第一篇
理解条件随机场最好的办法就是用一个现实的例子来说明它。但是目前中文的条件随机场文章鲜有这样干的,可能写文章的人都是大牛,不屑于举例子吧。于是乎,我翻译了这篇文章。希望对其他伙伴有所帮助。
原文在这里[http://blog.echen.me/2012/01/03/introduction-to-conditional-random-fields/]
想直接看英文的朋友可以直接点进去了。我在翻译时并没有拘泥于原文,许多地方都加入了自己的理解,用学术点的话说就是意译。(画外音:装什么装,快点开始吧。)好的,下面开始翻译!
假设你有许多小明同学一天内不同时段的照片,从小明提裤子起床到脱裤子睡觉各个时间段都有(小明是照片控!)。现在的任务是对这些照片进行分类。比如有的照片是吃饭,那就给它打上吃饭的标签;有的照片是跑步时拍的,那就打上跑步的标签;有的照片是开会时拍的,那就打上开会的标签。问题来了,你准备怎么干?
一个简单直观的办法就是,不管这些照片之间的时间顺序,想办法训练出一个多元分类器。就是用一些打好标签的照片作为训练数据,训练出一个模型,直接根据照片的特征来分类。例如,如果照片是早上6:00拍的,且画面是黑暗的,那就给它打上睡觉的标签;如果照片上有车,那就给它打上开车的标签。
这样可行吗?
乍一看可以!但实际上,由于我们忽略了这些照片之间的时间顺序这一重要信息,我们的分类器会有缺陷的。举个例子,假如有一张小明闭着嘴的照片,怎么分类?显然难以直接判断,需要参考闭嘴之前的照片,如果之前的照片显示小明在吃饭,那这个闭嘴的照片很可能是小明在咀嚼食物准备下咽,可以给它打上吃饭的标签;如果之前的照片显示小明在唱歌,那这个闭嘴的照片很可能是小明唱歌瞬间的抓拍,可以给它打上唱歌的标签。
所以,为了让我们的分类器能够有更好的表现,在为一张照片分类时,我们必须将与它相邻的照片的标签信息考虑进来。这——就是条件随机场(CRF)大显身手的地方!
从例子说起——词性标注问题
啥是词性标注问题?
非常简单的,就是给一个句子中的每个单词注明词性。比如这句话:“Bob drank coffee at Starbucks”,注明每个单词的词性后是这样的:“Bob (名词) drank(动词) coffee(名词) at(介词) Starbucks(名词)”。
下面,就用条件随机场来解决这个问题。
以上面的话为例,有5个单词,我们将:(名词,动词,名词,介词,名词)作为一个标注序列,称为l,可选的标注序列有很多种,比如l还可以是这样:(名词,动词,动词,介词,名词),我们要在这么多的可选标注序列中,挑选出一个最靠谱的作为我们对这句话的标注。
怎么判断一个标注序列靠谱不靠谱呢?
就我们上面展示的两个标注序列来说,第二个显然不如第一个靠谱,因为它把第二、第三个单词都标注成了动词,动词后面接动词,这在一个句子中通常是说不通的。
假如我们给每一个标注序列打分,打分越高代表这个标注序列越靠谱,我们至少可以说,凡是标注中出现了动词后面还是动词的标注序列,要给它负分!!
上面所说的动词后面还是动词就是一个特征函数,我们可以定义一个特征函数集合,用这个特征函数集合来为一个标注序列打分,并据此选出最靠谱的标注序列。也就是说,每一个特征函数都可以用来为一个标注序列评分,把集合中所有特征函数对同一个标注序列的评分综合起来,就是这个标注序列最终的评分值。
定义CRF中的特征函数
现在,我们正式地定义一下什么是CRF中的特征函数,所谓特征函数,就是这样的函数,它接受四个参数:
- 句子s(就是我们要标注词性的句子)
- i,用来表示句子s中第i个单词
- l_i,表示要评分的标注序列给第i个单词标注的词性
- l_i-1,表示要评分的标注序列给第i-1个单词标注的词性
它的输出值是0或者1,0表示要评分的标注序列不符合这个特征,1表示要评分的标注序列符合这个特征。
Note:这里,我们的特征函数仅仅依靠当前单词的标签和它前面的单词的标签对标注序列进行评判,这样建立的CRF也叫作线性链CRF,这是CRF中的一种简单情况。为简单起见,本文中我们仅考虑线性链CRF。
从特征函数到概率
定义好一组特征函数后,我们要给每个特征函数f_j赋予一个权重λ_j。现在,只要有一个句子s,有一个标注序列l,我们就可以利用前面定义的特征函数集来对l评分。

pic1.PNG
上式中有两个求和,外面的求和用来求每一个特征函数f_j评分值的和,里面的求和用来求句子中每个位置的单词的的特征值的和。
对这个分数进行指数化和标准化,我们就可以得到标注序列l的概率值p(l|s),如下所示:

pic2.PNG
几个特征函数的例子
前面我们已经举过特征函数的例子,下面我们再看几个具体的例子,帮助增强大家的感性认识。

pic3.PNG
当l_i是“副词”并且第i个单词以“ly”结尾时,我们就让f1 = 1,其他情况f1为0。不难想到,f1特征函数的权重λ1应当是正的。而且λ1越大,表示我们越倾向于采用那些把以“ly”结尾的单词标注为“副词”的标注序列

pic4.PNG
如果i=1,l_i=动词,并且句子s是以“?”结尾时,f2=1,其他情况f2=0。同样,λ2应当是正的,并且λ2越大,表示我们越倾向于采用那些把问句的第一个单词标注为“动词”的标注序列。

pic5.PNG
当l_i-1是介词,l_i是名词时,f3 = 1,其他情况f3=0。λ3也应当是正的,并且λ3越大,说明我们越认为介词后面应当跟一个名词。

pic6.PNG
如果l_i和l_i-1都是介词,那么f4等于1,其他情况f4=0。这里,我们应当可以想到λ4是负的,并且λ4的绝对值越大,表示我们越不认可介词后面还是介词的标注序列。
好了,一个条件随机场就这样建立起来了,让我们总结一下:
为了建一个条件随机场,我们首先要定义一个特征函数集,每个特征函数都以整个句子s,当前位置i,位置i和i-1的标签为输入。然后为每一个特征函数赋予一个权重,然后针对每一个标注序列l,对所有的特征函数加权求和,必要的话,可以把求和的值转化为一个概率值。
CRF与逻辑回归的比较
观察公式:

是不是有点逻辑回归的味道?
事实上,条件随机场是逻辑回归的序列化版本。逻辑回归是用于分类的对数线性模型,条件随机场是用于序列化标注的对数线性模型。
CRF与HMM的比较
对于词性标注问题,HMM模型也可以解决。HMM的思路是用生成办法,就是说,在已知要标注的句子s的情况下,去判断生成标注序列l的概率,如下所示:

pic7.PNG
这里:
p(l_i|l_i-1)是转移概率,比如,l_i-1是介词,l_i是名词,此时的p表示介词后面的词是名词的概率。
p(w_i|l_i)表示发射概率(emission probability),比如l_i是名词,w_i是单词“ball”,此时的p表示在是名词的状态下,是单词“ball”的概率。
那么,HMM和CRF怎么比较呢?
答案是:CRF比HMM要强大的多,它可以解决所有HMM能够解决的问题,并且还可以解决许多HMM解决不了的问题。事实上,我们可以对上面的HMM模型取对数,就变成下面这样:

pic8.PNG
我们把这个式子与CRF的式子进行比较:
pic1.PNG
不难发现,如果我们把第一个HMM式子中的log形式的概率看做是第二个CRF式子中的特征函数的权重的话,我们会发现,CRF和HMM具有相同的形式。
换句话说,我们可以构造一个CRF,使它与HMM的对数形式相同。怎么构造呢?
对于HMM中的每一个转移概率p(l_i=y|l_i-1=x),我们可以定义这样的一个特征函数:

pic9.PNG
该特征函数仅当l_i = y,l_i-1=x时才等于1。这个特征函数的权重如下:

pic10.PNG
同样的,对于HMM中的每一个发射概率,我们也都可以定义相应的特征函数,并让该特征函数的权重等于HMM中的log形式的发射概率。
用这些形式的特征函数和相应的权重计算出来的p(l|s)和对数形式的HMM模型几乎是一样的!
用一句话来说明HMM和CRF的关系就是这样:
每一个HMM模型都等价于某个CRF
每一个HMM模型都等价于某个CRF
每一个HMM模型都等价于某个CRF
但是,CRF要比HMM更加强大,原因主要有两点:
- CRF可以定义数量更多,种类更丰富的特征函数。HMM模型具有天然具有局部性,就是说,在HMM模型中,当前的单词只依赖于当前的标签,当前的标签只依赖于前一个标签。这样的局部性限制了HMM只能定义相应类型的特征函数,我们在上面也看到了。但是CRF却可以着眼于整个句子s定义更具有全局性的特征函数,如这个特征函数:
pic4.PNG
如果i=1,l_i=动词,并且句子s是以“?”结尾时,f2=1,其他情况f2=0。
- CRF可以使用任意的权重 将对数HMM模型看做CRF时,特征函数的权重由于是log形式的概率,所以都是小于等于0的,而且概率还要满足相应的限制,如

pic11.PNG
但在CRF中,每个特征函数的权重可以是任意值,没有这些限制。

第二篇
条件随机场(Conditional Random Fields, 以下简称CRF)是给定一组输入序列条件下另一组输出序列的条件概率分布模型,在自然语言处理中得到了广泛应用。本系列主要关注于CRF的特殊形式:线性链(Linear chain) CRF。本文关注与CRF的模型基础。
1.什么样的问题需要CRF模型
和HMM类似,在讨论CRF之前,我们来看看什么样的问题需要CRF模型。这里举一个简单的例子:
假设我们有Bob一天从早到晚的一系列照片,Bob想考考我们,要我们猜这一系列的每张照片对应的活动,比如: 工作的照片,吃饭的照片,唱歌的照片等等。一个比较直观的办法就是,我们找到Bob之前的日常生活的一系列照片,然后找Bob问清楚这些照片代表的活动标记,这样我们就可以用监督学习的方法来训练一个分类模型,比如逻辑回归,接着用模型去预测这一天的每张照片最可能的活动标记。
这种办法虽然是可行的,但是却忽略了一个重要的问题,就是这些照片之间的顺序其实是有很大的时间顺序关系的,而用上面的方法则会忽略这种关系。比如我们现在看到了一张Bob闭着嘴的照片,那么这张照片我们怎么标记Bob的活动呢?比较难去打标记。但是如果我们有Bob在这一张照片前一点点时间的照片的话,那么这张照片就好标记了。如果在时间序列上前一张的照片里Bob在吃饭,那么这张闭嘴的照片很有可能是在吃饭咀嚼。而如果在时间序列上前一张的照片里Bob在唱歌,那么这张闭嘴的照片很有可能是在唱歌。
为了让我们的分类器表现的更好,可以在标记数据的时候,可以考虑相邻数据的标记信息。这一点,是普通的分类器难以做到的。而这一块,也是CRF比较擅长的地方。
在实际应用中,自然语言处理中的词性标注(POS Tagging)就是非常适合CRF使用的地方。词性标注的目标是给出一个句子中每个词的词性(名词,动词,形容词等)。而这些词的词性往往和上下文的词的词性有关,因此,使用CRF来处理是很适合的,当然CRF不是唯一的选择,也有很多其他的词性标注方法。
2. 从随机场到马尔科夫随机场
首先,我们来看看什么是随机场。“随机场”的名字取的很玄乎,其实理解起来不难。随机场是由若干个位置组成的整体,当给每一个位置中按照某种分布随机赋予一个值之后,其全体就叫做随机场。还是举词性标注的例子:假如我们有一个十个词形成的句子需要做词性标注。这十个词每个词的词性可以在我们已知的词性集合(名词,动词...)中去选择。当我们为每个词选择完词性后,这就形成了一个随机场。
了解了随机场,我们再来看看马尔科夫随机场。马尔科夫随机场是随机场的特例,它假设随机场中某一个位置的赋值仅仅与和它相邻的位置的赋值有关,和与其不相邻的位置的赋值无关。继续举十个词的句子词性标注的例子: 如果我们假设所有词的词性只和它相邻的词的词性有关时,这个随机场就特化成一个马尔科夫随机场。比如第三个词的词性除了与自己本身的位置有关外,只与第二个词和第四个词的词性有关。
3. 从马尔科夫随机场到条件随机场
理解了马尔科夫随机场,再理解CRF就容易了。CRF是马尔科夫随机场的特例,它假设马尔科夫随机场中只有和两种变量,一般是给定的,而一般是在给定的条件下我们的输出。这样马尔科夫随机场就特化成了条件随机场。在我们十个词的句子词性标注的例子中,是词,是词性。因此,如果我们假设它是一个马尔科夫随机场,那么它也就是一个CRF。
第三篇
条件随机场应该是机器学习领域比较难的一个算法模型了,难点在于其定义之多(涉及到概率图模型、团等概率)、数学上近似完美(涉及到概率、期望计算,最优化方面的知识),但是其在自然语言处理方面应用效果比较好,所以本文结合李航老师的《统计学习方法》学习一下。
1.定义
1.1 图
图是由结点和连接结点的边组成的集合。结点和边分别记作v和e,结点和边的集合分别记作V和E,图记作G=(V,E)。无向图是指边没有方向的图。
1.2 概率图模型(PGM)
概率图模型是一类用图的形式表示随机变量之间条件依赖关系的概率模型,是概率论与图论的结合。根据图中边有无方向,常用的概率图模型分为两类:有向图(贝叶斯网络、信念网络)、无向图(马尔可夫随机场、马尔可夫网络)。
(1)有向图的联合概率:
其中,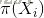
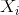
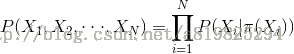
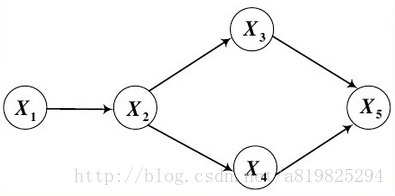
如上图所示,则有
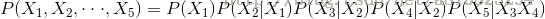
(2)概率无向图模型:
设有联合概率分布P(Y),由无向图G=(V,E)表示,在图G中,结点表示随机变量,边表示随机变量之间的依赖关系。如果联合概率分布P(Y)满足成对、局部或全局马尔可夫性,就称此联合概率分布为概率无向图模型或马尔可夫随机场。
尽管在给定每个节点的条件下,分配给该节点一个条件概率是可能的,无向图的无向性导致我们不能用条件概率参数化表示联合概率,而要从一组条件独立的原则中找出一系列局部函数的乘积来表示联合概率。
最简单的局部函数是定义在图结构中的团上的势函数,并且是严格正实值的函数形式。
下面我们来看下上面出现的马尔可夫性、团的定义
1.3 马尔可夫性

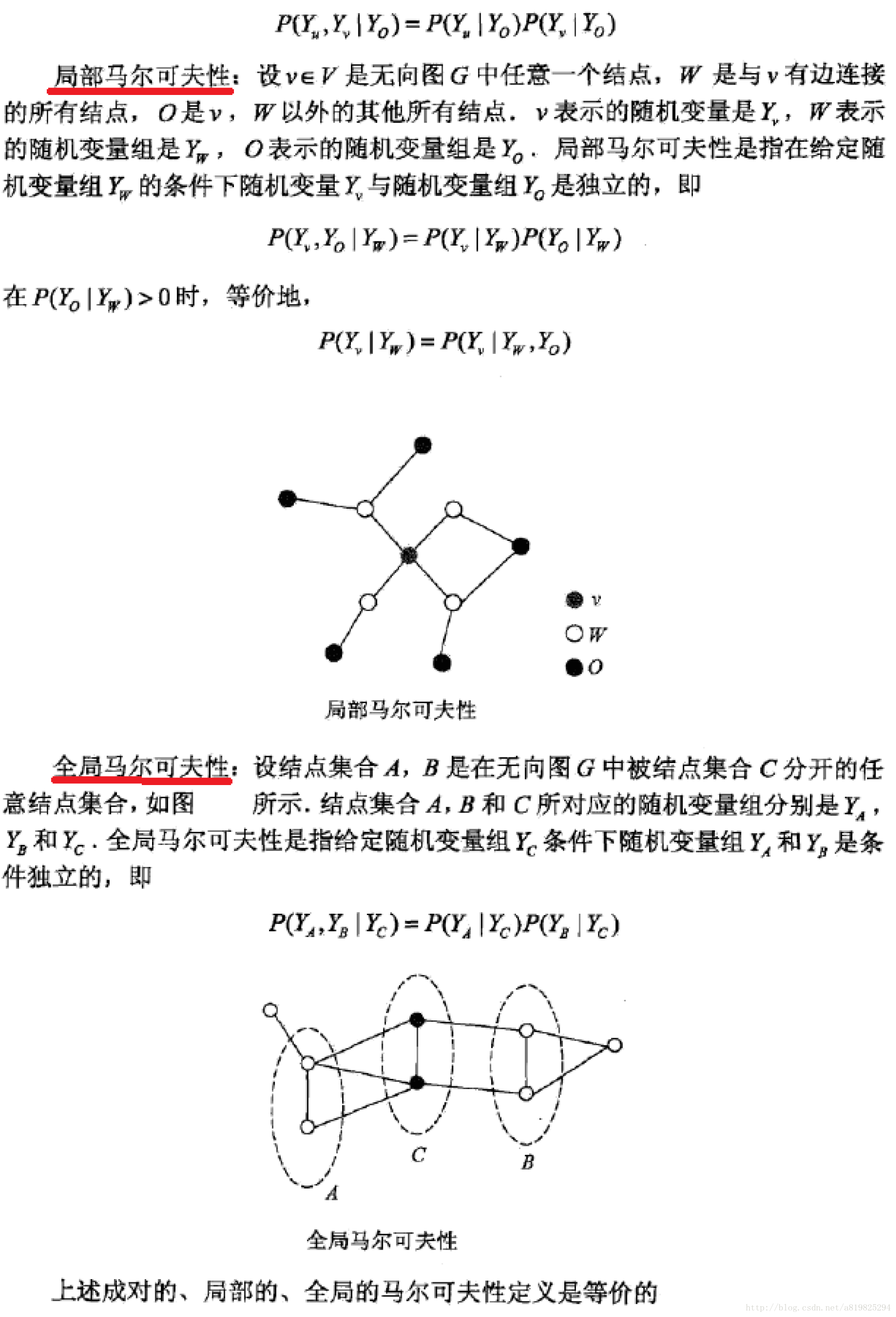
1.4 团与最大团
无向图G中任何两个结点均有边连接的结点子集称为团,若C是无向图G的一个团,并且不能再加进任何一个G的结点使其称为一个更大的团,则称此C为最大团。
下图表示由4个结点组成的无向图。图中由2个结点组成的团有5个: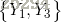
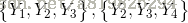
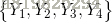
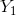
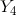
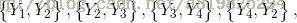
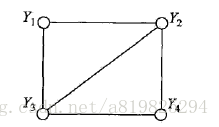
将概率无向图模型的联合概率分布表示为其最大团上的随机变量的函数的乘积形式的操作,成为概率无向图模型的因子分解。
1.5 概率无向图模型的联合概率分布
给定概率无向图模型,设其无向图为G,C为G上的最大团,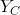
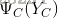
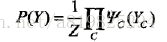
其中,Z是规范化因子,由式
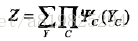
给出。规范化因子保证P(Y)构成一个概率分布。函数
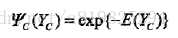
概率无向图模型的因子分解由Hammersley-Clifford定理来保证。
1.6 条件随机场
设X与Y是随机变量,P(Y|X)是在给定X的条件下Y的条件概率分布。若随机变量Y构成一个由无向图G=(V,E)表示的马尔可夫随机场,即
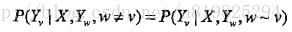
对任意结点v成立,则称条件概率分布P(Y|X)为条件随机场。式中w~v表示在图G=(V,E)中与结点v有边连接的所有结点w,w≠v表示结点v以外的所有结点,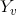
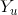
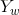
1.7 线性链条件随机场
设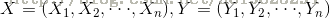
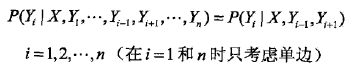
则称P(Y|X)为线性链条件随机场。
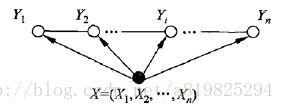
线性链条件随机场
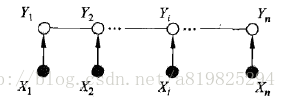
X和Y有相同的图结构的线性链条件随机场
在标注问题中,X表示输入观测序列,Y表示对应的输出标记序列或状态序列。
2.条件随机场的不同形式
2.1 条件随机场的参数化形式
设P(Y|X)为线性链条件随机场,则在随机变量X取值为x的条件下,随机变量Y取值为y的条件概率具有如下形式:
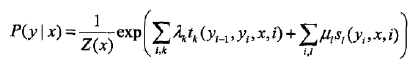
其中,Z(x)是规范化因子
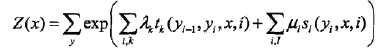
参数解释
(1)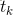
(2)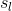
(3)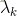
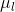
(4)特征函数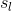
下面看一个简单的例子:

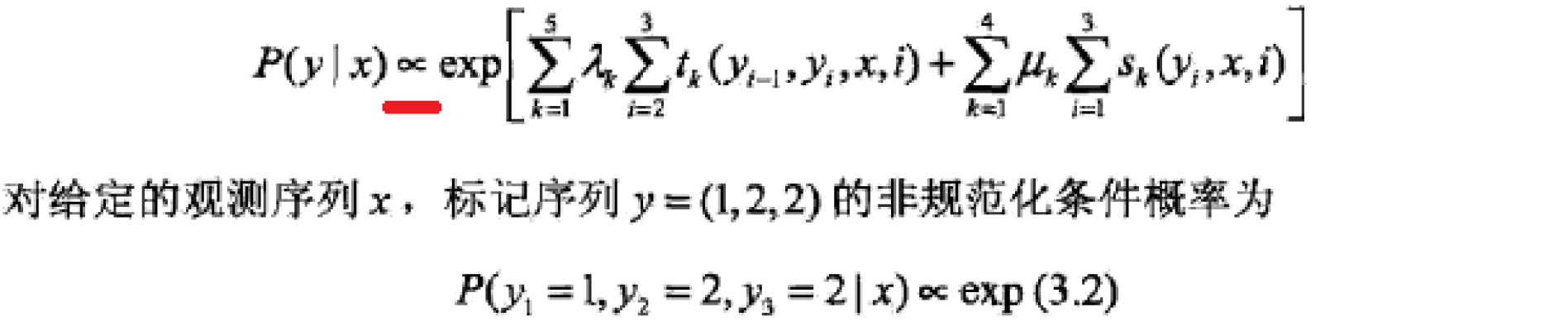
2.2 条件随机场的简化形式
为了后续概率计算、参数估计、推断的方便,对条件随机场形式进行简化
首先将转移特征和状态特征及其权值用统一的符号表示,设有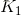
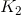
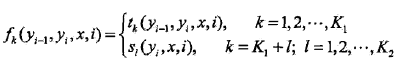
然后,对转移与状态特征在各个位置i求和,记作
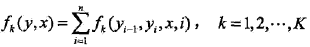
用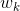
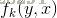
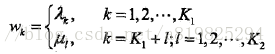
于是,条件随机场可表示为
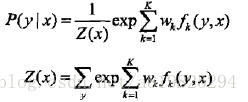
若以w表示权值向量,即
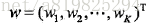
以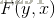
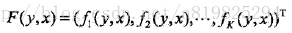
则条件随机场可以写成向量w与
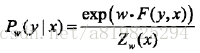
其中,
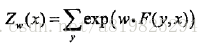
2.3 条件随机场的矩阵形式

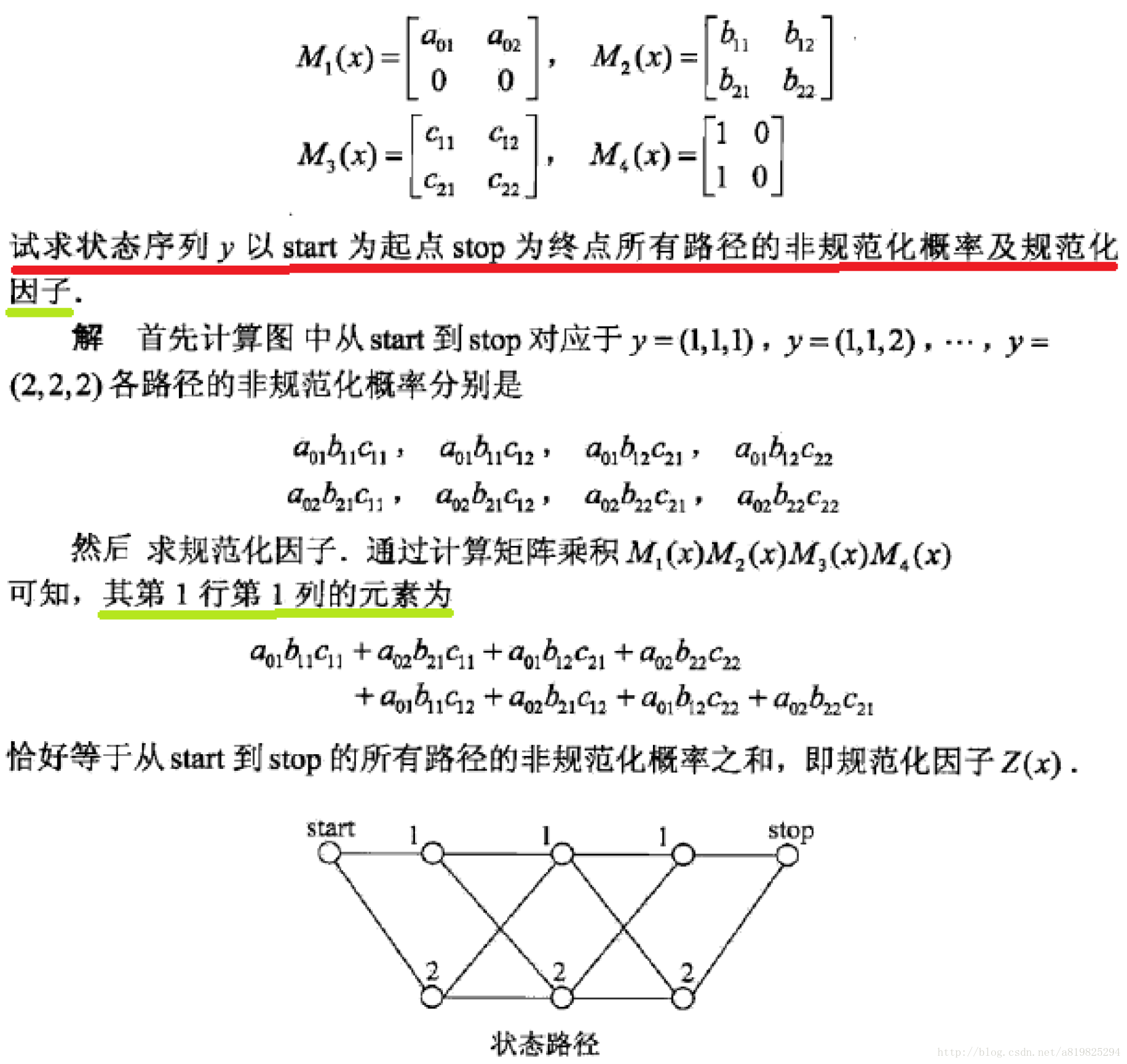
3.概率计算问题
3.1 前向-后向算法
为了方便起见,像隐马尔可夫模型一样,引进前向-后向向量,递归地计算以上概率及期望值,这样的算法称为前向-后向算法


3.2 概率计算

3.3 期望值计算

4.学习算法(参数估计)
条件随机场实际上是定义在时序数据上的对数线性模型,其学习方法包括极大似然估计和正则化的极大似然估计。具体的优化实现方法有改进的迭代尺度法IIS、梯度下降以及牛顿法。

5.预测算法(推断)
条件随机场的预测问题是给定条件随机场P(Y|X)和输入序列(观测序列)x,求条件概率最大的输出序列(标记序列)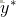
由上式可得:
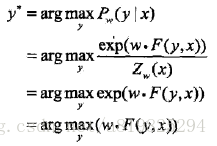
于是,条件随机场的预测问题成为求非规范化概率最大的最优路径问题
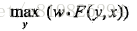
这里,路径表示标记序列。其中
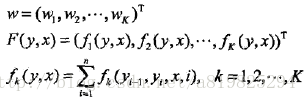
注意,这时只需计算非规范化概率,而不必计算概率,可以大大提高效率。为了求解最优路径,将问题改写成如下形式:
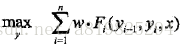
其中,
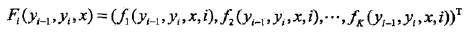
是局部变量。
下面叙述维特比算法.

6.CRF++
现在关于CRF的工具有很多,这里简单介绍一下CRF++
CRF++包含Windows、Linux版本,tar_gz是Linux版本,zip是Windows版本。
介绍一下Windows版本,Linux差不多,不过包含源码,感兴趣可以读一读
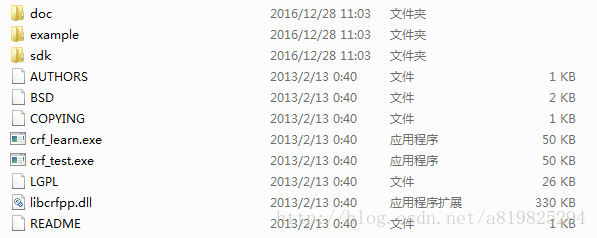
(1)doc文件夹:官方主页的内容
(2)example文件夹:有四个任务的训练数据、测试数据和魔板文件
(3)sdk文件:CRF++的头文件和静态链接库
(4)crf_learn.exe:CRF++的训练程序
(5)crf_test.ext:CRF++的预测程序
(6)libcrfpp.dll:训练程序和预测程序需要使用静态链接库。
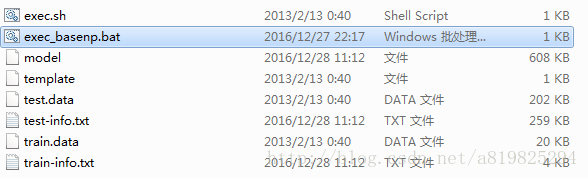
以example文件夹下basenp为例:
编写一个批处理文件如下:
..\..\crf_learn -c 10.0 template train.data model >> train-info.txt
..\..\crf_test -m model test.data >> test-info.txt- 1
- 2
运行exec_basenp.bat之前:

运行exec_basenp.bat之后: