RHCS(Red Hat Cluster Suite),也就是红帽子集群套件,RHCS是一个能够提供高可用性、高可靠性、负载均衡、存储共享且经济廉价的集群工具集合,它将集群系统中三大集群架构融合一体,可以给web应用、数据库应用等提供安全、稳定的运行环境。
更确切的说,RHCS是一个功能完备的集群应用解决方案,它从应用的前端访问到后端的数据存储都提供了一个行之有效的集群架构实现,通过RHCS提供的这种解决方案,不但能保证前端应用持久、稳定的提供服务,同时也保证了后端数据存储的安全。
RHCS提供了集群系统中三种集群构架,分别是高可用性集群、负载均衡集群、存储集群。
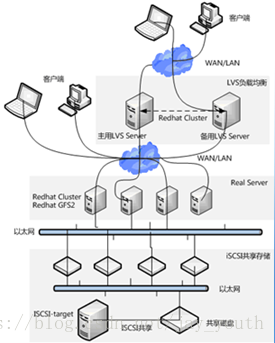
我们先来看一看如何让使用RHCS的集群架构之一:高可用性集群
一.下载工具及初始配置
1.配置好yum源之后,在server1下载RHCS的图形网页管理工具ricci(图形里的集群管理)和luci(图形界面),在server4上下载ricci

2.在server1和sever4中为ricci设置登陆密码,打开luci和ricci并设置开机自启动。

3.关闭server1和server4上的防火墙
/etc/init.d/iptables stop4.在物理机做虚拟机的解析

5.在物理机的浏览器https://server1:8084(登陆帐号和密码是server1中的系统用户和密码,普通用户需要经过超级用户的审核才能登陆,所以一般选择超级用户登陆)

二.配置实现nginx的高可用
1.登陆luci,建立集群jay_HA,并将集群节点(sevrer1和server4)添加

—-添加后需要稍等几分钟,下载所需的包,我们在进程管理中可以看到下载进程。


2.建立错误恢复域,将sever1和server2添加在域中,即server1或server2出现故障时,切换到正常的那一个上,集群打开后,服务落在优先级高的节点上。

3.添加服务中所要用到的资源(以nginx高可用为例,添加VIP(集群对外虚拟IP),启动nginx服务的脚本)
IP地址:

nginx的服务脚本:

—–我们系统中并没有打开,关闭nginx的脚本,所以我们可以模仿httpd服务的脚本,自己编写nginx的脚本,放在/etc/init.d/下,编写的脚本如下:
#!/bin/bash
# nginx Startup script for the Nginx HTTP Server
# it is v.0.0.2 version.
# chkconfig: - 85 15
# description: Nginx is a high-performance web and proxy server.
# It has a lot of features, but it's not for everyone.
# processname: nginx
# pidfile: /var/run/nginx.pid #pid文件所在的位置
# config: /usr/local/nginx/conf/nginx.conf #nginx服务的配置文件
nginxd=/usr/local/nginx/sbin/nginx
nginx_config=/usr/local/nginx/conf/nginx.conf
nginx_pid=/var/run/nginx.pid
RETVAL=0
prog="nginx"
# Source function library.
. /etc/rc.d/init.d/functions
# Source networking configuration.
. /etc/sysconfig/network
# Check that networking is up.
[ ${NETWORKING} = "no" ] && exit 0
[ -x $nginxd ] || exit 0
# Start nginx daemons functions.
start() {
if [ -e $nginx_pid ];then
echo "nginx already running...."
exit 1
fi
echo -n $"Starting $prog: "
daemon $nginxd -c ${nginx_config}
RETVAL=$?
echo
[ $RETVAL = 0 ] && touch /var/lock/subsys/nginx
return $RETVAL
}
# Stop nginx daemons functions.
stop() {
echo -n $"Stopping $prog: "
killproc $nginxd
RETVAL=$?
echo
[ $RETVAL = 0 ] && rm -f /var/lock/subsys/nginx /var/run/nginx.pid
}
# reload nginx service functions.
reload() {
echo -n $"Reloading $prog: "
#kill -HUP `cat ${nginx_pid}`
killproc $nginxd -HUP
RETVAL=$?
echo
}
case "$1" in
start)
start
;;
stop)
stop
;;
reload)
reload
;;
restart)
stop
start
;;
status)
status $prog
RETVAL=$?
;;3.向集群中添加上一部添加的资源。第一步是创建一个资源组(服务中要用到资源的集合)nginx,接着将资源添加进去。

两次添加(IP和脚本),注意每两个资源之间点的是添加资源而不是添加子资源

4.在集群主机中server1和servr2中配置nginx服务,测试良好。

5.交给集群管理server1和server4的调度(错误恢复),server1和server4中可以实现真实服务器(server2和server3)的负载均衡。

6.启动集群管理后,首先是优先级较高的server1主机得到权限负责调度
7.停掉server1上nginx的服务会发现server4取代了server1,继续提供server1上有的服务,集群处于高可用状态

三.FENCE设备与nginx高可用的结合
但是当意外原因导致主机异常或宕机时(而不是简单的停掉服务时),备用机会首先调用fence设备,然后通过fence设备将异常的主机重启或从网络上隔离,释放异常主机占据的资源,当隔离操作成功后,返回信息给备用机,备用机在接到信息后,开始接管主机的服务和资源。
FENCE的原理:通过栅设备可以从集群共享存储中断开一个节点,切断I/O以保证数据的完整性。当CMAN确定一个节点失败后,它在集群结构中通告这个失败的节点,fenced进程将失败的节点隔离,以保证失败节点不破坏共享数据。它可以避免因出现不可预知的情况而造成的“脑裂”(split-brain)现象。“脑裂”是指当两个节点之间的心跳线中断时,两台主机都无法获取对方的信息,此时两台主机都认为自己是主节点,于是对集群资源(共享存储,公共IP地址)进行争用,抢夺。
RHCS的Fence设备可以分为两种:内部Fence和外部Fence。内部fence有IBM
RSAII卡,HP的ILO卡,以及IPMI设备等;外部FENCE设备有UPS,SAN switch ,Network switch等。
当节点A上的栅过程发现C节点失效时,它通过栅代理通知光纤通道交换机将C节点隔离,从而释放占用的共享存储。
当A上的栅过程发现C节点失效时,它通过栅代理直接对服务器做电源power on/off,而不是去执行操作系统的开关机指令。
1.因为server1和server2都是虚拟机,所以选择在物理主机上安装FENCE,并打开设置开机自启动
systemctl start fence_virtd

2.编辑fence的配置文件
fence_virtd -c(1)

(2)

(3)

(4)用新的fence配置文件替换原有的

3.如果没有密钥目录,自己建立一个,并截取密钥
mkdir /etc/cluster
dd if /dev/urandom of=fence_xvm.key bs=128 count=1
4.将修改好的密钥文件发送给高可用节点server1和server4,保证server1和server4利用的是同一个密钥
scp /etc/cluster/fence_xvm.key root@172.25.1.1:/etc/cluster/
scp /etc/cluster/fence_xvm.key root@172.25.1.4:/etc/cluster/5.在网页管理luci中添加FENCE,保证集群的高可用
(1)添加物理机的FENCE

(2)在node中添加已有fence设备,分别起名为vmfence1和vmfence2


UUID是server1和server4的UUID,在虚拟机的图形管理界面可以看到

添加虚拟fence完成后:(在节点下方)

6.测试:
server4上的网络断,nginx服务不会崩溃,换server4工作(可以看到正在打开和已经打开):

而在未安装fence之前,如果某个节点的网络断掉或者宕机时,集群调度会出问题,是FENCE服务完美的解决了这个问题。