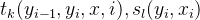上一节我们主要讲解了最大熵模型的原理,主要是解释了什么是最大熵,已经最大熵的背景知识,其实还是多建议大家读读论文,如果读英语有点难度,那就看李航的《统计学习方法》的最大熵模型和条件随机场,这本书的质量很高,本节主要讲一些条件随机场的背景知识,解释为什么需要引入条件随机场,废话不多说,下面开始:
首先讲条件随机场还需要从隐马尔可夫过来讲,我们都知道,隐马尔可夫过程是生成式模型,体现在哪里呢?这里大家应该知道什么是生成式模型,不懂的查看我的这篇文章,生成式模型最大的特点是求条件概率时是通过联合概率密度进行求解的,而判别式不是通过联合概率求解而是通过其他的方法进行求解。我们的HMM就是通过联合概率进行求解的,这里以第二个基本问题为例,即知道发射符号O,求其状态转移矩阵A,这里怎么求得呢?其实是通过发射矩阵B进行求解的,而B矩阵就是联合概率,其他问题也是这样的,因此B矩阵很重要,下面我们就总结一下HMM使用条件或者HMM的问题:
- HMM是生成式模型,需要给出状态与观察符号之间的联合概率分布,需要观察符号是可枚举的,并遍历所有可能的观察符号,工作量繁琐。
- 把观察符号割裂为互相独立的“原子”结构,无法体现句子中观察符号之间的依赖关系,生成式模型对输出的独立假设也显得牵强。
- 难以考虑除字(词)序以外的其它特征,例如“字母为大写”“包含阿拉伯数字”等
- 标注偏置问题,这个问题比仅仅存在HMM中,项最大熵模型、自动机等模型都存在这样的问题,下面通过例子讲解一下。
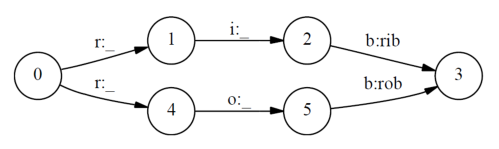
假如HMM标注单词rib和rob,假如正确的标注应该为[r/1],[i/2],[b/3]这是rib的正确标注,而[r/4],[o/5],[b/3]是rob的正确标注,那么现在我们分别来计算一下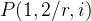
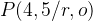


上式的p(2/i,1),p(5/0,4)等于1,因为一旦确定r的走向,后向的概率是百分之百,大家根据结果可以看到,这两个标注问题是否标注正确取决于p(1/r),p(4/r),而这两个概率和什么有关呢?和我们的训练语料出现1或者则4的多少有关,因此会出现错误。为了解决HMM存在的问题,我们引入了条件随机场的来进行解决上面的缺点,也因此解决了上面的问题,使的CRF的得到了广泛的使用,只要我们的问题可以转化为标注问题,我们就可以通过CRF进行解决,这个算法理解起来有点困难,不过我们只需要知道他的原理就可以了,以后使用可以直接调函数,既然是这样那我为什么还要学呢?因为知道他的原理将更有利与我们调参,下面我们就是开始进入CRF。
CRF
需要说明的是整个算法参考的是李航的《统计学习方法》,会详细讲解本人觉得难理解的地方。
大家都还记得隐马尔可夫的基本第二个问题吧,忘记的建议看我前几篇博客,通过可观察符号计算转态转移概率,如下图所示:
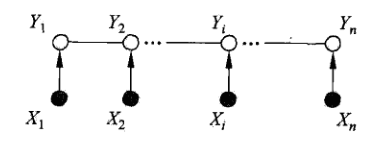
在HMM中我们假设发射符号是条件独立的,上图的发射符号是x,转态转移是Y,其实呢x假设独立很牵强,而在CRF中的定义下面的样子:
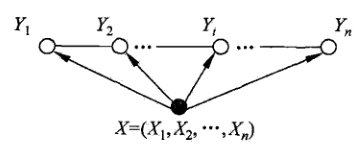
即每个发射符号都不是独立的,每个x都会影响Y,这是比较符合语言模型的,因为我们人类在说话时已经将一句话的意群都想到了,而不是一个字一个字的去想,上图就比较符合我们的语言思维,好,现在我们有了模型,关键是如何建立他们的联系呢?或者说是如何使用数学来表示他们呢?首先呢我们可以确定的是他应该是这个形式: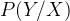
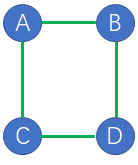
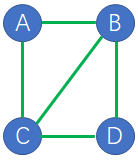
如上图的无向图,那么这里的概率图模型是什么意思呢?其实很简单,例如A的条件概率只和C和B有关,而和D无关,也就是说,某个点的条件概率只和他相邻的点有关和其他点无关,例如下式:
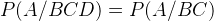
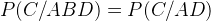
下面在简单的讲解一下什么是最大团:
其实很简单,我们先看定义如下:
定义:(团与最大团)无向图G中任何两个结点均有边连接的结点子集称为团(clique).若c是无向图G的一个团,并且不能再加进任何一个G的结点使其成为一个更大的团,则称此c为最大团(maximalclique).
上图有两个节点的团有5个基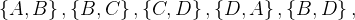
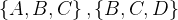
将概率无向图模型的联合概率分布表示为其最大团上的随机变量的函数的乘积形式的操作,称为概率无向图模型的因子分解(factorization).给定概率无向图模型,设其无向图为G,C为G上的最大团,表示C对应的随机变量,那么概率无向图模型的联合概率分布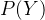
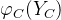

其中:z是归一化因子,如下所示:
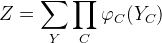
函数

概率无向图模型的因子分解由下述定理来保证,
定理:(Hammers1ey-Clifford定理)概率无向图模型的联合概率分布

其中
其中,C是无向图的最大团,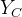
我们知道了什么是概率图模型已经什么是团和最大图,那么我们如何定义我们的模型呢?这里把CRF的图拿过来继续讲解:
我现在再来看看能看出什么门道呢?其实这就是我们上面说的概率和团嘛,其实就是他,那么我们就按照上面的进行构造模型即可,这里我直接构造好的模型拿过来讲解好了,如下:
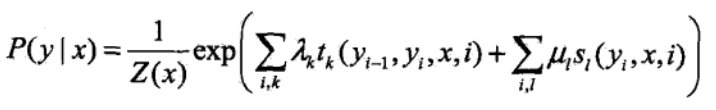
这里的定义大家不要想的太麻烦,其实很简单的,他就是一个势函数,只是上面的势函数E使用具体的形式来代替罢了,这里我们需要详细解释的是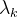
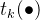
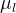
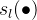
本来是连乘的,但是因为是指数连乘,所以指数就是相加了,下面我们解释一下上面的符号的意义,大家这里可以把