前两节我们详细介绍了什么是极大似然估计和EM算法,简单来说就是数据如果是完整的则可以通过均值来估计参数,因为在数据完整的情况下即有发射符号概率也有状态转移概率,通过估计就可以很容易求出隐马尔可夫模型的参数,但是如果只有发射符号概率而没有状态转移概率(即对于的汉字),这样的语料就不能使用最大释然估计了,因此需要使用EM算法,下面我们再来详细的回顾一下第三个问题:
第三个问题:
训练问题或参数估计问题:给定一个观察序列,如何根据最大似然估计来求模型的参数值?即如 何调节模型
的参数,使得
最大?
首先这个问题很重要,而且解决起来也很困难,重要体现在他是构建模型的,因为我们的第一个问题和第二个问题都是建立在模型
已知的情况下才能计算,所以这个问题的解决很重要,困难稍后解释。因此这个问题是最基础的问题,但是为什么要作为第三个问题呢?这是因为这个问题解决起来太麻烦了,因此这样安排。大家知道我们刚开始是没有模型的即HMM的参数都不知道,但是我们有什么呢?我们有语料,因为通过语料可以求解HMM的三个参数即状态转移概率A、符号发射概率B和初始状态概率分布。这里呢要想计算出这些参数,首先我们应该有完美的语料,如果没有完美的语料怎么办呢?所有我们从两方面进行探讨即有完美语料和没有完美语料。
完美语料
所谓完美语料就是我既知道发射符号的序列,也知道状态转移序列,这里我们就可以使用最大释然估计计算HMM的参数了,下面通过书面语进行说明:
参数估计问题是HMM面临的第三个问题,即给定一个观察序列,如何调节模型
的参数,使得
最大化:
模型的参数是指构成的
。最大似然估计方法可以作为HMM参数估计的一种选择。如果产生观察序列
的状态序列
已知,根据最大似然估计,HMM的参数可以通过如下公式计算:

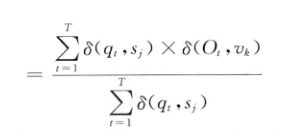
上面的是冲击函数即当两个参数相等是为1,反之为0
上面的使用上式计算估计参数是准确的,在上一篇详细的讲到了,下面我们看看不完美的语料的情况:
不完美语料
不完美语料是指知道观察序列但是不知道状态转移序列,因此无法用最大释然估计进行解决,此时可以是使用EM 算法【Expectation Maximization(期望最大化)】,下面我们就正式引入解决第三问题的解决思路:
由于HMM中的状态序列Q是观察不到的(隐变量),因此,上式最大似然估计的方法不可行。所幸的是,期望最大化(expectationmaximization,(M)算法可以用于含有隐变量的统计模型的参数最大似然估计。其基本思想是,初始时随机地给模型的参数赋值,该赋值遵循模型对参数的限制,例如,从某一状态出发的所有转移概率的和为1。给模型参数赋初值以后,得到模型,然后,根据
可以得到模型中隐变量的期望值。例如,从
得到从某一状态转移到另一状态的期望次数,用期望次数来替代上式得到
中的实际次数,这样可以得到模型参数的新估计值,由此得到新的模型
。从
又可以得到模型中隐变量的期望值,然后,重新估计模型的参数,执行这个迭代过程,直到参数收敛于最大似然估计值。
这种迭代爬山算法可以局部地使最大化。Baum-Welch算法或称前向后向算法(forward-backwardalgorithm)用于具体实现这种EM方法。下面我们介绍这种算法。
给定HMM的参数和观察序列,在时间t位于状态
,时间
位于状态
的概率
可以由下面的公式计算获得:

这个所谓的Baum-Welch算法或称前向后向算法(forward-backwardalgorithm)和我们解决第一个问题很类似的,还是基于动态规划的,如果前面两个问题大家深入理解到了,那么这个算法也会很容易的理解,不明白的建议看看我的前几篇的博客,这里不细讲了,直接给出图供大家参考:

给定HMM 和观察序列
,在时间t位于状态
的概率为
为:
由此,的参数可以由下面的公式从新估计:

根据上面的思路,给出前向后向算法流程:
步骤1 初始化:随机的给参数赋值,使其满足如下约束:

由此得到模型。令
,执行下面的EM的估计。
步骤2 EM计算:
E-步骤: 由模型根据前面的公式计算出
和
;
M-步骤:用 E-步骤得到期望值,根据上面的公式从新估算的值,得到模型
步骤3 循环计算:
令,重复执行EM计算,直到
收敛。
HMM在自然语言处理研究中有着非常广泛的应用。需要提醒的是,除了上述讨论的理论问题以外,在实际应用中还有若干实现技术上的问题需要注意。例如,多个概率连乘引起的浮点数下溢问题。在Viterbi算法中只涉及乘法运算和求最大值问题,因此,可以对概率相乘的算式取对数运算,使乘法运算变成加法运算,这样一方面避免了浮点数下溢的问题,另一方面,提高了运算速度。在前向后向算法中,也经常采用如下对数运算的方法判断参数是否收敛:

其中,为一个足够小的实数值。但是,在前向后向算法中执行EM计算时有加法运算,这就使得EM计算中无法采用对数运算,在这种情况下,可以设置一个辅助的比例系数,将概率值乘以这个比例系数以放大概率值,避免浮点数下溢。在每次迭代结束重新估计参数值时,再将比例系数取消。
以上就是解决第三个问题的全部内容了,下面我们详细探讨一下HMM的用处在哪里,首先当然是应用在语音识别中了,还可以应用到词性标注上,下面我们就好好看看他们的这两方面的应用:
HMM的应用
语音识别
语音识别的前提应该有大量的完备的语料,即如下形式:
ta shi yan jiu wu li de
他 是 研 究 物 理 的
上面的形式就完整的语料了,即有音频和对应的汉字,这样就可以使用最大释然估计进行求解HMM的参数即状态矩阵A、发射矩阵B。当然我们也可以只有拼音而没有汉字,这种语料 就可以通过EM进行求解参数,但是这里大家应该想一想我连汉字都不知道是什么我们怎么确定“ta”就是这个"他"而不是这些“它、塔、她、踏。。。。”呢?因此使用EM估计的参数再去识别语音效果肯定不会很好的,所有尽量通过完整的语料进行估计是最好的。我们通过完备的语料库和图片示例进行整理一下语音识别的过程:

首先呢我们有大量的完整的语料,通过语料我就可以计算各个字词之间的转移概率A,通过可观察的语音我可以找到很多条对应的汉字,计算这些备选的概率取最大的那个概率为这个语音识别的结果,B是符号发射概率,其实这个过程就是第二个基本问题,可以通过维克比算法进行求解。这里需要强调的语音识别的方法很多,也很复杂,这里只是举例演示HMM的使用场合,真正的语音识别会更麻烦,效果会更好。但是如果使用HMM对汉语进行语音识别,主要过程是这样的,好,那下面在介绍一下使用HMM进行分词的应用。
使用HMM进行分词
这现在这里和大家说一下什么是分词,这里使用一个例子进行讲解:

上式就是对一个句子进行分词了,这里的S(single,单个的意思) 、B是(begin,开始)、M(more ,更多)、E(end结束),这里我们是怎么标号的呢,上面是人为正确划分的,这里我们把单个的词使用S来代表,两个字以上的组合词分别使用B、M、E来表示,这样,就把汉字通过符号来表示了。那么我们通过符号就可以把分词问题转化为标注问题了。我们在举一个例子:

我们假设已经标号了,那么我们通过符号就可以表示已经分好的词了,上面虽然分的不对,但是功能已经实现了,所以只要知道这些符号的组合基本上就可以分词了,那么我们就可以把问题转换为给定句子找对应的符号,这不就是隐马尔可夫可以做的事吗?因此我们可以找到这些符号的转移概率,把符合转移看做隐藏状态,句子看做发射状态,这就是HMM问题了,为了更形象,我们看例子:

我们通过标注好的分词,求得句子的分词概率转移矩阵A,B那么就可以通过HMM求出句子的符号,一旦求出符号就可以把对应的字词分解了,就是这个原理。按照这个逻辑只要把问题转化为标注问题就可以使用HMM来解决了,那么词性标注、命名体识别等只要转换成标注问题就可以使用HMM进行解决问题了,因此这样想的,NLP的问题都可以解决了,我们只要有 完美的语料,例如分词问题的完美语料就是既有句子,又有正确的对应的分词符号,我们就可以计算转移矩阵A和发射矩阵B了,就可以解决问题了,好到这里HMM就结束了。 下一节我们讨论一下条件随机场的问题。