爬取本地文档:
# -*- coding: cp936 -*-
#import requests
from bs4 import BeautifulSoup
def getZY():
txt=open("d:\cs.txt")
con=txt.read()
print(con)
soup = BeautifulSoup(con, "html.parser")
hu=soup.find_all('span') #{'class':'t3'}
#hu=soup.find_all('span',{'class':'t3'}) #{'class':'t3'}
for h in hu:
print(h.get_text())
def main():
getZY();
main()
爬取网页(乱码!):
# -*- coding: cp936 -*-
import requests
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
#r.content.decode('gbk','ignore')
r.raise_for_status()
#r.encoding = 'utf-8'
return r.text
except:
return ""
def getContent(url):
html = getHTMLText(url)
#print(html)
soup = BeautifulSoup(html, "html.parser")
#print(soup)
divs=soup.find_all('div',{'class':"el"})
#print(divs)
for div in divs:
try:
t3=div.find('span',{'class':'t3'}).get_text()
print(t3)
t4=div.find('span',{'class':'t4'}).get_text()
print(t4)
t5=div.find('span',{'class':'t5'}).get_text()
print(t5)
except:
print("t3 or t4 ot t5 not find,this can be ignore")
print("over!")
def main():
getContent(url);
url = "https://search.51job.com/list/010000%252C020000%252C030200%252C040000,000000,0000,00,9,99,python%2520java,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="
main()
问题:
emmm暑假做过一点爬虫 关于 企业家 的信息 当时看的是 封皮是一个动物 属于图灵一系列的 叫啥忘了....当时遇到的问题是:
1. 乱码(现在还是迷糊)
2. 网页跳转(可以通过函数调用 实现通过一个网页得到另一个网页的内容 )
3. 使用Ajax爬取
4. 有的内容是后台返回给网页 爬取不到
5. 搜问题的时候遇到了 页数是什么+1,但是我在函数调用的时候直接page+1,所以并没有遇到搜到的那个问题

6. 没有尝试 模拟点击过程
7. 没有隐藏自己 的信息 轻易的就能被发现....
6~解决:
# -*- coding: cp936 -*-
# 访问百度,模拟自动输入搜索
# 代码中引入selenium版本为:3.4.3
# 通过Chrom浏览器访问发起请求
# 需要对应版本的Chrom和chromdriver
#chromdriver需要下载与本机chrom浏览器对应的版本
#https://chromedriver.storage.googleapis.com/index.html
#下载后放在chrom.exe文件下 并配置path 但依旧会出错
#简单暴力的直接放在 本脚本文件对应的目录下
#此代码来自https://blog.csdn.net/qq_878799579/article/details/73321015
#运行中错误及补充见 https://blog.csdn.net/qq_39065788?t=1
from selenium import webdriver
# 引入Keys类包 发起键盘操作
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome()
# 访问百度
driver.get('http://www.baidu.com')
# 输入框输入内容
driver.find_element_by_id('kw').send_keys('python')
# 3s
time.sleep(3)
# 删除多输入的一个m (删除操作 模拟键盘的Backspace)
driver.find_element_by_id('kw').send_keys(Keys.BACK_SPACE)
time.sleep(3)
# 输入空格 + '教程'
driver.find_element_by_id('kw').send_keys(Keys.SPACE)
driver.find_element_by_id('kw').send_keys(u"教程")
time.sleep(3)
# 模拟ctrl+a 操作 全选输入框内容
driver.find_element_by_id('kw').send_keys(Keys.CONTROL, 'a')
time.sleep(3)
# 模拟Ctrl+X 操作 剪切输入框内容
driver.find_element_by_id('kw').send_keys(Keys.CONTROL, 'x')
time.sleep(3)
# 模拟Ctrl+V 操作 将剪切内容填入输入框
driver.find_element_by_id('kw').send_keys(Keys.CONTROL, 'v')
time.sleep(3)
# 模拟回车操作 ,开始搜索
driver.find_element_by_id('su').send_keys(Keys.ENTER)
time.sleep(3)
# 退出
driver.quit()
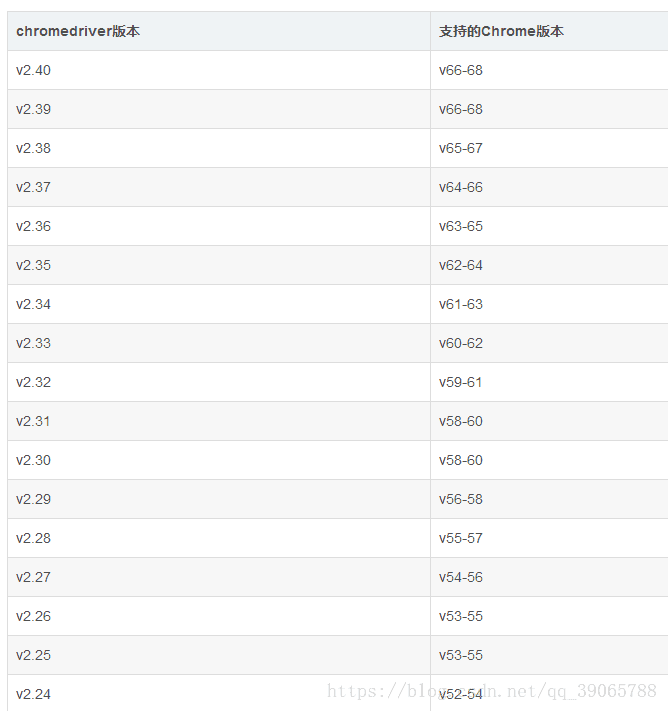
对应chromDriver版本: