一.实验环境(rhel6.5版本)
主机环境:rhel6.5 selinux 和iptables 都必须是disabled状态
各主机信息
| 主机名 | IP | 服务 |
|---|---|---|
| server1 | 172.25.83.1 | HA1(高可用节点1:ricci) 和 管理节点(luci),作主节点 |
| server2 | 172.25.83.2 | HA2(高可用节点2:ricci),作副节点 |
| fountion真机 | 172.25.83.83 | fence集群端 |
注:
从红帽企业版 Linux 6.1 开始,您在任意节点中使用 ricci 推广更新的集群配置时要求输入密码。所以在前面两台主机安装完成ricci后需要修改ricci用户的密码,这个是后面节点设置的密码。
二.RHCS实现高可用(针对故障切换)的部署:
1.两HA节点(server1与server2)搭建高级yum源:
[rhel-source]
name=Red Hat Enterprise Linux $releasever - $basearch - Source
baseurl=http://172.25.83.83/rhel6.5
enabled=1
gpgcheck=0
[HighAvailability] #高可用
name=HighAvailability
baseurl=http://172.25.83.83/rhel6.5/HighAvailability
enabled=1
gpgcheck=0
[LoadBalancer] #负载均衡
name=LoadBalancer
baseurl=http://172.25.83.83/rhel6.5/LoadBalancer
enabled=1
gpgcheck=0
[ResilientStorage] #文件存储
name=ResilientStorage
baseurl=http://172.25.83.83/rhel6.5/ResilientStorage
enabled=1
gpgcheck=0
[ScalableFileSystem] #大文件系统
name=ScalableFileSystem
baseurl=http://172.25.83.83/rhel6.5/ScalableFileSystem
enabled=1
gpgcheck=0

server2的配置同理


2.安装ricci与luci软件:
配置server1(高可用节点与管理节点):
<1>安装ricci与luci,开启服务,设置开机自启(因为后面设置的fence经常会使机器重启,所以设置开机自启动),以及设置ricci用户密码(以便集群服务管理各节点,为每一个节点提供一个测试页面)(安装ricci后会自动生成ricci用户)
[root@server1 ~]# yum install ricci luci -y #luci是RHCS基于web的集群管理工具
[root@server1 ~]# /etc/init.d/ricci start #开启服务
[root@server1 ~]# /etc/init.d/luci start #开启服务
[root@server1 ~]# chkconfig ricci on #开机自启
[root@server1 ~]# chkconfig luci on #开机自启
[root@server1 ~]# passwd ricci #为ricci用户设置密码

![]()

<2>查看luci服务端口:netstat -antulpe
luci默认侦听端口为8084,ricci默认侦听端口为11111

配置server2(高可用节点):安装ricci并开启服务,设定ricci用户密码,设置开机自启
<1>安装ricci,开启服务,设置开机自启(因为后面设置的fence经常会使机器重启,所以设置开机自启动),以及设置ricci用户密码(以便集群服务管理各节点,为每一个节点提供一个测试页面)(安装ricci后会自动生成ricci用户)
[root@server2 ~]# yum install ricci -y
[root@server2 ~]# /etc/init.d/ricci start
[root@server2 ~]# chkconfig ricci on
[root@server2 ~]# passwd ricci

![]()

3.网页登陆集群管理并添加集群(两个HA节点)
<1>打开集群管理网页(在网页浏览器的地址栏中输入 cman 服务器的 URLluci服务器的URL语法为https://server1IP:luci_server_port。luci_server_port 的默认值为 8084 。因为server1安装luci集群管理工具)
注:一定要以https://协议开头
输入:https://172.25.83.1:8084
<2>登陆:使用正确的用户及密码就可以登陆了,如果是root用户登录会有警告提示信息。
虽然所有可以在托管 luci 的系统中认证的用户都可以登录 luci,但从红帽企业版 Linux 6.2 开始,只 有运行 luci 的系统中的 root 可以访问所有 luci 组件,除非管理员(root 用户或者有管理员权限的用 户)为那个用户设置权限。


<3>创建集群:选择Manage Clusters,点击create开始创建

//最下面两个是加入节点自动重启和支持共享存储
注意:
1、在「集群名称」 文本框中输入集群名称。集群名称不能超过 15 个字符。
如果集群中的每个节点都有同样的 ricci 密码,您可以选择「在所有 节 点中使用相同的密 码 」 ,这样就可在添加的节点中自动填写「密 码 」 字段。
2、在「 节 点名称」 栏中输入集群中节点的名称,并在「密 码 」 栏中为该节点输入 ricci 密码。
3、如果要在 ricci 代理中使用不同的端口,而不是默认的 11111 端口,可以更改那个参数。
4、如果不想要在创建集群时升级已经在节点中安装的集群软件软件包,请选择「使用本地安装的软 件包」 选项。如果要升级所有集群软件软件包,请选择「下 载软 件包」 选项。
*5、添加完成后会发现一直在等待状态,这时查看服务器,会发现server1和server2已经重启,这时只需要启动后再开启服务就成功添加节点了。
如果缺少任意基本集群组件(cman、rgmanager、modcluster 及clvmd),无论是选择「使用本地安装的 软 件包」 ,还是「下 载软 件包」 选项,都会安装它 们。如果没有安装它们,则创建节点会失败
创建好后,点击Create Cluster,提交成功后server1与server2会自动重启
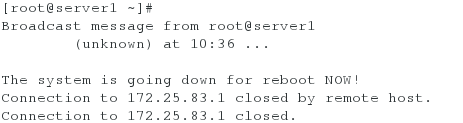
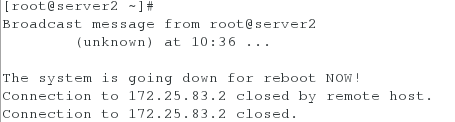
<4>检测集群是否创建成功(以server1为例,server2同理)
[root@server1 ~]# cat /etc/cluster/cluster.conf #查看集群配置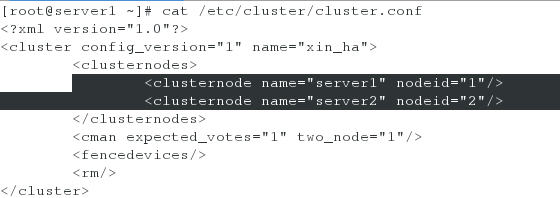
[root@server1 ~]# clustat #查看集群状态
注意:集群添加成功的前提是做好server1与server2的解析,因为创建集群时写的是主机名而不是ip,当然也可以写ip。

4.添加fence设备:点击Fence Device开始进行添加,添加完后点击Submit提交
FENCE的工作原理:
当意外原因导致主机异常或者宕机时,备机会首先调用FENCE设备,然后通过FENCE设备将异常主机重启或者从网络隔离,当FENCE操作成功执行后,返回信息给备机,备机在接到FENCE成功的信息后,开始接管主机的服务和资源。这样通过FENCE设备,将异常节点占据的资 源进行了释放,保证了资源和服务始终运行在一个节点上。

此时查看server1的集群信息文件/etc/cluster/cluster.conf,会发现vmfence(以server1为例,server2同理)

5.fountion真机上fence的安装及配置
<1>fenc的安装
[root@foundation83 Desktop]# yum install fence-virtd.x86_64 fence-virtd-libvirt.x86_64 fence-virtd-multicast.x86_64 -y

<2>进行初始化设置(其中要将接口设备改为br0,其他默认回车,最后一项输入y确定即可)
- 注:这里br0是因为虚拟服务器受主机控制的网卡是br0
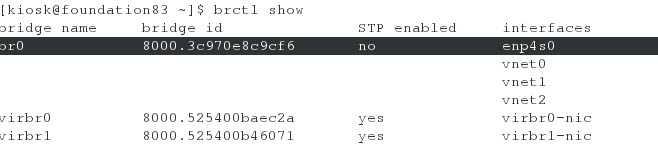
[root@foundation83 html]# fence_virtd -c

<3>生成及发送fence_xvm.key
[root@foundation83 kiosk]# mkdir /etc/cluster #建立目录
[root@foundation83 kiosk]# dd if=/dev/urandom of=/etc/cluster/fence_xvm.key bs=128 count=1 #dd截取,生成128位的fence_xvm.key,可以file查看这个key类型是数据(data),所以只能利用下面的命令来查看该文件
[root@foundation83 kiosk]# hexdump -C /etc/cluster/fence_xvm.key #查看key


[root@foundation83 kiosk]# scp /etc/cluster/fence_xvm.key [email protected]:/etc/cluster/ #给HA节点发送key
[root@foundation83 kiosk]# scp /etc/cluster/fence_xvm.key [email protected]:/etc/cluster/
6.HA节点与fence的关联
<1>关联server1节点:
点击Nodes,双击server1,接着点击Add fence Method添加fence策略,最后submit提交即可

接着点击Add Fence Instance添加fence实例,最后submit提交即可

注意:其中添加fence实例时的Domain写的server1的UUID

关联成功后:

<2>关联server2节点:
点击Nodes,双击server2,接着点击Add fence Method添加fence策略,最后submit提交即可

接着点击Add Fence Instance添加fence实例,最后submit提交即可

关联成功后:

测试fence是否搭建好:
1.fountion真机上开启fence服务
[root@foundation83 html]# systemctl start fence_virtd.service
2.通过server1使server2重启
[root@server1 ~]# fence_node server2![]()

7.配置Failover Domains(故障回切域)
<1>点击Failover Domains进行故障切换域设置,接着点击add进行添加

Restricted(只在指定节点跑)
<No Failback选项为不回切的意思,如果勾选则vip不回切,否则则会自动回切
Priority是优先级的意思,数字越小优先级越高>
到此处为止,部署基本完成,HA高可用就可以实现了,接下来我们只需要在添加资源,更具体的实现一些服务的高可用。
这里以httpd为例。
8.添加apache资源:
<1>选择Resources,点击add进行添加
(1)添加vip:
(其中5为等待时间)

注意:子网掩码要匹配,不一定都是24
(2)添加Script脚本

<1>server1与server2上安装apache服务,在/var/www/html目录下建立发布文件index.html,启动Apache服务检测是否正常显示网页,检测完成后server1和server2均关闭httpd服务;
注 : 交给集群的资源一定是屏蔽掉的,因为要交给集群去开启。
[root@server1 ~]# yum install httpd -y
[root@server1 ~]# cd /var/www/html/
[root@server1 html]# vim index.html
[root@server1 html]# cat index.html
server1
[root@server2 ~]# yum install httpd -y
[root@server2 ~]# cd /var/www/html/
[root@server2 html]# vim index.html
[root@server2 html]# cat index.html
server2
8.资源整合(添加服务组)
<1>选择Service Groups,点击add进行添加
输入一个自定义名称,例如”apache“,选中”Automatically Start This Service“(集群自动开启)和”Run Exclusive(表示运行独占(即只能在此机上运行))“,选中”Failover Domain”下刚才创建的”webfile“,”Recovery Policy”选择”Relocate“,点击下方Add Resource,选择之前创建的Resources,因为有两个,所以需要添加两次,完成后点击Submit;
节点资源添加的顺序,就是启动的顺序,所以先开启VIP,然后再启动httpd,要注意!!

接着点击Add Resource
选择前面添加过的vip和script脚本


测试:
资源整合完后,点击submit进行提交(提交前将server1与server2的http服务关掉),提交后可看到server2的http服务在跑,而且vip也在server2上(因为server2的优先级大于server1,所以服务会现在server2上跑)

在server1中关闭httpd服务用clustat命令查看效果:
正确的效果为刚开始server1的状态是started,当关闭后,等5秒钟(这个5是在故障域中设置的时间),started的主机跳到server2;
或者我们手动模拟server2节点宕机:
因为http服务与vip都在server2上,我们手动让它宕机,看vip是否回漂移到server1上,实现高可用
<1>执行命令:echo c> /proc/sysrq-trigger(手动使server2宕机)
![]()

<2>此时,vip会漂移到server1上节点

<3>但是5秒后当server2重新起来后,vip又会回切到server2上(因为我们之前设置的是自动回切)

此时clustat查看集群状态,apache服务在server2上跑

通过真机访问curl 172.25.83.100,出现server2的页面内容

这就是故障切换。
篇幅问题,下一篇将继续讲解RHCS实现HA的存储共享。