反推HMM的状态转移概率,在语音识别中,我们知道语音的拼音了,让我们求对应的汉字,这其实是标注问题,即我知道了一个形式,使用另外一种形式以最大概率的进行标记他,因为我们的条件随机场就是根据HMM的缺点改进的,因此他也是解决标注问题, 即我们在输入语音向量x的前提下,以最大的概率使用汉字进行标注他就是上面的简化向量式,这就是语音识别了,即我知道了拼音序列,反推他对应的汉字的序列。那么也就是说以后只要我们遇到标注性的问题都可以通过CRF进行求解了。下面我们就来看看他说如何标注的。

上式就是我们的目标函数了,也是我们上面的解释的数学化描述,就是在这个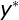

那么上面的都代表什么意思呢?
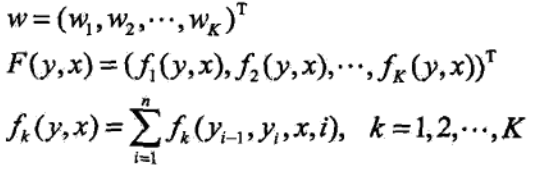
这里就是不详细解释了,把其都写成向量形式, 这些在前面都讲解了,不懂的请好好看看前面 的基础,那么我们为了使用维特比算法, 这里还需要把最优化目标表达式改一下,如下:
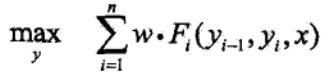
其中:
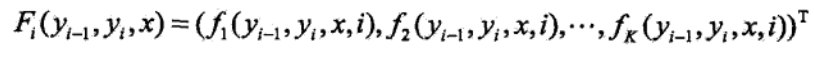
其实是一样的,这里大家别迷惑了,我们继续:
现在我们需要求解这个概率,这个概率可以求解吗?当然可以求解了,但是这个使用遍历的方法不可行,因为什么呢?因为你只要给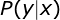
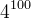
维特比算法
维特比算法思想是基于动态规划的,这里我会稍微深入的讲解一下动态规划思想,尽量让大家能看明白,首先我们使用标注问题进行讲解,现在这里和大家说一下什么是分词,这里使用一个例子进行讲解:

上式就是对一个句子进行分词了,这里的S(single,单个的意思) 、B是(begin,开始)、M(more ,更多)、E(end结束),这里我们是怎么标号的呢,上面是人为正确划分的,这里我们把单个的词使用S来代表,两个字以上的组合词分别使用B、M、E来表示,这样,就把汉字通过符号来表示了。那么我们通过符号就可以把分词问题转化为标注问题了。我们在举一个例子:

我们假设已经标号了,那么我们通过符号就可以表示已经分好的词了,上面虽然分的不对,但是功能已经实现了,所以只要知道这些符号的组合基本上就可以分词了,我们知道分词后就会知道一句话每个字都是一个划分标志,又因为每个字都有四个划分选项即S\B\M\E,下面我们结合图进行讲解:

假设这里有一句话是“我喜欢北京天安门“,现在我们需要对此进行标注,这里我们以每个字为间隔为例进行标注,总共有四种标注即SBME,因此这里只有一条线是正确的,如上图的红线走势就是正确的,现在我们来看看他的计算量,如果使用遍历的方法,有多少种可能呢?答案是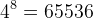

首先我们是知道字与字之间的标注概率的,例如喜欢,从“喜”到“欢”的概率很大,说明他们是一个词这是知道的,也就说说明我们知道上图的每一步的概率,类红线s到B的概率是知道的,这些概率都是知道的,怎么来的呢?根据语料库计算出来的,现在的问题是我们如何知道最正确的标注路径呢?我么你可以这样做,我们可以把两个两个看为一个单元,如上图的红色虚线框,此时我么你可以计算这个红色框的对应标注的最大概率,然后把红色框看为一个整体和后面的在进行求解,如上图的紫色部分,同时也记录标注的最大概率(此时的概率是前面红色框的概率与到达三角形的概率的乘积),然后在把其看为一个整体,然后在加入另外一列就这样我们每一次都会得到概率最大的,然后在和后面的概率累乘,这是简化版的动态规划思想。如下图:

下面我们就通过公式进行描述,下面我们在通过公式讲解,大家应该明白了,下面开始:
首先求出位置1的各个标记,如下图这里的j就是可选的四个标记即SBME了,这就相当于我们的红色虚线了的概率了,这个大家应该能理解吧。
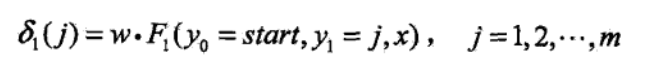
一般地,由递推公式,求出到位置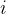
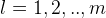
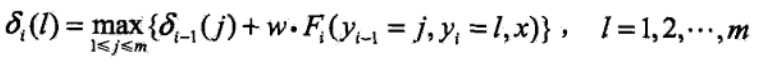
这里他直接是第i个了,根据上面的理解大家应该可以看懂吧,看不懂的请留言吧。
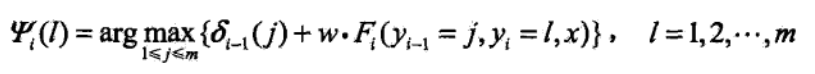
上式是记录路径的。
直到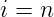
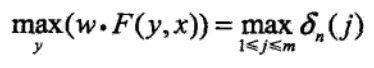
及最优路径的终点

由此最优路径终点返回,
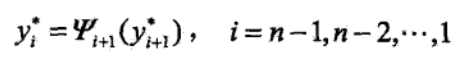
求得最优路径![]()
直接截图了,这里大家需要深入理解呀

好了,本节结束了,大家好好思考维特比算法,这里的算法和动态规划有点不同,这里的更简单点,等我开算法专栏在详细讲解动态规划,那时大家在看一定会深入理解的,好了,本节结束,下一节简单介绍自然语言处理的一些细节方面的内容,如分词、标注等等内容,下一节将开始分词。