RHCS
简介
RHCS即 RedHat Cluster Suite ,中文意思即红帽集群套件。
红帽集群套件(RedHat Cluter Suite, RHCS)是一套综合的软件组件,可以通过在部署时采用不同的配置,以满足你的对高可用性,负载均衡,可扩展性,文件共享和节约成本的需要。
它提供有如下两种不同类型的集群:
1、高可用性:应用/服务故障切换-通过创建n个节点的服务器集群来实现关键应用和服务的故障切换
2、负载均衡:IP 负载均衡-对一群服务器上收到的 IP 网络请求进行负载均衡
特点
1、最多支持128个节点(红帽企业Linux 3 和红帽企业Linux 4 支持 16 个节点)。
2、可同时为多个应用提供高可用性。
3、NFS/CIFS 故障切换:支持 Unix 和 Windows 环境下使用的高可用性文件。
4、完全共享的存储子系统:所有集群成员都可以访问同一个存储子系统。
5、综合数据完整性:使用最新的 I/O 屏障(barrier)技术,如可编程的嵌入式和外部电源开关装置(power switches)。
6、服务故障切换:红帽集群套件可以确保及时发现硬件停止运行或故障的发生并自动恢复系统,同时,它还可以通过监控应用来确保应用的正确运行并在其发生故障时进行自动重启。
实现nginx的高可用
实验环境
1、操作系统版本:RHEL6.5
2、主机:172.25.66.250,后面作为fence主机使用,暂时不用
server1:172.25.66.1,作为主节点,下载luci(提供Conga配置用户界面),ricci,配置好nginx
server4:172.25.66.4,作为备用节点,下载ricci,配置好nginx
3、在server1与server4中配置高可用yum源
[source6.5]
name=source6.5
baseurl=http://172.25.66.250/source6.5
gpgcheck=0
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.66.250/source6.5/HighAvailability
gpgcheck=0
[LoadBalancer]
name=LoadBalancer
baseurl=http://172.25.66.250/source6.5/LoadBalancer
gpgcheck=0
[ResilientStorage]
name=ResilientStorage
baseurl=http://172.25.66.250/source6.5/ResilientStorage
gpgcheck=0
[ScalableFileSystem]
name=ScalableFileSystem
baseurl=http://172.25.66.250/source6.5/ScalableFileSystem
gpgcheck=0
4、在物理及172.25.66.250做好虚拟机的解析
vim /etc/hosts

实验操作
一、打开网页luci管理界面
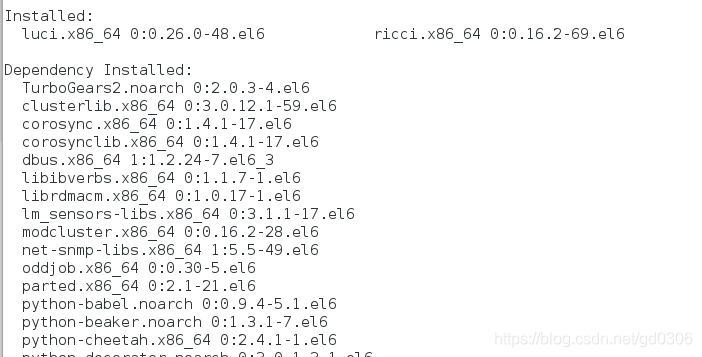
1:在server1上面下载 ricci(luci界面下的集群管理) 和 luci ,在server4上面下载 ricci
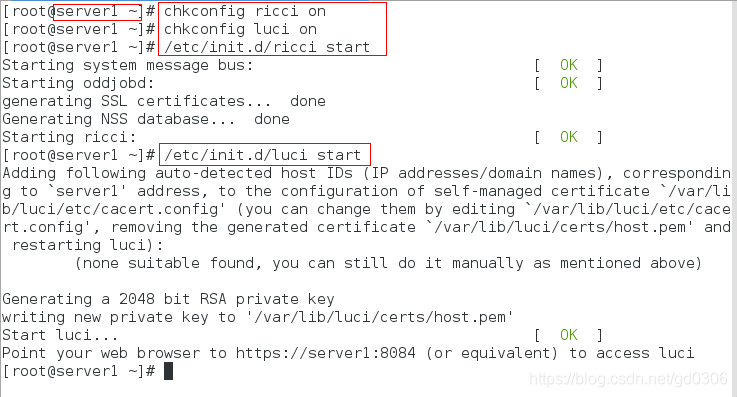
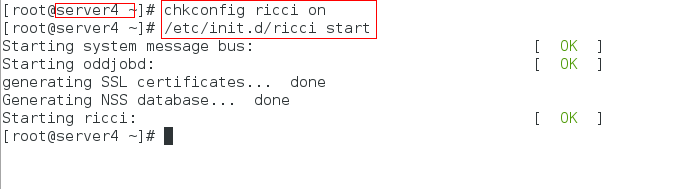
2:下载好后,将所有服务设置为开机自启动并开启服务
3:在server1和server4中给ricci设置密码

4:到物理机浏览器中输入:https://172.25.66.4:8084,进入后点击advance会出现以下界面(添加证书)
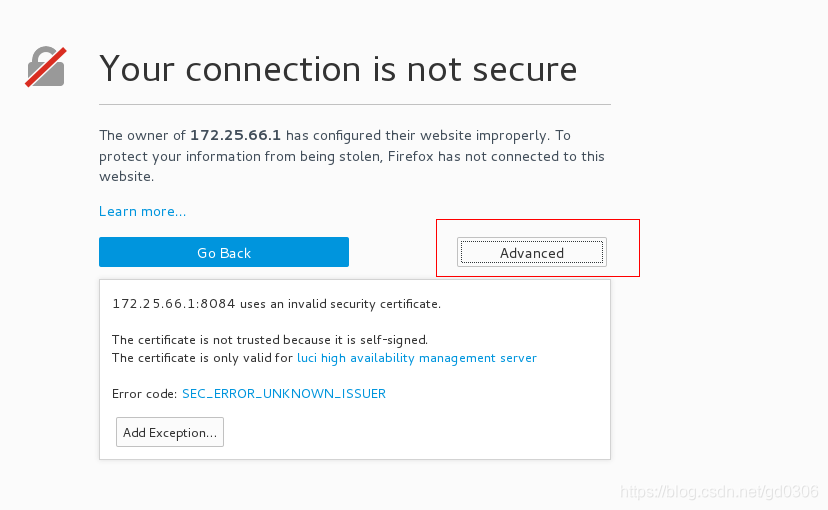
上图所示,点击左下角Add Exception会弹出以下界面:
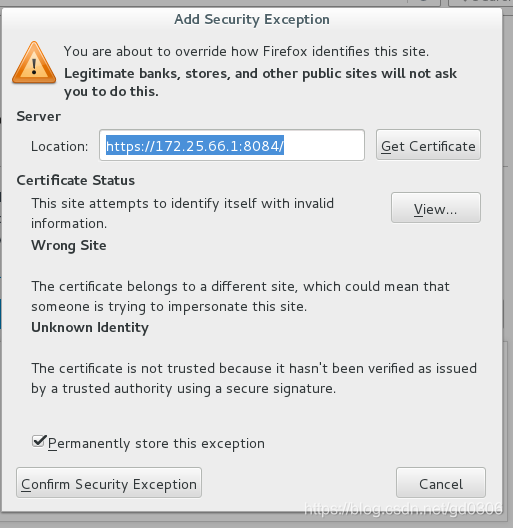
继续点击上图左下角的Confirm Security Exception 即可进入luci登陆界面:
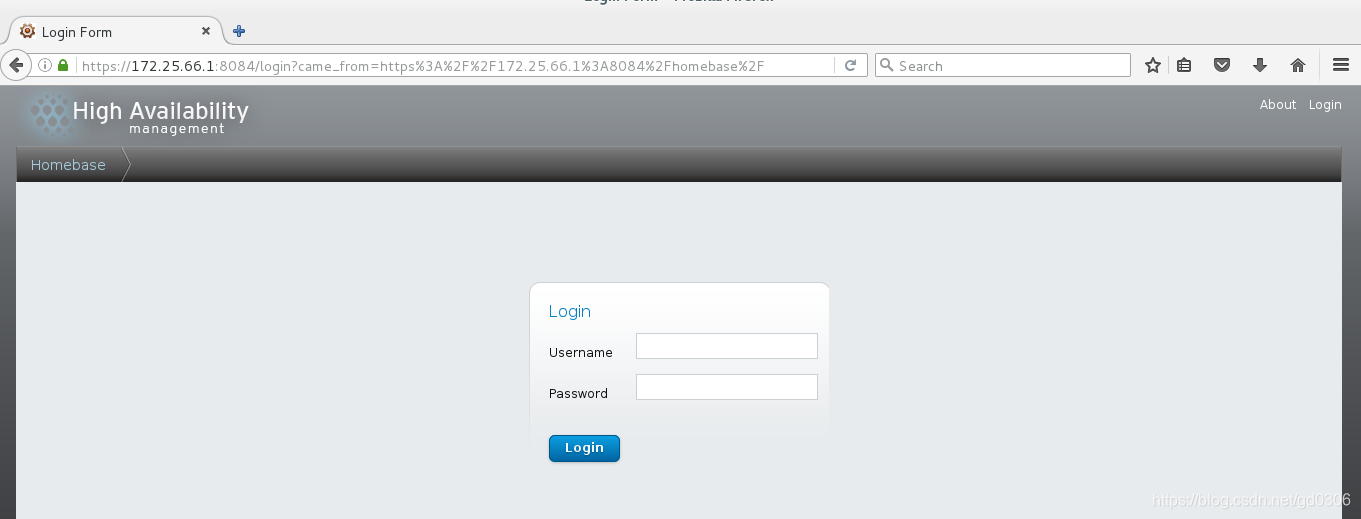
使用server1的root用户与密码登陆,进入后弹出提示,点击OK即可
二、在luci界面中配置nginx的高可用
1:进入luci界面后,选择manage Cluster一项后,点击右边的create选项创建集群
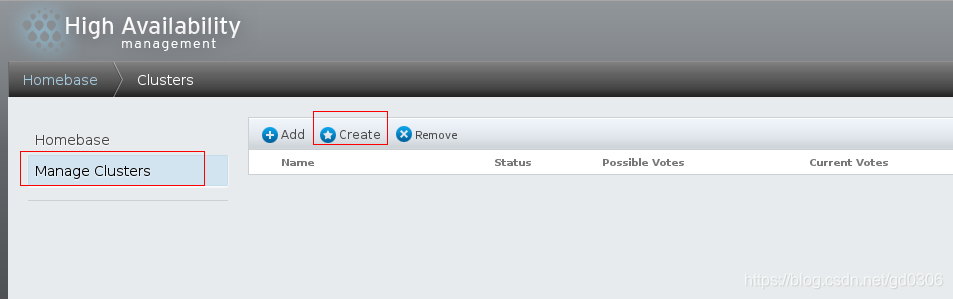
我们来创建一个名为gd_HA的集群,并将集群节点(server1与server4)添加进集群
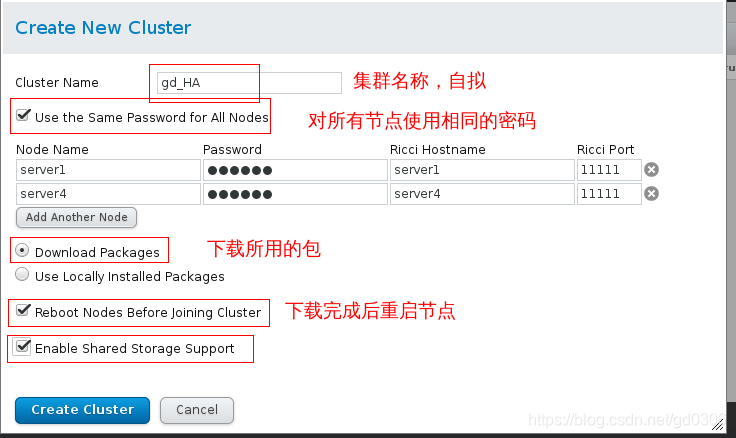
然后点击左下方的create cluster创建集群,接下来需要等待一段时间,因为要下载所需要的包,我们在server1中使用ps ax查看下载包的进程

下载完成后就会成功创建集群并将节点加进集群中
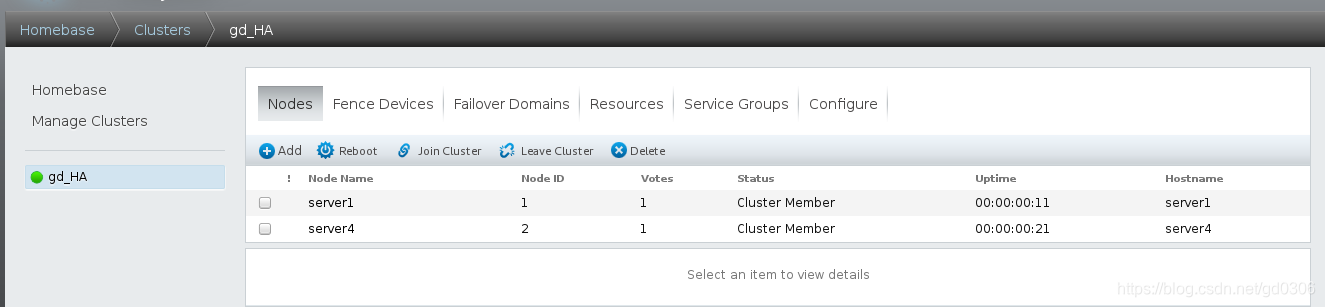
我们可以在server1和server4中使用集群管理器clustat查看节点状态

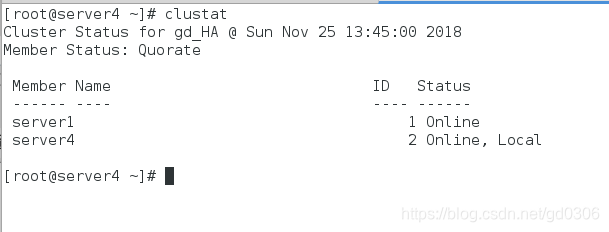
2:建立错误恢复域,将sever1和server4添加在域中,即server1或server4出现故障时,切换到正常的那一个上,集群打开后,服务落在优先级高的节点上。
点击菜单第三个Failover Domain,然后点击Add
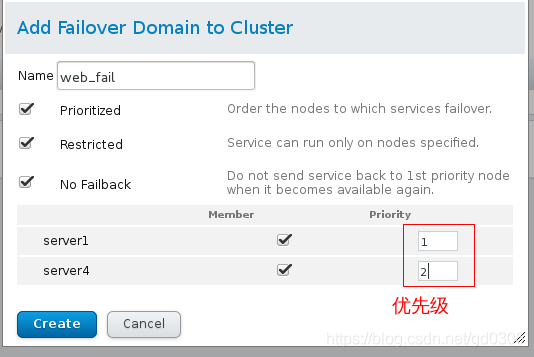
1和2表示优先级,和keepalived相反,数字越小优先级越高
点击create:
3:添加服务中所要用到的资源(以nginx高可用为例,添加VIP(集群对外虚拟IP),启动nginx服务的脚本)
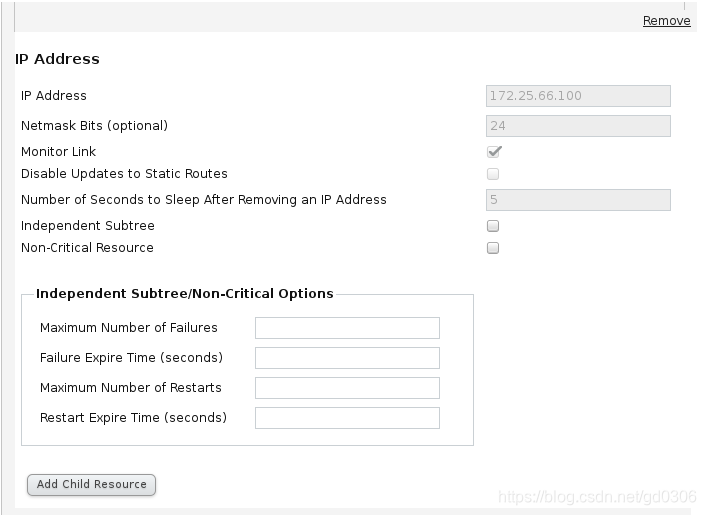
添加IP:
点击菜单第四个resource,点击Add,选择IP Address:(做这一步时,server1和4中一定要没有100(下面设置的)这个ip)
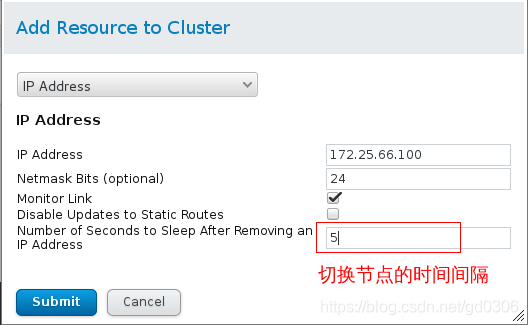
点击Submit
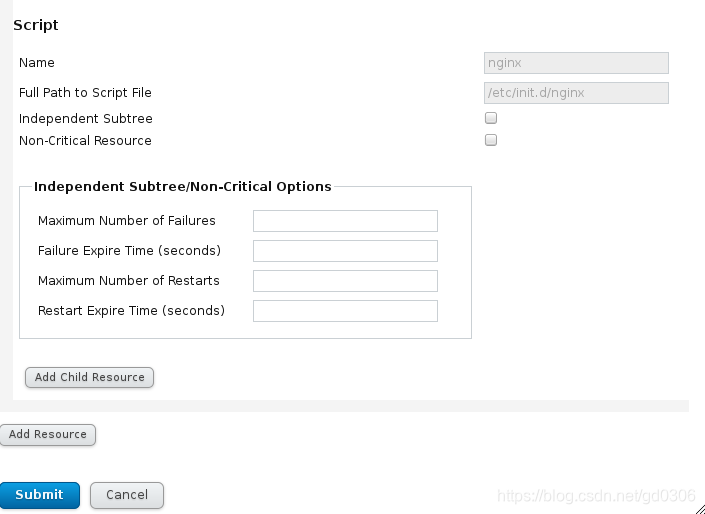
添加nginx启动脚本:
我们系统中并没有打开,关闭nginx的脚本,所以我们可以模仿httpd服务的脚本,自己编写nginx的脚本,放在server1和server4的/etc/init.d/下并且给脚本一个可执行权限,编写的脚本如下:
#!/bin/bash
# nginx Startup script for the Nginx HTTP Server
# it is v.0.0.2 version.
# chkconfig: - 85 15
# description: Nginx is a high-performance web and proxy server.
# It has a lot of features, but it's not for everyone.
# processname: nginx
# pidfile: /var/run/nginx.pid
# config: /usr/local/nginx/conf/nginx.conf
nginxd=/usr/local/nginx/sbin/nginx
nginx_config=/usr/local/nginx/conf/nginx.conf
nginx_pid=/var/run/nginx.pid
RETVAL=0
prog="nginx"
# Source function library.
. /etc/rc.d/init.d/functions
# Source networking configuration.
. /etc/sysconfig/network
# Check that networking is up.
[ ${NETWORKING} = "no" ] && exit 0
[ -x $nginxd ] || exit 0
# Start nginx daemons functions.
start() {
if [ -e $nginx_pid ];then
echo "nginx already running...."
exit 1
fi
echo -n $"Starting $prog: "
daemon $nginxd -c ${nginx_config}
RETVAL=$?
echo
[ $RETVAL = 0 ] && touch /var/lock/subsys/nginx
return $RETVAL
}
# Stop nginx daemons functions.
stop() {
echo -n $"Stopping $prog: "
killproc $nginxd
RETVAL=$?
echo
[ $RETVAL = 0 ] && rm -f /var/lock/subsys/nginx /var/run/nginx.pid
}
# reload nginx service functions.
reload() {
echo -n $"Reloading $prog: "
#kill -HUP `cat ${nginx_pid}`
killproc $nginxd -HUP
RETVAL=$?
echo
}
# See how we were called.
case "$1" in
start)
start
;;
stop)
stop
;;
reload)
reload
;;
restart)
stop
start
;;
status)
status $prog
RETVAL=$?
;;
*)
echo $"Usage: $prog {start|stop|restart|reload|status|help}"
exit 1
esac
exit $RETVAL
做好上面的操作后,再次点击Add,选择 script:
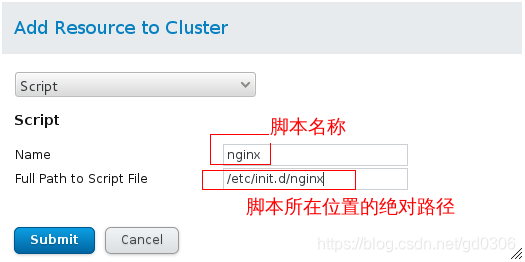
点击submit提交
4:最后,点击菜单倒数第二个Service Groups,向集群中添加上一部添加的资源。第一步是创建一个资源组(服务中要用到资源的集合)nginx,接着将资源添加进去。
点击Add:
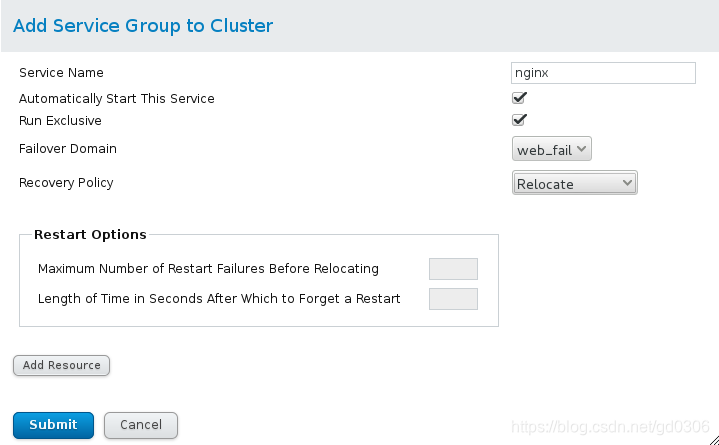
然后点击上图中左下方的Add Resource添加IP和脚本(nginx):(先添加IP再添加脚本)
点击submit提交,执行后server1和server4会出现100这个ip
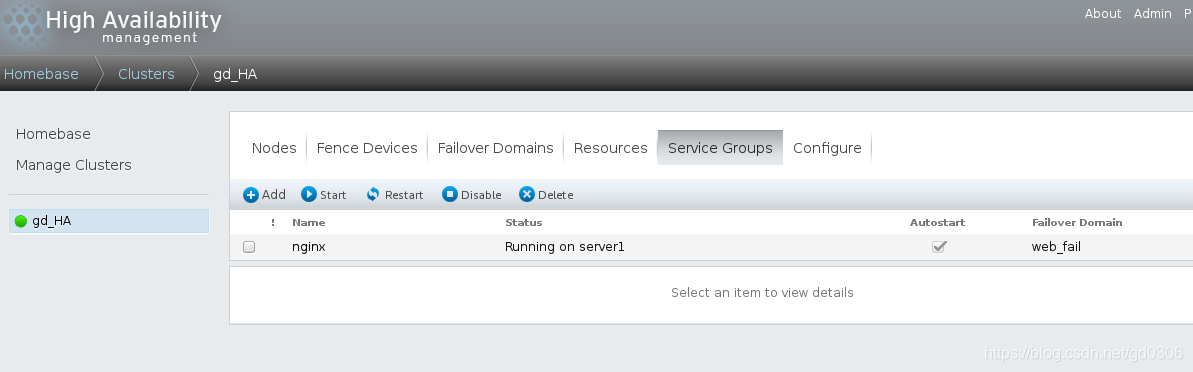

5:此时我们的nginx高可用已经做好了,在server1或4中使用clustat可以查看状态
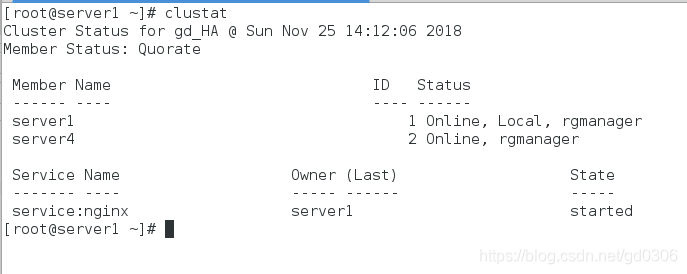
可以看到,此时正在工作的节点是server1,因为之前设置的优先级server1高于server4
6:我们可以在浏览器访问VIP
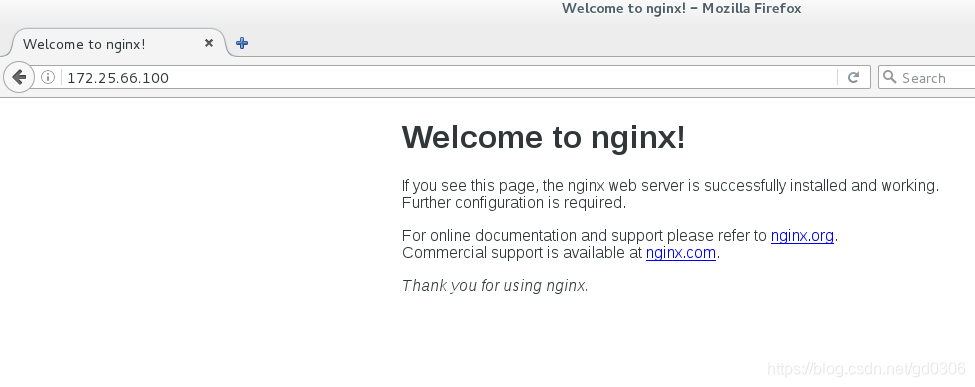
7:停掉server1上nginx的服务会发现server4取代了server1,继续提供server1上有的服务,集群处于高可用状态

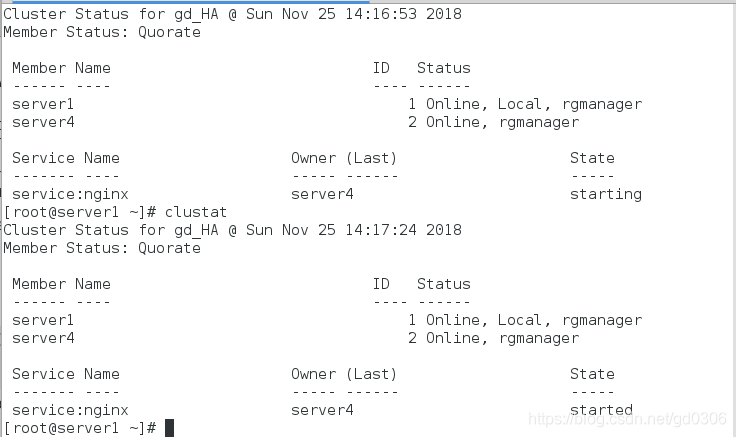
8:我们再次在浏览器中访问VIP,因为高可用的作用,依然可以访问成功
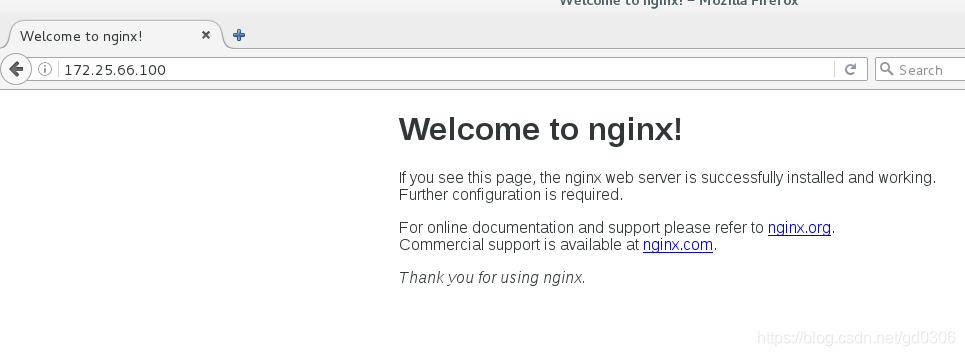
做到这一步,只是一个结点的nginx服务停了之后,另一个节点才顺利顶替,如果网络挂掉或者电源关闭,则高可用模式会出现问题,如此,我们就要使用fence来进行电源管理
FENCE设备与nginx高可用的结合
当意外原因导致主机异常或宕机时(而不是简单的停掉服务时),备用机会首先调用fence设备,然后通过fence设备将异常的主机重启或从网络上隔离,释放异常主机占据的资源,当隔离操作成功后,返回信息给备用机,备用机在接到信息后,开始接管主机的服务和资源。
fence
FENCE的原理:通过栅设备可以从集群共享存储中断开一个节点,切断I/O以保证数据的完整性。当CMAN确定一个节点失败后,它在集群结构中通告这个失败的节点,fenced进程将失败的节点隔离,以保证失败节点不破坏共享数据。它可以避免因出现不可预知的情况而造成的“脑裂”(split-brain)现象。“脑裂”是指当两个节点之间的心跳线中断时,两台主机都无法获取对方的信息,此时两台主机都认为自己是主节点,于是对集群资源(共享存储,公共IP地址)进行争用,抢夺。
RHCS的Fence设备可以分为两种:内部Fence和外部Fence。内部fence有IBM
RSAII卡,HP的ILO卡,以及IPMI设备等;外部FENCE设备有UPS,SAN switch ,Network switch等。
当节点A上的栅过程发现C节点失效时,它通过栅代理通知光纤通道交换机将C节点隔离,从而释放占用的共享存储。
当A上的栅过程发现C节点失效时,它通过栅代理直接对服务器做电源power on/off,而不是去执行操作系统的开关机指令。
配置
在物理机(真机)里面安装fence_virtd 服务:
1、使用yum search fence来查找安装包:再找到的包中安装下面3个

yum install fence-virtd.x86_64 fence-virtd-libvirt.x86_64 fence-virtd-multicast.x86_64 -y
2、编辑fence的配置文件
fence_virtd -c
一直按回车,到Interface以行,在后面输入br0回车,最后一项输入y回车
3、如果没有密钥目录,自己建立一个,并截取密钥
mkdir /etc/cluster
dd if=/dev/urandom of=fence_xvm.key bs=128 count=1

4、将修改好的密钥文件发送给高可用节点server1和server4,保证server1和server4利用的是同一个密钥
scp /etc/cluster/fence_xvm.key [email protected]:/etc/cluster
scp /etc/cluster/fence_xvm.key [email protected]:/etc/cluster
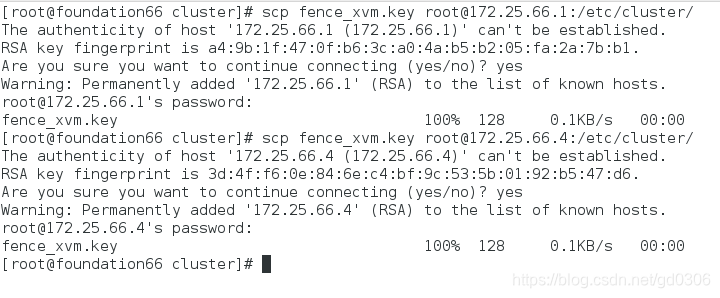
5、systemctl restart fence_virtd
6、在网页管理luci中添加FENCE,保证集群的高可用
(1)添加物理机的FENCE
add 选择 fence virt(multcast)起个名字
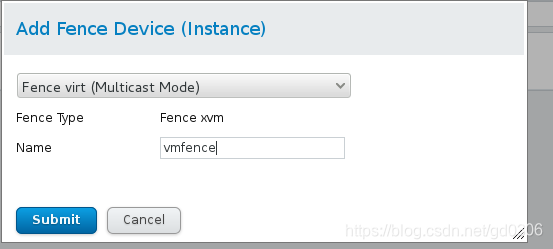
(2)在node中添加已有fence设备,分别起名为vmfence1和vmfence2
点击server1后拉到下面就会看见添加fence的地方

点击后输入名称vmfence1然后提交

接着在vmfence1中点击Add fence instance
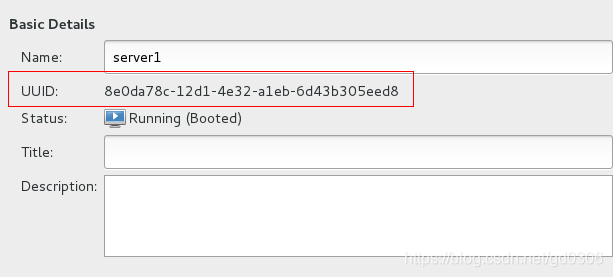
查看server1的UUID,填入domain中,提交
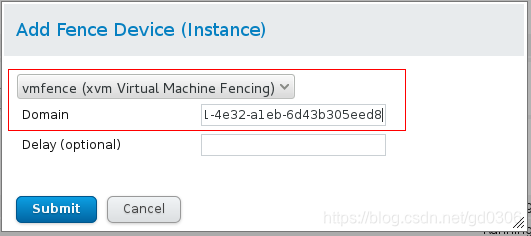
点击server4后,做同样操作,名称为vmfence2
7、在server1中执行fence_node server4,查看server1和server4是否连接成功
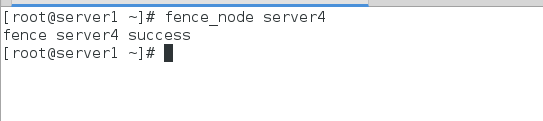
连接成功
8、现在,有了fence进行电源管理,我们在将一个节点断网或者断电之后,另一个节点就会顺利接替,在另一个节点开启后,不会因为优先级而改变正在使用的节点,必须是一个节点挂了之后另一个节点才会接替
测试:查看正在使用的节点:clustat
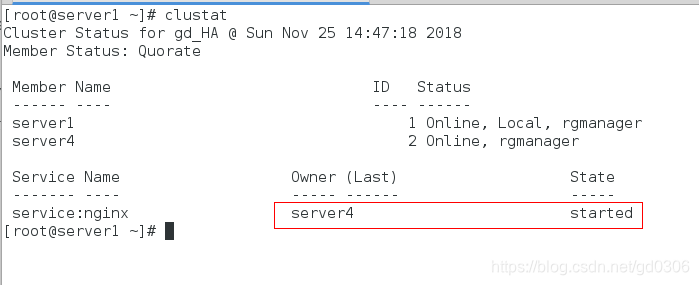
接下来我们将server4的网络关闭:

到server1中查看集群节点状态

可以看到,serevr1已经接替server4的工作,并且server4也已经自动重启并加入集群,这样我们就利用fence真正的实现了nginx的高可用集群。