网上看到《Python爬取豆瓣Top 250的电影,并输出到文件. demo,学习篇》,学习一下。
我的环境是Win10+python2.7
下载包,需要requests,lxml,bs4。bs4我已经安装过了。
C:\>pip install requests
Collecting requests
Downloading https://files.pythonhosted.org/packages/51/bd/23c926cd341ea6b7dd0b2a00aba99ae0f828be89d72b2190f27c11d4b7fb/requests-2.22.0-py2.py3-none-any.whl (57kB)
100% |████████████████████████████████| 61kB 28kB/s
Collecting certifi>=2017.4.17 (from requests)
Downloading https://files.pythonhosted.org/packages/18/b0/8146a4f8dd402f60744fa380bc73ca47303cccf8b9190fd16a827281eac2/certifi-2019.9.11-py2.py3-none-any.whl (154kB)
100% |████████████████████████████████| 163kB 14kB/s
Collecting urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 (from requests)
Downloading https://files.pythonhosted.org/packages/e0/da/55f51ea951e1b7c63a579c09dd7db825bb730ec1fe9c0180fc77bfb31448/urllib3-1.25.6-py2.py3-none-any.whl (125kB)
100% |████████████████████████████████| 133kB 15kB/s
Collecting idna<2.9,>=2.5 (from requests)
Downloading https://files.pythonhosted.org/packages/14/2c/cd551d81dbe15200be1cf41cd03869a46fe7226e7450af7a6545bfc474c9/idna-2.8-py2.py3-none-any.whl (58kB)
100% |████████████████████████████████| 61kB 54kB/s
Collecting chardet<3.1.0,>=3.0.2 (from requests)
Downloading https://files.pythonhosted.org/packages/bc/a9/01ffebfb562e4274b6487b4bb1ddec7ca55ec7510b22e4c51f14098443b8/chardet-3.0.4-py2.py3-none-any.whl (133kB)
100% |████████████████████████████████| 143kB 14kB/s
Installing collected packages: certifi, urllib3, idna, chardet, requests
Successfully installed certifi-2019.9.11 chardet-3.0.4 idna-2.8 requests-2.22.0 urllib3-1.25.6
You are using pip version 9.0.3, however version 19.3.1 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.
C:\>pip install lxml
Collecting lxml
Downloading https://files.pythonhosted.org/packages/a2/bf/6cb6118b6492104723afac0f5c149877c76f03254802448cea1ea37c3781/lxml-4.4.1-cp27-cp27m-win_amd64.whl (3.6MB)
100% |████████████████████████████████| 3.6MB 100kB/s
Installing collected packages: lxml
Successfully installed lxml-4.4.1
You are using pip version 9.0.3, however version 19.3.1 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.
C:\>pip install bs4
Requirement already satisfied: bs4 in c:\python27\lib\site-packages
Requirement already satisfied: beautifulsoup4 in c:\python27\lib\site-packages (from bs4)
Requirement already satisfied: soupsieve>=1.2 in c:\python27\lib\site-packages (from beautifulsoup4->bs4)
Requirement already satisfied: backports.functools-lru-cache; python_version < "3" in c:\python27\lib\site-packages (from soupsieve>=1.2->beautifulsoup4->bs4)
You are using pip version 9.0.3, however version 19.3.1 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.
1.requests模块
requests库用于爬取HTML页面,提交网络请求,基于urllib,但比urllib更方便。
参见 https://requests.kennethreitz.org/en/master/
主要方法:
- requests.get(),http请求get方法
- requests.post(),http请求post方法
- requests.head(),获取HTML网页头信息
- requests.put(),http请求put方法
- requests.delete(),http请求delete方法
例:获得网页字符串
r = requests.get('https://api.github.com/user', auth=('user', 'pass'))
关于get,post,put,delete区别,参见https://blog.csdn.net/haif_city/article/details/78333213
综述:
1、POST /url 创建
2、DELETE /url/xxx 删除
3、PUT /url/xxx 更新
4、GET /url/xxx 查看
2.bs4
参见 https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/,写的很详细,还是中文版的。
BeautifulSoup4,简称bs4,能够快速方便简单的提取网页中指定的内容。基本使用过程,先通过其他模块(例如:requests)获得一个网页字符串,然后使用b4s的接口将网页字符串生成一个对象,然后通过这个对象的方法来提取数据。
bs4是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。
bs4自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。关于这一点可以参见 https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#id51。
- 任何HTML或XML文档都有自己的编码方式,比如ASCII 或 UTF-8,但是使用Beautiful Soup解析后,文档都被转换成了Unicode
markup = "<h1>Sacr\xc3\xa9 bleu!</h1>"
soup = BeautifulSoup(markup)
soup.h1
# <h1>Sacré bleu!</h1>
soup.h1.string
# u'Sacr\xe9 bleu!'
- Beautiful Soup用了编码自动检测子库来识别当前文档编码并转换成Unicode编码。BeautifulSoup 对象的 .original_encoding 属性记录了自动识别编码的结果。
soup.original_encoding
'utf-8'
- 通过Beautiful Soup输出文档时,不管输入文档是什么编码方式,输出编码均为UTF-8编码
3.lxml
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高。参见 https://lxml.de/
4.补充:XPath
XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索。
XPath的选择功能十分强大,它提供了非常简明的路径选择表达式,另外,它还提供了超过100个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,几乎所有我们想要定位的节点,都可以用XPath来选择。
XPath于1999年11月16日成为W3C标准,它被设计为供XSLT、XPointer以及其他XML解析软件使用,更多的文档可以访问其官方网站:https://www.w3.org/TR/xpath/
代码如下,我做了些修改
# -*- coding: utf8 -*-
import codecs
import requests
from bs4 import BeautifulSoup
# 下载网址
DOWNLOAD_URL = 'http://movie.douban.com/top250/'
# def 定义download_page函数 --- 相同于PHP function
def download_page(url):
# 使用 requests get方法 .content编码 .text返回页面文本
return requests.get(url).content
#return requests.get(url).text
# 定义parse_html函数
def parse_html(html):
# 使用 Beautifulsoup解析, 解析器使用 lxml
soup = BeautifulSoup(html,"lxml")
# 标签内容获取 <ol class="grid_view">
movie_list_soup = soup.find('ol', attrs={'class': 'grid_view'})
movie_name_list = []
# 循环获取 li->span下标题
for movie_li in movie_list_soup.find_all('li'):
detail = movie_li.find('div', attrs={'class': 'hd'})
#评分
star = movie_li.find('span', attrs={'class': 'rating_num'}).getText()
# 获取title
movie_name = detail.find('span', attrs={'class': 'title'}).getText()
# append函数会在数组后加上相应的元素
movie_name_list.append(movie_name+','+star)
# 获取分页数据
next_page = soup.find('span', attrs={'class': 'next'}).find('a')
if next_page:
return movie_name_list, DOWNLOAD_URL + next_page['href']
return movie_name_list, None
# 定义main函数
def main():
url = DOWNLOAD_URL
# 写法可以避免因读取文件时异常的发生而没有关闭问题的处理了
'''
#保存txt
with codecs.open('movies.txt', 'wb', encoding='utf-8') as fp:
while url:
html = download_page(url)
movies, url = parse_html(html)
fp.write(u'{movies}\n'.format(movies='\n'.join(movies)))
'''
#保存csv
with codecs.open('movies.csv', 'wb', encoding='gbk') as fp:
while url:
html = download_page(url)
movies, url = parse_html(html)
fp.write(u'{movies}\n'.format(movies='\n'.join(movies)))
# _name__ 是当前模块名,当模块被直接运行时模块名为 __main__ 。当模块被直接运行时,代码将被运行,当模块是被导入时,代码不被运行。
if __name__ == '__main__':
main()
运行结果,movies.csv
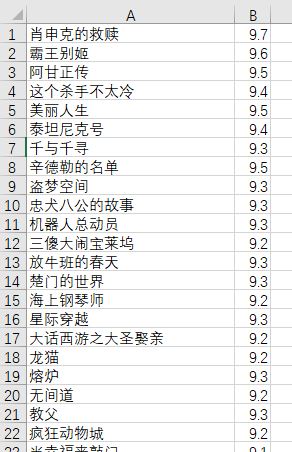
如果有兴趣,还可以追加其他内容。
又,尝试的次数多了,被识别为IP异常,需要登录后才能继续执行。
