上一节详解的阐述了条件随机场的定义和简单的学习算法推倒,这里不懂的前翻看前两节的博客,这里不再赘述,本节将主要求期望的问题,为什么要求解期望?本节主要参考的内容是一篇论文和李航的书,论文是《Conditional Random Fields: An Introduction》 Hanna M. Wallach February 24, 2004,这是一篇综述论文,里面也介绍了求模型期望问题,下面我们详解讲解对模型求期望的原因,李航书的是11.3节的内容。下面开始:
期望计算
假如我们现在有一个算法模型,里面有待求参数,我们通过样本进行了训练获得了参数的值,这时候我们得到了参,这个算法模型也就确定下来了,现在的问题是我不知道这个模型是不是正确的,我有点怀疑这个模型,怎么才能知道这个模型是不是正确的呢?例如我们上一节说的IIS算法,这个算法一定是是正确的吗?收敛能得到保证吗?能否达到我们的与其效果呢?怎么做呢?
其实很简单,这里我们可以把求得的参数代入模型,那么这个模型就会唯一的确定了下来,通过这个模型我们可以计算出这个模型的期望,然后再通过训练样本进行计算样本的期望,观察两个期望是否相等或者很接近,如果相等或者接近就说明这个模型是有效的,反之是无效了,那么问题来了,为什么期望值相等或者接近就是有效的呢?针对条件随机场来说是因为我们在设计模型时有一个条件,大家是否还记得:
![]()
约束条件,对,我们当初建立模型的时候就是在满足约束条件成立的情况下进行建立的,因此我们可以通过期望进行检验,如果两个期望很接近说明没问题,反之,这个模型可能就错了,下面我们来详细的看看,模型期望的计算过程:
前项--后向算法
对每个指标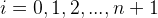
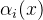

递推公式为:

又可以表示为:
![]()
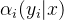
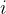
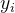
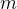
同样,对每个指标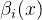

![]()
又可以表示:
![]()
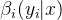
到
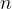
由前项和后向向量定义不难得到:
![]()
其中“1” 是m维向量。
上面的公式和维特比算法很类似,这里需要大家对动态规划有一个清晰的深入理解,尤其是递推公式才能想通,这里大家需要好好理解一下动态规划。
概率计算
按照前后向向量的定义,很容易计算标记序列在位置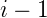
和


其中:
![]()
这里不解释了,很简单,很容易理解,前提是你需要理解什么是动态规划。
期望计算
下面我们就来看看如何计算期望:
通过上面的概率可以分别计算出联合概率密度即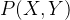
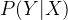
特征函数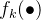

其中:
![]()
假设经验分布的联合概率分布为

这里大家需要搞懂上面的公式是如何递推的,其实就是把前两节的公式拿过来带进了就可以了,大家找到对应的公式,带进去即可求解,那么当我们计算出期望以后我们就可以就可以比较这两个期望的大小,然后进行对我们的建模是否正确可以给一个正确的评价,这里大家只需要知道计算期望值的原因是什么以及大概了解如何计算的,我们不需要深入理解,当我们实现算法时在深入研究即可,但是现在这些算法都已经实现了,如果我们需要在此基础上修改算法,则需要深入研究具体代码是如何实现的,这里大家只需了解过程既可,这一节就到这里,有点少,但是感觉挺重要的,下一节CRF的预测算法。