引言
Nal Kalchbrenner等人在2014年arXiv上的paper,原文地址:arXiv:1404.2188v1 [cs.CL] 8 Apr 2014。
自然语言处理的基础问题在于句子的语义表示,其他特定的任务如分类等都是在语义表示的基础上进行高层次的处理,所以如何对句子进行表达就成为了核心问题。
针对目前存在的模型,作者提出了DCNN–Dynamic Convolutional Neural Network,利用宽卷积和k-max pooling采样,构造了一种了类似parse tree的结构,能够提取长距离的信息。
该模型在四个数据集上测试,包括情感分析等均取得了不错的结果。
模型
网络结构
网络主要包括两种不同的层,一维卷积层(one-dimensional convolutional layers)和动态k-max池化层(dynamic k-max pooling layers),结构如下:
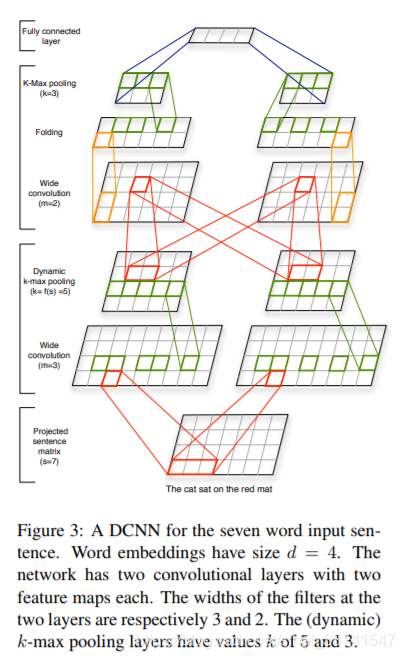
Embedding
这里和一般的网络没有区别,将输入句子s中的每个词w映射为d维向量,同时在训练的过程中对初始化的向量进行修改,如下:
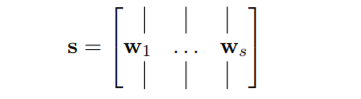
Wide Convolution
卷积部分用的是one-dim卷积,也就是filter的height固定为1,如上图所示。另一个需要注意的是这里用的是宽卷积的方式,宽卷积指的是在卷积操作时对输入矩阵的边缘进行padding补零,这样的好处是不会丢失边缘信息,如下:
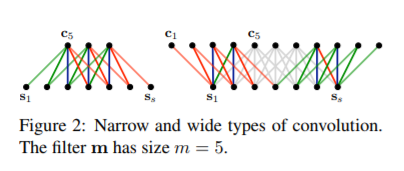
可以看到,左边是传统的卷积方式,这样卷积操作后的结果为l-m+1,其中l为句子的长度,m为卷积长度,m<=l;而右边的宽卷积方式计算出来的结果则是l+m-1,可以看到传统卷积其实是宽卷积方式的一个子集。
从卷积的形式来说,可以看成对输入句子的每一维做了n-gram,其中n<=m。
Dynamic k-Max Pooling
k-max pooling是max-pooling更一般的形式,相比后着,k-max在序列p中,p>=k,提取出序列中前k个最大的值,同时保留它们的相对顺序。这样的好处在于能够提取句子中的k个重要特征,同时作者写道,
It can also discern more finely the number of times the feature is highly activated in p and the progression by which the high activations of the feature change across p.
这应该是一种猜想,能够捕捉特征的激活次数及变化过程。另一个是k-max pooling可以用来处理变长输入,最终的全连接层k值是固定的,而中间的卷积k值由下述公式决定,
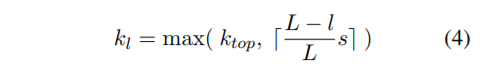
其中
表示当前卷积层数,
代表模型中卷积层总数,
表示全连接层的k值。如,网络中有三个卷积层
,
,输入的句子长度为
,则,
第一层卷积
,第二层卷积
,第三层即全连接层
值得注意的是,作者举了一个例子,
a first order feature such as a positive word occurs at most k1 times in a sentence of length s, whereas a second order feature such as a negated phrase or clause occurs at most k2 times.
这里的一阶与二阶应该是指代低维与高维特征,类似图像中的边角到简单形状,所以用正面情感词与负面情感词来做例子似乎显得不是很恰当。
Non-linear Feature Function
在k-max pooling之后,与传统的CNN一样,对于pooling后的结果加上一个偏置b进行非线性激活,作者提到,
Together with pooling, the feature function induces position invariance and makes the range of higher-order features variable.
pool使得局部特征不变,从高阶特征有更大的选择范围。
Multiple Feature Maps
这个和其他模型没区别,都是使用多个filter提取多份特征,最后进行组合。
Folding
在前面卷积计算中,由于是1-dim卷积,所以实际上对于输入矩阵的操作都是在每一维上单独进行的。
宽卷积能够在词序列的方面上进行特征提取,但是在词向量的维度上也应该建立依赖关系,作者用了一个简单的方式建立联系,即在卷积操作之后,将相邻两个维度的向量进行相加。
这样没有增加任何参数,但是能够在全连接层之前提前考虑到词向量维度上的某些关联。
Other
其他与大部分模型一致,如果在分类任务,增加全连接层后接softmax,损失函数使用交叉熵,正则化部分使用L2正则,使用mini-batch和gradient-based方法进行优化。
模型性质
Word and n-Gram Order
借助宽卷积操作,在一定程度上形成了n-gram形式的特征抽取,使得模型对于句子的先后顺序更为敏感。当然这也是目前很多CNN模型用在文本处理方面的一个性质,对文本局部的特征可以进行一定的提取。
Induced Feature Graph
这个是DCNN模型一个有趣的特征,借助k-max pooling,实际上可以把这种低维到高维的特征提取想象成一颗parse tree,如下:
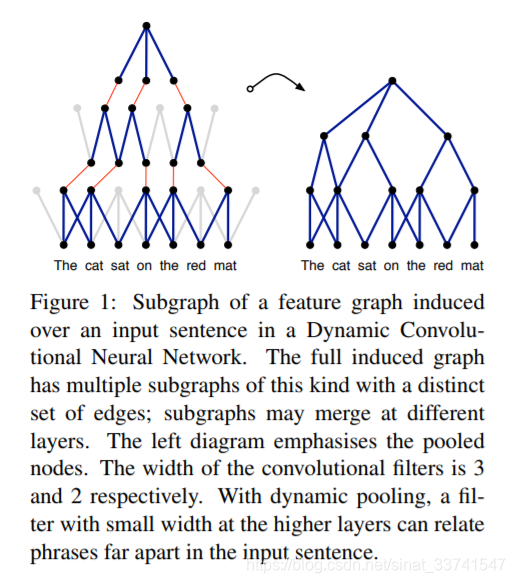
由上图可以看到,低维度的特征被提取出来后,在更高的维度可以被关联起来,从而使得高纬度的特征在一定程度上能够提取到整体句子的信息。
针对CNN只能提取局部信息的问题,这里能做到一定的改善。
实验
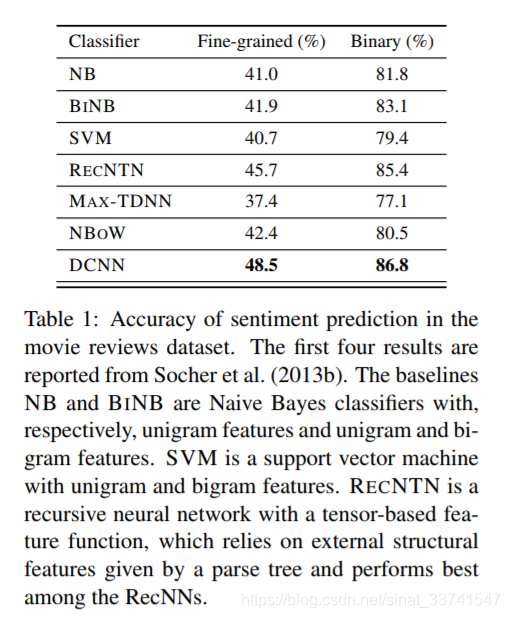
电影评论情感分析
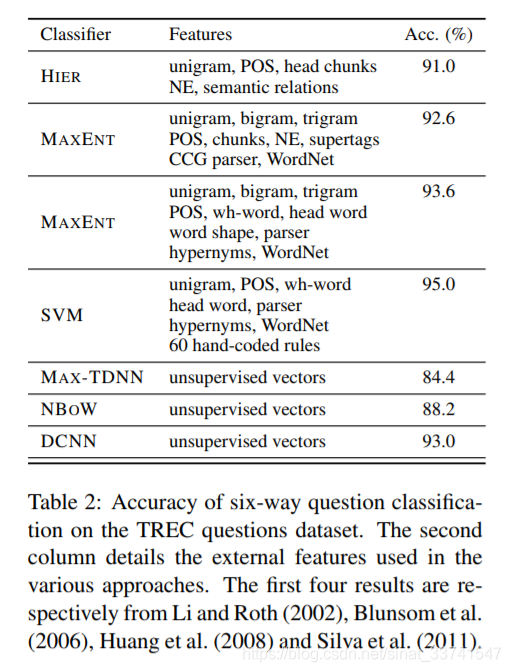
TERC问题数据集
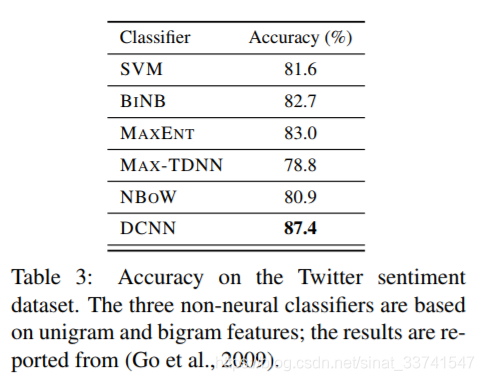
Twitter情感识别
总结
从实验结果来看,DCNN的表现都很不错,相对于传统的模型而言,DCNN不需要构造复杂的人工特征,在简便性上更胜一筹。
另一个是DCNN构造出来的类似parse tree的形式很有吸引力,对于文本的表示,假如能够融入句法方面的知识,或者提取出这方面的特征是一个很有想象力的方向。