1 绪论
- 分类和回归
- 分类:预测的是离散值,classification
- 回归:预测的是连续值,regression
- 奥卡姆剃刀:若有多个假设与观察一致,则选择简单的那个
2 模型评估和选择
-
评估方法
- 留出法:train和test做split,尽量保证二者数据分布一致
- 交叉验证:cross-validation. 分为K组train和test,从而进行k此训练和测试,从而尽量利用所有数据
- 自助法:
-
性能度量
- accuracy:分类正确的样本占总样本个数,不区分正负样本
- precision:只考虑正样本,正确分类的正样本占分出的正样本总数
- recall:只考虑正样本,正确分类的正样本占实际的正样本总数
- F1: 为了平衡P(precision)和R(recall),如下

- Fβ: 使用F1时,P和R同等重要。但在实际问题中,P和R需要侧重某一个。如搜索引擎,更关注recall。
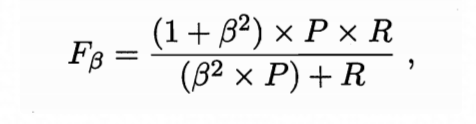
当β=1时,Fβ即为F1
-
偏差与方差
- 偏差:预测与真实结果的偏离程度
- 方差:训练集的变动导致算法性能变化,也就是算法稳定性
- 无偏估计:预测分布的均值与真实分布的均值相同,称为无偏估计。否则有偏估计
- 有效性:无偏不一定就好,还需要衡量分布的方差。方差越小,有效性越好。
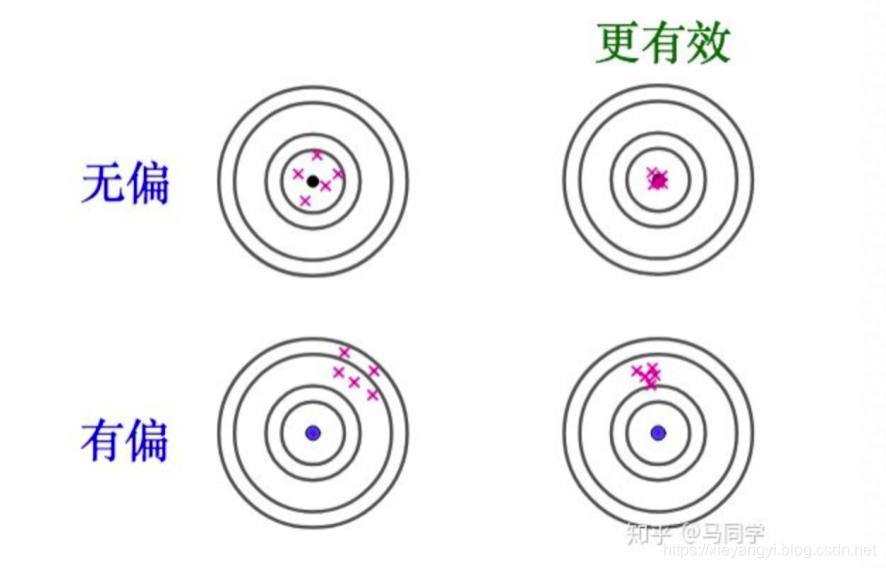
具体可参考知乎文章 https://www.zhihu.com/question/22983179
3 线性模型
- 距离
- 欧式距离:均方,几何距离。两点之间直线距离
- 曼哈顿距离:线性。两点之间驾驶距离
- 切比雪夫距离:国际象棋中王后从一点走到另一点的最小距离。王后可直行,横行,斜行
- 闵可夫斯基距离:一组距离,
- 参数p为1,则是曼哈顿距离
- 参数p为2则欧式距离,
- p为无穷,则是切比雪夫距离
- 马氏距离:基于样本分布的距离
- 余弦距离:余弦夹角,向量点积
- 汉明距离:将字符串S替换为T,需要替换的字符个数。也是编辑距离
- jaccard距离:交集除以并集
- 最小二乘法:与MSE均方差含义有些类似。基于MSE最小化来进行模型求解的方法称为最小二乘法
- LDA:线性判别分析。给定训练样例集,设法将样例投影到一条直线上,同类样例投影点尽可能接近,不同类尽可能远。
- P和NP问题,衡量问题计算复杂度。参考 https://blog.csdn.net/qq_29176963/article/details/82776543
- P问题:时间复杂度为多项式的算法,计算耗时可控
- NP问题:不确定算法时间复杂度是否为多项式,但验证算法的时间复杂度为多项式。P问题是NP问题的子集
- NPC问题,NP完全问题,只要解决了这个问题,所有的NP问题都可以解决
- NPH问题:NP难问题,不一定是NP问题,难以找到多项式时间复杂度算法
8 集成学习
- Boosting和Bagging
- Boosting 学习器间强依赖,必须串行
- Bagging 学习器独立,可并行
- 集成策略
- 平均法,分为简单平均和加权平均
- 投票法,分为绝对多vote,相对多vote,和加权vote
- 学习法,stacking,通过另一个学习器来集成。
9 聚类
- 聚类指标,分为有验证集指标和无验证集指标。sklearn都实现了他们。参考https://www.studyai.cn/modules/clustering.html
- 有验证集
- FM
- rand,兰德系数
- NMI,互信息
- homogeneity,同质性
- 无验证集
- DBI,DB指数
- 距离计算:可采用欧式,曼哈顿,闵可夫斯基,余弦,编辑距离等多种,同样sklearn的实现中可以自由设置
- k-means步骤:
- 随机选取k个值作为初始均值向量(冷启动)
- 将样本放入距离最近的均值向量簇中
- 簇构造好后,重新计算均值向量
- 迭代第二步
- 直到两次迭代的结果簇完全相同,则停止
- DBScan步骤:
- 先基于邻域参数,最小距离,最小簇size,计算所有可能的core
- 从core中选一个,计算器密度可达的所有样本,将包含的core从core集合中去掉
- 剩余core集合中继续执行第二步
- core集合为空,或无法产生新聚类,则结束
- 层次聚类:
- 距离最近两两组合,不断重复
其他
-
最大似然估计MLE https://blog.csdn.net/u011508640/article/details/72815981
- 概率函数:已知模型和参数,求解不同的样本X出现的概率Y
- 似然函数:同一样本X,求解在不同模型参数下出现的概率Y。
- 最大似然估计:利用观察到样本和它的概率,求解模型参数,使得概率最大。比如通过统计人群收入和人群年龄的概率分布样本,并假设它服从正态分布,估计出正态分布的期望和方差,从而确定似然函数的参数。
-
L1正则和L2正则 https://blog.csdn.net/jinping_shi/article/details/52433975
- 正则的作用:在loss函数上加入正则惩罚项,对模型函数复杂度进行惩罚,越复杂的模型正则项越大,从而去选择loss相近情况下,更简单的模型。符合奥卡姆剃刀法则
- L1正则:权值向量中各w的绝对值之和,不一定处处可导。L1正则有利于模型参数的稀疏化,同时可以减少过拟合。
F(x)=f(x)+λ∣∣x∣∣ - L2正则:权值向量中各w平方之和再开方,处处可导。L2正则对模型稀疏化没有贡献,但可大大加快模型参数收敛,防止过拟合。
F(x)=f(x)+λ∣x∣ ^2