1.4 归纳偏好
版本空间中的多个假设可能会产生不同的输出:
对于同一个样本,产生不同结果。
这时,学习算法本身的"偏好"就会起到关键的作用.
- 机器学习算法在学习过程中对某种类型假设的偏好,称为"归纳偏好" (inductive bias),或简称为"偏好"。
- 任何一个有效的机器学习算法必有其归纳偏好,否则它将被假设空间中看似在训练集上"等效"的假设所迷惑,而无法产生确定的学习结果.
- 归纳偏好的作用在图1.3 这个回归学习图示中可能更直观.这里的每个训练样本是因中的一个点 (x , y) , 要学得一个与训练集一致的模型,相当于找到一条穿过所有训练样本点的曲线.

-
归纳偏好可看作学习算法自身在一个可能很庞大的假设空间中对假设进行选择的启发式或"价值观".
-
“奥卡姆剃刀” (Occam’s razor)是一种常用的、自然科学研究中最基本的原则,即"若有多个假设与观察一致,则选最简单的那个".
-
归纳偏好对应了学习算法本身所做出的关于"什么样的模型更好"的假设.是否有好的泛化能力(通过对训练样本的学习,能更正确地预测测试样本)等。
-
为简单起见,假设样本空间 X 和假设空间组都是离散的.令 P(hIX,εa)代表算法εa于训练数据 X 产生假设 h 的概率, f 代表我们希望学习的真实目标函数 . 'εa 的"训练集外误差",即εa在训练集之外的所有样本上的误差(泛化误差)为

tips: 若f均匀分布,则有一半的f对x的预测与f(x)不一致。
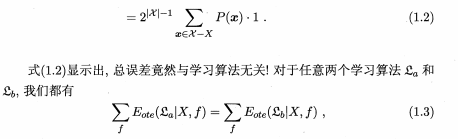
也就是说,无论学习算法εa多聪明、学习算法εb多笨拙,它们的期望性能竟相同!这就是"没有免费的午餐"定理 (No Free Lunch Theorem,简称 NFL定理) [Wolpert, 1996; Wolpert and Macready, 1995].
NFL 定理有一个重要前提:所有"问题"出现的机会相同、或所有问题同等重要.
NFL 定理最重要的寓意是让我们清楚地认识到,脱离具体问题,空泛地谈论"什么学习算法更好"毫无意义,因为若考虑所有潜在的问题。所有学习算法都一样好.要谈论算法的相对优劣,必须要针对具体的学习问题;在某些问题上表现好的学习算法,在另一些问题上却可能不尽如人意,学习算法自身的归纳偏好与问题是否相配,往往会起到决定性的作用.
1.5 发展历程
-
机器学习是人工智能 (artificial intelligence)研究发展到一定阶段的必然产物.
-
二十世纪五十年代到七十年代初,人工智能研究处于推理期 ,那时人们以为只要能赋予机器逻辑推理能力,机器就能具有智能.这一阶段的代表性工作主要有 A. Newell 和 H. Simon 的"逻辑理论家" (Logic Theorist)程序以及此后的"通用问题求解" (General Problem Solving)程序等,这些工作在当时取得了令人振奋的结果.例如"逻辑理论家"程序在 1952 年证明了著名数学家罗素和怀特海的名著《数学原理》中的 38 条定理 7 在 1963 年证明了全部 52条定理,特别值得一提的是,定理 2.85 甚至比罗素和怀特海证明得更巧妙. A.Newell 和 H. Simon 因为这方面的工作获得了 1975 年圈灵奖.
-
然而随着研究向前发展,人们逐渐认识到,仅具有逻辑推理能力是远远实现不了人工智能的。E. A. Feigenbau日1 等人认为,要使机器具有智能,就必须设法使机器拥有知识. 在他们的倡导下,从二十世纪七十年代中期开始,人工智能研究进入了 知识期。在这一时期,大量专家系统问世,在很多应用领域取得了大量果.E.A.Feigenbaum 作为"知识工程"之父在 1994 年获得图灵奖.但是,人们逐渐认识到,专家系统面临"知识工程瓶颈",简单地说,就是由人来把知识总结出来再教给计算机是相当困难的.于是,一些学者想到,如果机器自己能够学习知识该多好!
-
事实上,图灵在 1950 年关于图灵测试的文章中就曾提到了机器学习的可能;二十世纪五十年代初已有机器学习的相关研究,例如 A. Samucl 著名的跳棋程序.五十年代中后期基于神经网络的"连接主义(connectionism) 学习开始出现,代表性工作有 F. Rosenblatt 的感知机 (Perceptron) 、 B. Widrow 的Adaline 等.在六七十年代,基于逻辑表示的"符号主义" (symbolism) 学习技术蓬勃发展,代表性王作有 P. Winston 的"结构学习系统"、R. S. Michalski等人的"基于逻辑的归纳学习系统’,E. B. Hunt 等人的"概念学习系统"等;以决策理论为基础的学习技术以及强化学习技术等也得到发展,代表性工作有 N. J. Nilson 的"学习机器"等·二十多年后红极一时的统计学习理论的一些奠基性结果也是在这个时期取得的.
-
1980 年夏,在美国卡耐基梅隆大学举行了第一届机器学习研讨会 (IWML);同年, ((策略分析与信息系统》连出三期机器学习专辑; 1983 年, Tioga 山版社出版了R. S. Michalski、 J. G. Carbonell 和 T. Mitchell 主编的《机器学习:一种人工智能途径)) [Michalski et al., 1983] ,对当时的机器学习研究工作进行了总结; 1986 年 7 第→本机器学习专业期刊 Machine LeαTηing 创刊; 1989 年,人工智能领域的权威期刊 Artificial Intelligence 出版机器学习专辑,刊发了当时一些比较活跃的研究工作?其内容后来出现在 J. G. Carbonell 主编、 MIT 出版社 1990 年的《机器学习:范型与方法》[Carbonell, 1990] 一书中.总的来看,二十世纪八十年代是机器学习成为一个独立的学科领域、各种机器学习技术百花初绽的时期.
-
R. S. Michalski 等人 [Michalski et al., 1983] 把机器学习研究划分为"从样例中学习" “在问题求解和规划中学习” “通过观察和发现学习” “从指令中学习"等种类; E. A. Feigenbaum 等人在著名的《人工智能手册》(第二卷)[Cohen and Feigenbaum , 1983] 中,则把机器学习划分为"机械学习” “示教学习” “类比学习"和"归纳学习"机械学习亦称"死记硬背式学习”,即把外界输入的信息全部记录下来,在需要时原封不动地取出来使用.这实际上没有进行真正的学习, 仅是在进行信息存储与检索;示教学习和类比学习类似于R. S. Michalski 等人所说的"从指令中学习"和"通过观察和发现学习"归纳学习相当于"从样例中学习",即从训练样例中归纳出学习结果.二十世纪八十年代以来,被研究最多、应用最广的是"从样例中学习" (也就是广义的归纳学习) ,它涵盖了监督学习、无监督学习等,本书大部分内容均属此范畴.下面我们对这方面主流技术的演进做一个简单回顾.
-
在二十世纪八十年代,“从样例中学习"的一大主流是符号主义学习,其代表包括决策树 (decision tree)和基于逻辑的学习.典型的决策树学习以信息论为基础,以信息熵的最小化为目标,直接模拟了人类对概念进行判定的树形流程.基于逻辑的学习的著名代表是归纳逻辑程序设计 (Inductive LogicProgramming,简称 ILP) ,可看作机器学习与逻辑程序设计的交叉,它使用一阶逻辑(即谓词逻辑)来进行知识表示,通过修改和扩充逻辑表达式(例如 Prolog表达式)来完成对数据的归纳.符号主义学习占据主流地位与整个人工智能领域的发展历程是分不开的.前面说过,人工智能在二十世纪五十到八十年代经历了"推理期"和"知识期”,在"推理期"人们基于符号知识表示、通过演绎推理技术取得了很大成就,而在"知识期"人们基于符号知识表示、通过获取和利用领域知识来建立专家系统取得了大量成果,因此,在"学习期"的开始,符号知识表示很自然地受到青睐.事实上,机器学习在二十世纪八十年代正是被视为"解决知识工程瓶颈问题的关键"而走上人工智能主舞台的.决策树学习技术由于简单易用,到今天仍是最常用的机器学习技术之一. ILP 具有很强的知识表示能力,可以较容易地表达出复杂数据关系,而且领域知识通常可方便地通过逻辑表达式进行描述,因此, ILP 不仅可利用领域知识辅助学习,还可通过学习对领域知识进行精化和增强;然而,成也萧何、败也萧何,由于表示能力太强,直接导致学习过程面临的假设宅间太大、复杂度极高。因此,问题规模稍大就难以有效进行学习,九十年代中期后这方面的研究相对陷入低潮.
-
二十世纪九十年代中期之前,“从样例中学习"的另一主流技术是基于神经网络的连接主义学习.连接主义学习在二十世纪五十年代取得了大发展,因为早期的很多人工智能研究者对符号表示有特别偏爱。例如图灵奖得主 E. Simon 曾断言人工智能是研究"对智能行为的符号化建模”,所以当时连接主义的研究未被纳入主流人工智能研究范畴.尤其是连接主义自身也遇到了很大的障碍。正如图灵奖得主 M. Minsky 丰11 S. Papert 在 1969 年指出, (当时的)神经网络只能处理线性分类,甚至对"异或"这么简单的问题都处理小了. 1983 年,J. J. Hopfield 利用神经网络求解"流动推销员问题"这个著名的 NP 难题取得重大进展,使得连接主义重新受到人们关注. 1986 年, D. E. Rumelhart 等人重新发明了著名的 BP 算法,产生了深远影响.与符号主义学习能产生明确的概念表示不同,连接主义学习产生的是"黑箱"模型,因此从知识获取的角度来看,连接主义学习技术有明显弱点;然而,由于有 BP 这样有效的算法,使得它可以在很多现实问题上发挥作用.事实上, BP 一直是被应用得最广泛的机器学习算法之一.连接主义学习的最大局限是其"试错性 '; 简单地说,其学习过程涉及大量参数,而参数的设置缺乏理论指导,主要靠于工"调参",夸张一点说,参数调节上失之毫厘,学习结果可能谬以千里.
-
二十世纪九十年代中期"统计学习" (statistical learning) 闪亮登场并迅速占据主流舞台,代表性技术是支持向量机 (Support Vector Machine,简称SVM) 以及更一般的"核方法" (kernel methods). 这方面的研究早在二十世纪六七十年代就已开始,统计学习理论 [Vapnik, 1998] 在那个时期也已打下了基础.例如 V. N. Vapnik 在 1963 年提出了"支持向量"概念,他和 A. J. Chervonenkis 在 1968 年提出 VC 维,在 1974 年提出了结构风险最小化原则等.但直到九十年代中期统计学习才开始成为机器学习的主流,一方面是由于有效的支持向量机算法在九十年代初才被提出,其优越性能到九十年代中期在文本分类应用中才得以显现;坤一方面,正是在连接主义学习技术的局限性凸显之后,人们才把目光转向了以统计学习理论为直接支撑的统计学习技术.事实上,统计学习与连接主义学习有密切的联系.在支持向量机被普遍接受后,核技巧 (kernel trick) 被人们用到了机器学习的几乎每一个角落,核方法也逐渐成为机器学习的基本内容之一.
-
有趣的是, 二十一世纪初,连接主义学习又卷土重来,掀起了以"深度学习"为名的热潮.所谓深度学习, 狭义地说就是"很多层"的神经网络.在若干测试和竞赛上,尤其是涉及语音、图像等复杂对象的应用中,深度学习技术取得了优越性能.以往机器学习技术在应用中要取得好性能,对使用者的要求较高;而深度学习技术涉及的模型复杂度非常高,以至于只要下工夫"调参把参数调节好, 性能往往就好.因此,深度学习虽缺乏严格的理论基础,但它显著降低了机器学习应用者的门槛,为机器学习技术走向工程实践带来了便利.那么,它为什么此时才热起来呢?有两个基本原因:数据大了、计算能力强了. 深度学习模型拥有大量参数,若数据样本少,则很容易"过拟合".如此复杂的模型、如此大的数据样本,若缺乏强力计算设备,根本无法求解.恰由于人类进入了"大数据时代",深度学习技术焕发又一春.有趣的是,神经网络在二十世纪八十年代中期走红,与当时Intel x86 系列微处理器与内存条技术的广泛应用所造成的计算能力、数据访存效率比七十年代有显著提高不无关联.深度学习此时的状况,与彼时的神经网络何其相似.
-
需说明的是,机器学习现在已经发展成为一个相当大的学科领域,本节仅是管中窥豹,很多重要技术都没有谈及,耐心的读者在读完本书后会有更全面的了解.
1.6 应用现状
- 在计算机科学的诸多分支学科领域中,无论是多媒体、图形学,还是网络通信、软件工程,乃至体系结构、芯片设计,都能找到机器学习技术的身影,尤其是在计算机视觉、自然语言处理等"计算机应用技术"领域,机器学习已成为最重要的技术进步源泉之一.
1.7 阅读材料
- [Mitchell, 1997] 是第一本机器学习专门性教材, [Duda et al., 2001; Alcpaydin, 2004; Flach, 2012] 都是出色的入门读物. [Hastie et al., 2009] 是很好的进阶读物, [Bishop, 2006] 也很有参考价值。尤其适合于贝叶斯学习偏好者.[Shalev-Shwartz and Ben-David, 2014] 则适合于理论偏好者. [Witten et al,2011] 是基于 WEKA 撰写的入门读物有助于初学者通过 WEKA 实践快速掌握常用机器学习算法.
- WEKA 是著名的免费机器学习算法程序库,由
新西兰 Wailkato大学研究人员基于 JAVA 开发
http://www.cs.waikato.ac.nz/ml/weka/



