文章目录
Large Scale machine learning
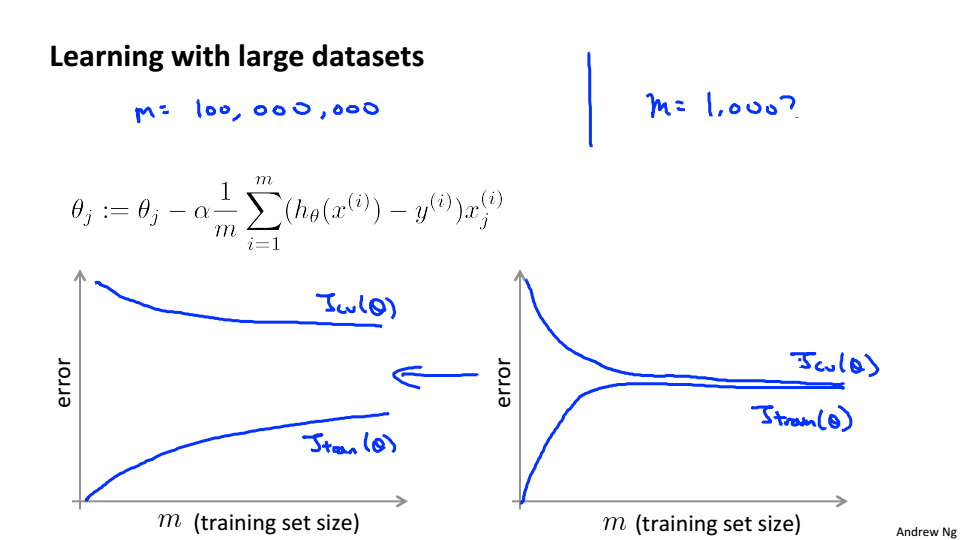
Learning with large datasets
当数据量非常的大的时候,我们应该从中选取少量的数据,使用我们的算法进行计算,绘制学习曲线,如果学习曲线是左边的时候说明算法高方差,这时候提高数据量,就可以提高性能,如果是右边的图形,说明算法高偏差,增加数据量并不会有什么改变
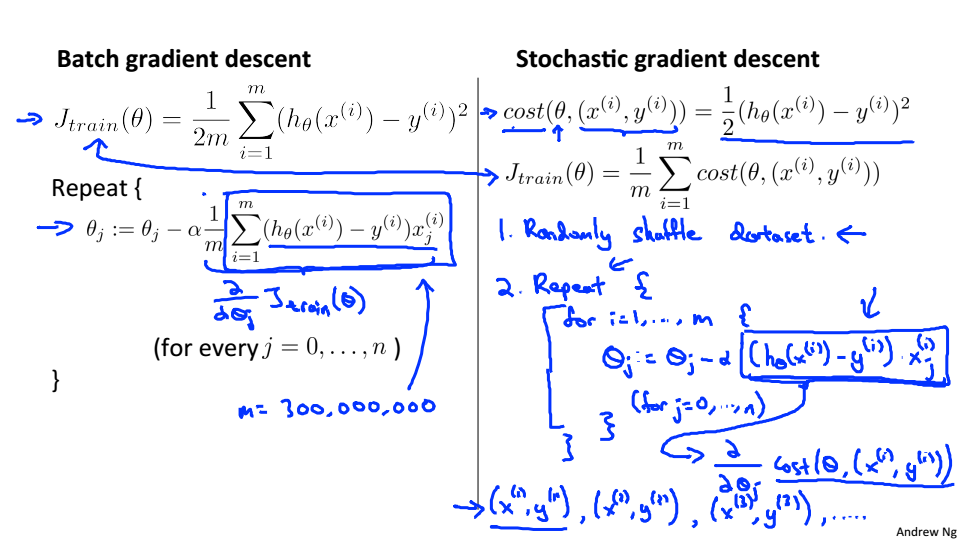
Stochastic Gradient Descent
当数据量较大的时候,每一次梯度下降都会耗费大量的计算力,所以介绍随机梯度下降
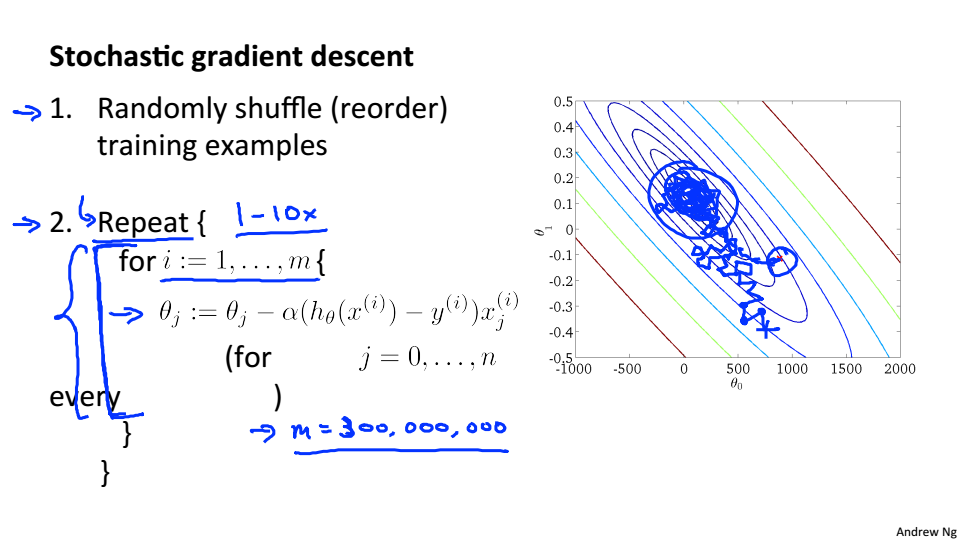
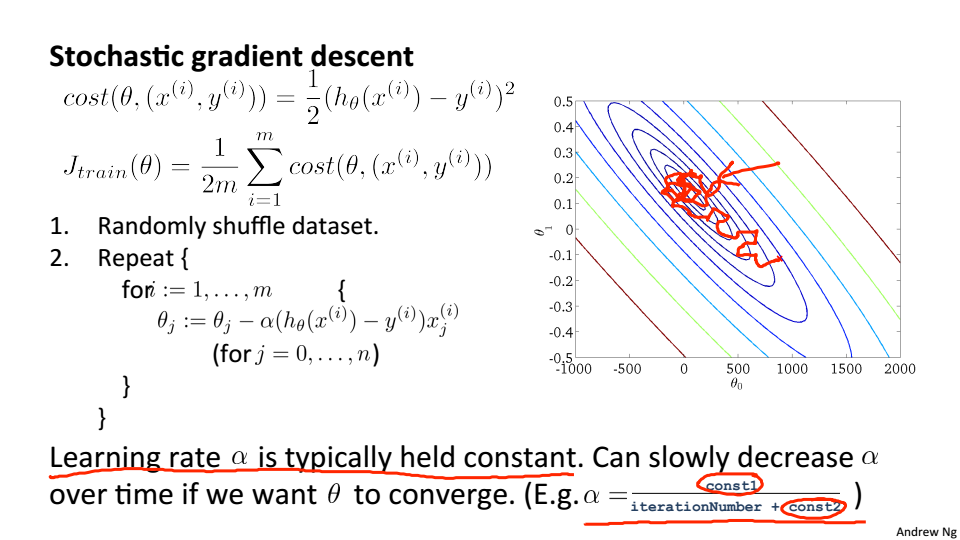
随机梯度下降:
- 打乱数据
- 对单一的训练样本进行更新参数
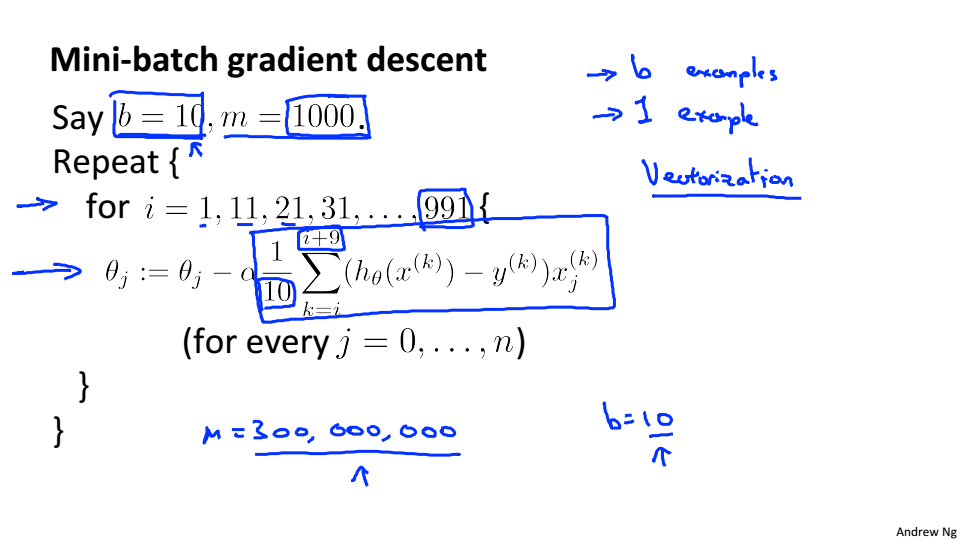
Mini-Batch Gradient Descent
小批量随机梯度下降介于梯度下降和随机梯度下降之间,每次选取一定数量的样本进行梯度下降
Stochastic Gradient Descent Convergence
只需要每次更新参数前计算损失
每一千次迭代,求最后1000样本的损失的平均值,绘制图像

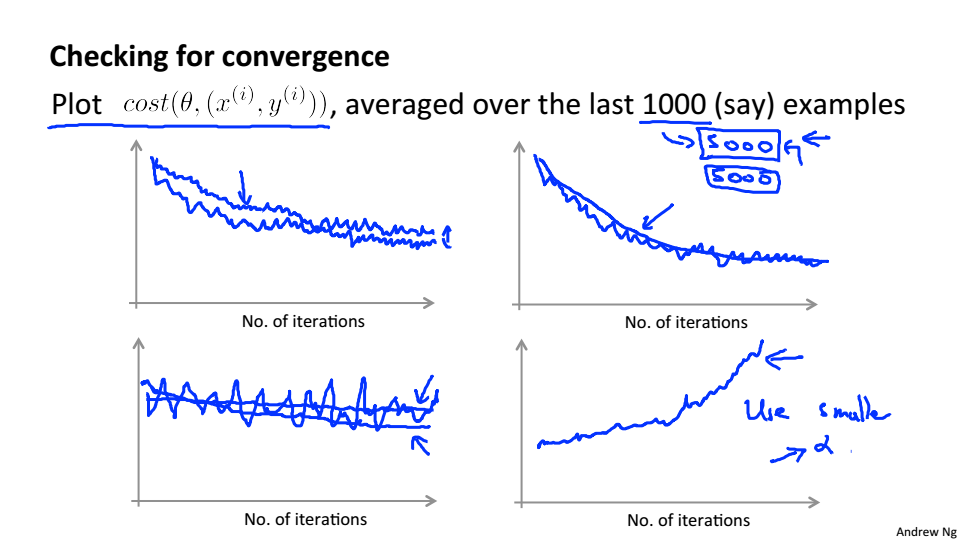
使用随机梯度下降,最终会在最小值附近波动
如果想要让随机梯度下降确实收敛到全局最小值,可以随着时间的变化减小学习率的值
Advanced Topics
Online Learning
当我们拥有连续的数据流,就可以使用算法进行建模,并不断的优化模型
以快递公司为例,每当用户访问网站提交数据后,都会更新参数

其它例子

Map-reduce and data parallelism
在实际使用可能不是在一台机器上运行机器学习算法,这就需要了解Map-reduce
Map-reduce基本思想
在每台机器上分别计算梯度,在结合在一起
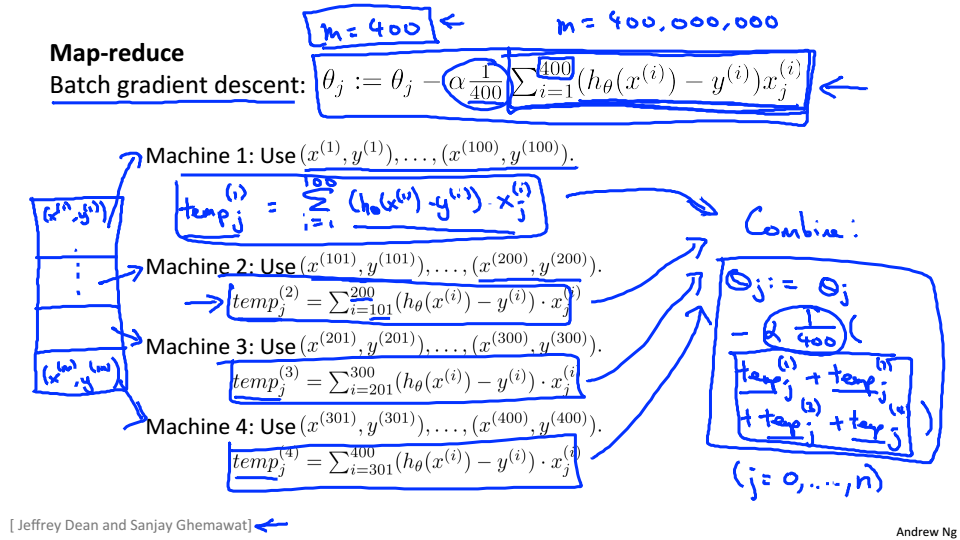
只要算法可以表示为训练样本的求和,就可以考虑使用map-reduce