一 、关于RHCS
1. 什么是RHCS
RHCS是Red Hat Cluster Suite的缩写,也就是红帽子集群套件,RHCS是一个能够提供高可用性、高可靠性、负载均衡、存储共享且经济廉价的集群工具集合,它将集群系统中三大集群架构融合一体,可以给web应用、数据库应用等提供安全、稳定的运行环境。
更确切的说,RHCS是一个功能完备的集群应用解决方案,它从应用的前端访问到后端的数据存储都提供了一个行之有效的集群架构实现,通过RHCS提供的这种解决方案,不但能保证前端应用持久、稳定的提供服务,同时也保证了后端数据存储的安全。
RHCS提供了集群系统中三种集群构架,分别是高可用性集群、负载均衡集群、存储集群。
2. RHCS提供的三个核心功能
高可用集群是RHCS的核心功能。当应用程序出现故障,或者系统硬件、网络出现故障时,应用可以通过RHCS提供的高可用性服务管理组件自动、快速从一个节点切换到另一个节点,节点故障转移功能对客户端来说是透明的,从而保证应用持续、不间断的对外提供服务,这就是RHCS高可用集群实现的功能。
RHCS通过LVS(Linux Virtual Server)来提供负载均衡集群,而LVS是一个开源的、功能强大的基于IP的负载均衡技术,LVS由负载调度器和服务访问节点组成,通过LVS的负载调度功能,可以将客户端请求平均的分配到各个服务节点,同时,还可以定义多种负载分配策略,当一个请求进来时,集群系统根据调度算法来判断应该将请求分配到哪个服务节点,然后,由分配到的节点响应客户端请求,同时,LVS还提供了服务节点故障转移功能,也就是当某个服务节点不能提供服务时,LVS会自动屏蔽这个故障节点,接着将失败节点从集群中剔除,同时将新来此节点的请求平滑的转移到其它正常节点上来;而当此故障节点恢复正常后,LVS又会自动将此节点加入到集群中去。而这一系列切换动作,对用户来说,都是透明的,通过故障转移功能,保证了服务的不间断、稳定运行。
RHCS通过GFS文件系统来提供存储集群功能,GFS是Global File System的缩写,它允许多个服务同时去读写一个单一的共享文件系统,存储集群通过将共享数据放到一个共享文件系统中从而消除了在应用程序间同步数据的麻烦,GFS是一个分布式文件系统,它通过锁管理机制,来协调和管理多个服务节点对同一个文件系统的读写操作。
3. RHCS集群的组成
RHCS是一个集群工具的集合,主要有下面几大部分组成:
集群构架管理器
这是RHCS集群的一个基础套件,提供一个集群的基本功能,使各个节点组成集群在一起工作,具体包含分布式集群管理器(CMAN)、成员关系管理、锁管理(DLM)、配置文件管理(CCS)、栅设备(FENCE)。
高可用服务管理器
提供节点服务监控和服务故障转移功能,当一个节点服务出现故障时,将服务转移到另一个健康节点。实验环境主机配置及功能:
server1 ip 172.25.12.1 安装ricci(集群节点) 和luci(集群管理界面)
server4 ip:172.25.12.2 安装ricci(集群节点)
集群软件需要添加给yum源添加附加套件
配置好yum源以后
安装luci和ricci
luci的作用管理高可用的应用
# luci high availability management application
ricci的作用:
# description: Starts and stops Red Hat Cluster and Storage Remote Configuration Interface (ricci)
直接yum安装
#server1
yum install luci ricci -y
#server4
yum install ricci -y server1 ====>> 172.25.12.1(配置Nginx、ricci和luci)
server2 ====>> 172.25.12.2(Apache)
server3 ====>> 172.25.12.3(Apache)
server4 ====>> 172.25.12.4(配置Nginx、ricci)安装完成启动服务,关闭防火墙(iptables -F)
chkconfig ricci on ###一定要设置开机自启
chkconfig luci on server1和server4:
/etc/init.d/ricci start
server1:
/etc/init.d/luci start
注意要为ricci用户添加密码(两台都要做),这个等会创建集群的时候需要对应起来
passwd ricci添加域名解析(解析已经在母本中配置)
访问测试
在server1中启动luci服务的时候有提示:
在外部注意通过https://server1:8084进行访问
需要添加解析
因为是https访问,所以需要添加信任网络,访问到的结果如下:
登录用户为系统(server1所在主机,此例中为172.25.12.1)
创建一个集群
点击集群管理(Manager Clusters),然后点击create出现以下页面,根据实际情况填写信息即可(注意Ricci Hostname是做过解析的)add(添加一个已有的集群) create(创建一个新的集群) remove(移除已有集群)

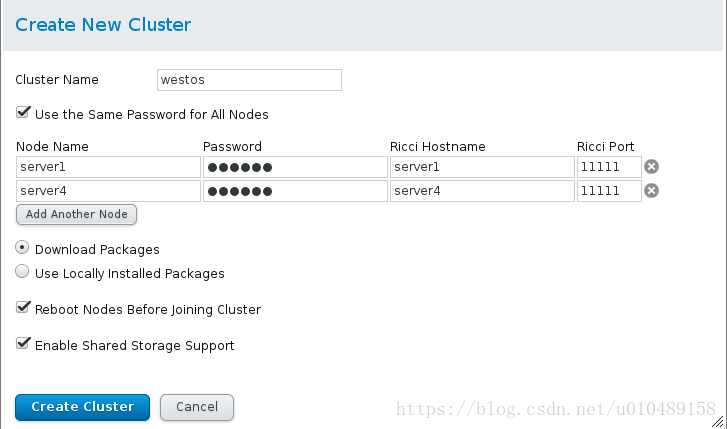
集群添加成功,这个时候在server1和server4中的/etc/cluster/cluster.conf文件中就会有一些配置写入
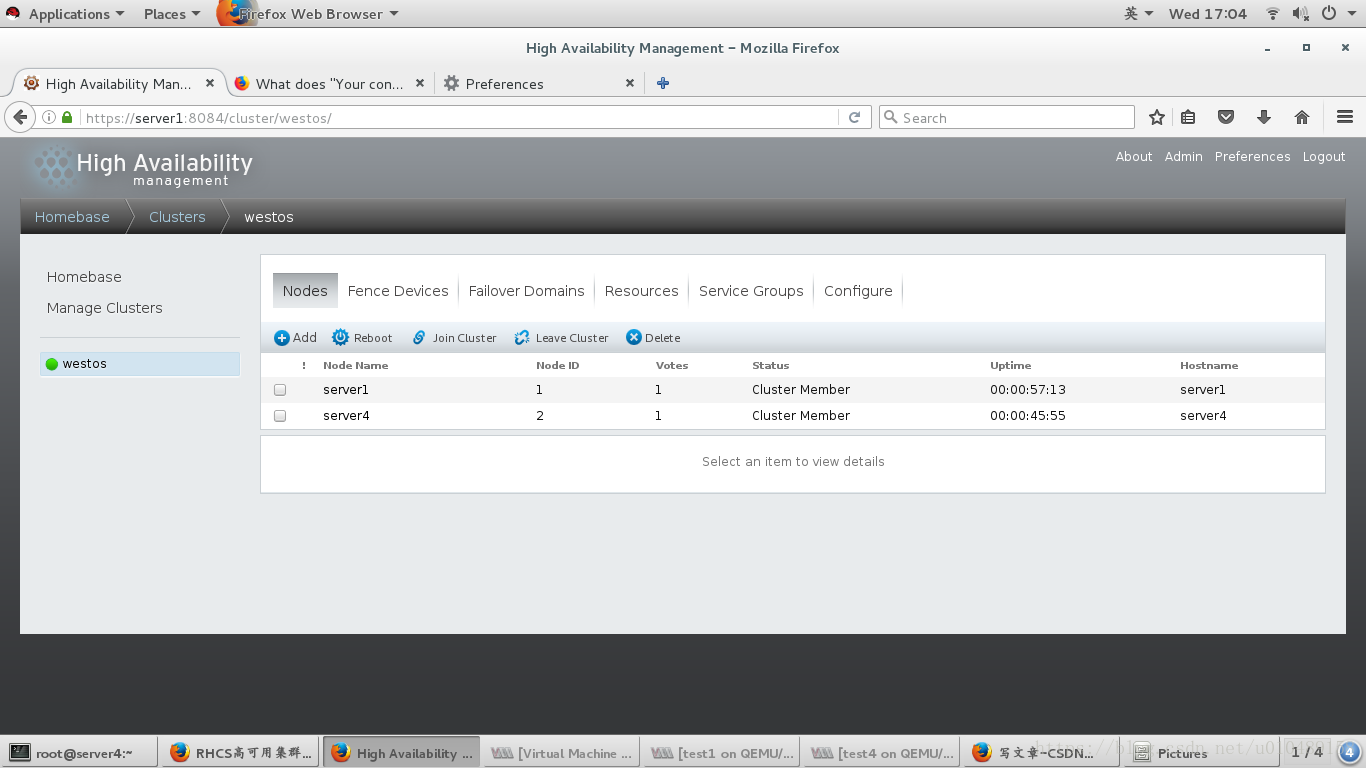
如果已经创建了集群,如果要删掉集群,需要手动清除/etc/cluster/cluster.conf配置文件,否则下次将节点加入集群的时候会提示 错误,注意如果集群创建好了之后如果某些节点运行不正常
有可能的原因:防火墙,相关服务是否启动,解析是否正确
添加服务
节点添加完以后添加服务
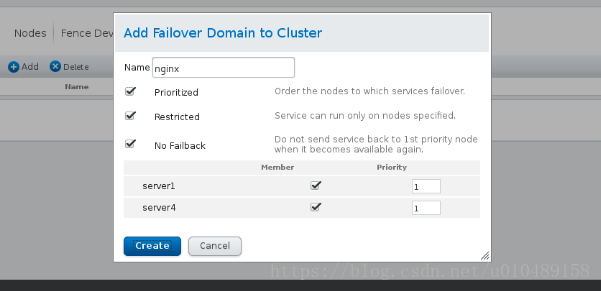
Failover Domains设置:
Resource设置:
IP address为VIP

nginx的启动脚本设置
(因为nginx服务在/etc/init.d/下没有执行脚本,需要自己编写)
将下面的脚本放下/etc/init.d/下命名为niginx
#!/bin/sh
#
# nginx - this script starts and stops the nginx daemon
#
# chkconfig: - 85 15
# description: Nginx is an HTTP(S) server, HTTP(S) reverse \
# proxy and IMAP/POP3 proxy server
# processname: nginx
# config: /usr/local/nginx/conf/nginx.conf
# pidfile: /usr/local/nginx/logs/nginx.pid
# Source function library.
. /etc/rc.d/init.d/functions
# Source networking configuration.
. /etc/sysconfig/network
# Check that networking is up.
[ "$NETWORKING" = "no" ] && exit 0
nginx="/usr/local/nginx/sbin/nginx"
prog=$(basename $nginx)
lockfile="/var/lock/subsys/nginx"
pidfile="/usr/local/nginx/logs/${prog}.pid"
NGINX_CONF_FILE="/usr/local/nginx/conf/nginx.conf"
start() {
[ -x $nginx ] || exit 5
[ -f $NGINX_CONF_FILE ] || exit 6
echo -n $"Starting $prog: "
daemon $nginx -c $NGINX_CONF_FILE
retval=$?
echo
[ $retval -eq 0 ] && touch $lockfile
return $retval
}
stop() {
echo -n $"Stopping $prog: "
killproc -p $pidfile $prog
retval=$?
echo
[ $retval -eq 0 ] && rm -f $lockfile
return $retval
}
restart() {
configtest_q || return 6
stop
start
}
reload() {
configtest_q || return 6
echo -n $"Reloading $prog: "
killproc -p $pidfile $prog -HUP
echo
}
configtest() {
$nginx -t -c $NGINX_CONF_FILE
}
configtest_q() {
$nginx -t -q -c $NGINX_CONF_FILE
}
rh_status() {
status $prog
}
rh_status_q() {
rh_status >/dev/null 2>&1
}
# Upgrade the binary with no downtime.
upgrade() {
local oldbin_pidfile="${pidfile}.oldbin"
configtest_q || return 6
echo -n $"Upgrading $prog: "
killproc -p $pidfile $prog -USR2
retval=$?
sleep 1
if [[ -f ${oldbin_pidfile} && -f ${pidfile} ]]; then
killproc -p $oldbin_pidfile $prog -QUIT
success $"$prog online upgrade"
echo
return 0
else
failure $"$prog online upgrade"
echo
return 1
fi
}
# Tell nginx to reopen logs
reopen_logs() {
configtest_q || return 6
echo -n $"Reopening $prog logs: "
killproc -p $pidfile $prog -USR1
retval=$?
echo
return $retval
}
case "$1" in
start)
rh_status_q && exit 0
$1
;;
stop)
rh_status_q || exit 0
$1
;;
restart|configtest|reopen_logs)
$1
;;
force-reload|upgrade)
rh_status_q || exit 7
upgrade
;;
reload)
rh_status_q || exit 7
$1
;;
status|status_q)
rh_$1
;;
condrestart|try-restart)
rh_status_q || exit 7
restart
;;
*)
echo $"Usage: $0 {start|stop|reload|configtest|status|force-reload|upgrade|restart|reopen_logs}"
exit 2
esac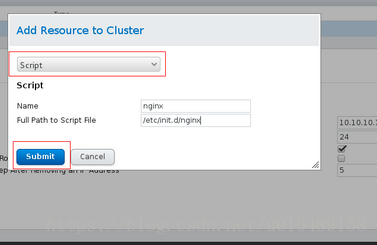
Service Group设置:

下面选择resources里面的配置
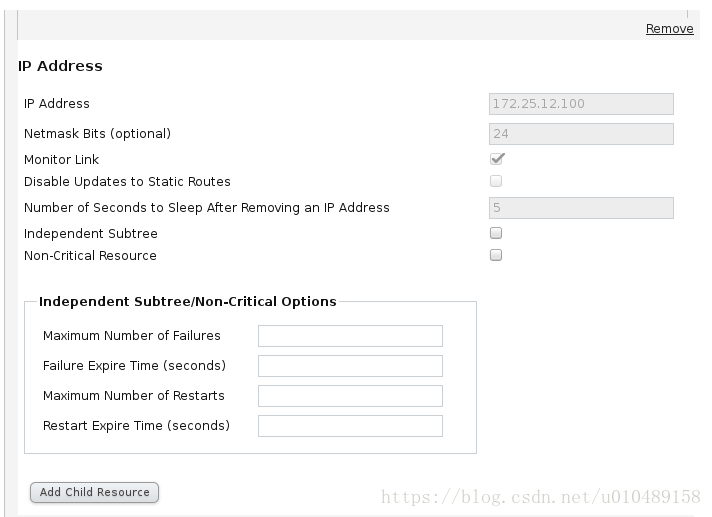
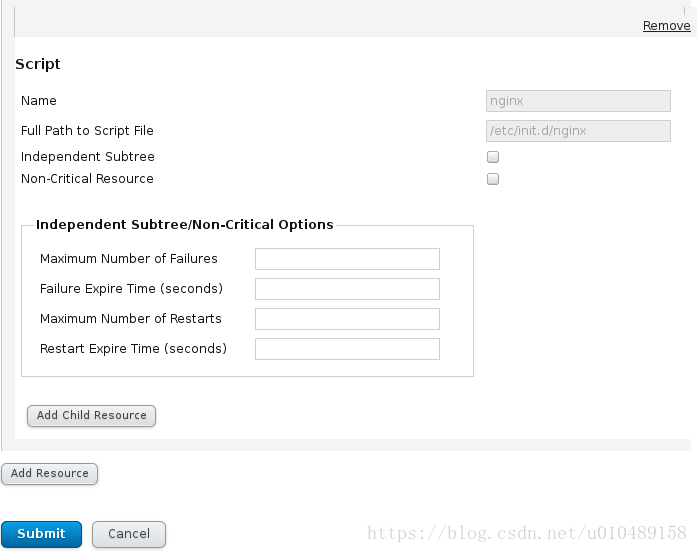
submit以后完成
添加的时候不要选成 Add Child Resource
[root@server1 init.d]# cman_tool status
Version: 6.2.0
Config Version: 5
Cluster Name: westos
Cluster Id: 25782
Cluster Member: Yes
Cluster Generation: 28
Membership state: Cluster-Member
Nodes: 2
Expected votes: 1
Total votes: 2
Node votes: 1
Quorum: 1
Active subsystems: 9
Flags: 2node
Ports Bound: 0 11 177
Node name: server1
Node ID: 1
Multicast addresses: 239.192.100.27
Node addresses: 172.25.12.1
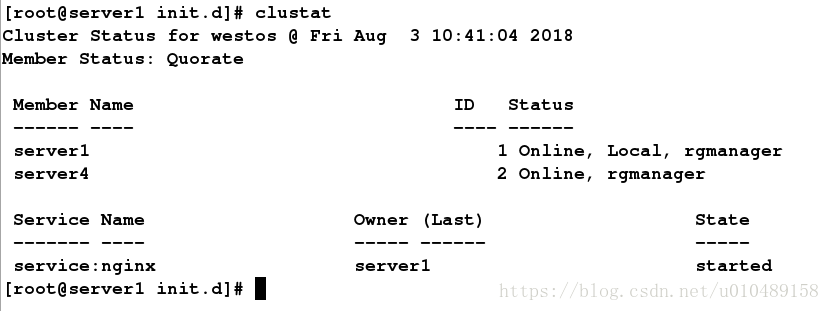
在server1中执行 clustat 可以查看集群状态
如果关闭server1的nginx服务,集群服务将会把服务转移到server4上面,并且对server1上面的nginx服务进行重新启动,启动完毕以后会重新加入到集群中
配置fence
个人理解:如果其中一台机器在运行中突然主机异常或宕机的时候,但是服务还在上面,这台服务认为自己还没有完全死亡,还依旧是主节点,但是别的主机认为它已经没有了心跳,这样便会发生冲突,两台机器对资源进行争夺,发生脑裂,fence就是会将那个异常或者宕机的机器进行隔离,断电重启,启动以后将它会重新加入到集群当中,如果没有fence那么如果出现主节点出现异常或者宕机的时候就会出现异常,这也就是它的作用
通过栅设备可以从集群共享存储中断开一个节点,切断I/O以保证数据的完整性。当CMAN确定一个节点失败后,它在集群结构中通告这个失败的节点,fenced进程将失败的节点隔离,以保证失败节点不破坏共享数据。它可以避免因出现不可预知的情况而造成的“脑裂”(split-brain)现象。“脑裂”是指当两个节点之间的心跳线中断时,两台主机都无法获取对方的信息,此时两台主机都认为自己是主节点,于是对集群资源(共享存储,公共IP地址)进行争用,抢夺。
Fence的工作原理是:当意外原因导致主机异常或宕机时,备用机会首先调用fence设备,然后通过fence设备将异常的主机重启或从网络上隔离,释放异常主机占据的资源,当隔离操作成功后,返回信息给备用机,备用机在接到信息后,开始接管主机的服务和资源。
RHCS的Fence设备可以分为两种:内部Fence和外部Fence。内部fence有IBM RSAII卡,HP的ILO卡,以及IPMI设备等;外部FENCE设备有UPS,SAN switch ,Network switch等。
当节点A上的栅过程发现C节点失效时,它通过栅代理通知光纤通道交换机将C节点隔离,从而释放占用的共享存储。
当A上的栅过程发现C节点失效时,它通过栅代理直接对服务器做电源power on/off,而不是去执行操作系统的开关机指令。
1. 在真机(不是server1或者server4)上安装fence
yum install fence-virtd.x86_64 fence-virtd-libvirt.x86_64 fence-virtd-multicast.x86_64 -y生成随机数
mkdir /etc/cluster
dd if=/dev/urandom of=/etc/cluster/fence_xvm.key bs=128 count=1 ###生成随机数key[root@foundation12 Desktop]# fence_virtd -c
Module search path [/usr/lib64/fence-virt]:
Available backends:
libvirt 0.1
Available listeners:
multicast 1.2
Listener modules are responsible for accepting requests
from fencing clients.
Listener module [multicast]: ###模式
The multicast listener module is designed for use environments
where the guests and hosts may communicate over a network using
multicast.
The multicast address is the address that a client will use to
send fencing requests to fence_virtd.
Multicast IP Address [225.0.0.12]: ###广播地址
Using ipv4 as family.
Multicast IP Port [1229]: ###端口,可以自行指定
Setting a preferred interface causes fence_virtd to listen only
on that interface. Normally, it listens on all interfaces.
In environments where the virtual machines are using the host
machine as a gateway, this *must* be set (typically to virbr0).
Set to 'none' for no interface.
Interface [br0]: br0 ###此处根据自己的网卡名进行设置
The key file is the shared key information which is used to
authenticate fencing requests. The contents of this file must
be distributed to each physical host and virtual machine within
a cluster.
Key File [/etc/cluster/fence_xvm.key]:
Backend modules are responsible for routing requests to
the appropriate hypervisor or management layer.
Backend module [libvirt]:
Configuration complete.
=== Begin Configuration ===
fence_virtd {
listener = "multicast";
backend = "libvirt";
module_path = "/usr/lib64/fence-virt";
}
listeners {
multicast {
key_file = "/etc/cluster/fence_xvm.key";
address = "225.0.0.12";
interface = "br0";
family = "ipv4";
port = "1229";
}
}
backends {
libvirt {
uri = "qemu:///system";
}
}
=== End Configuration ===
Replace /etc/fence_virt.conf with the above [y/N]? y
systemctl restart fence_virtd.service ###重启fence服务,其配置文件在/etc/fence_virt.conf
将生成的key发给server1和server4中
scp /etc/cluster/fence_xvm.key [email protected]:/etc/cluster/
scp /etc/cluster/fence_xvm.key [email protected]:/etc/cluster/添加fence模式
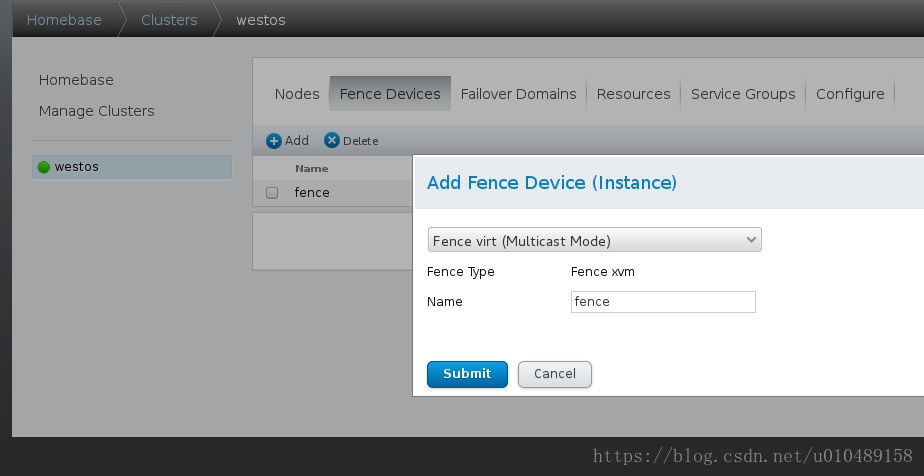
把server添加进去
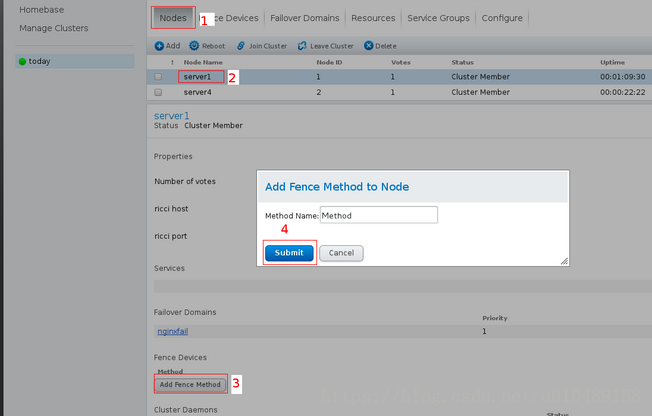
和指定虚拟机绑定
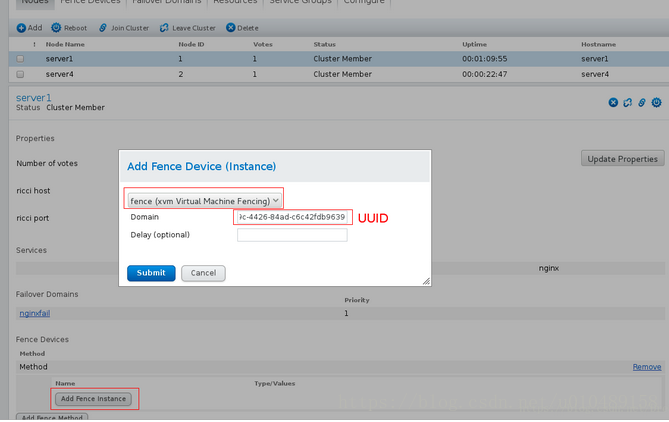
UUID的查看方法
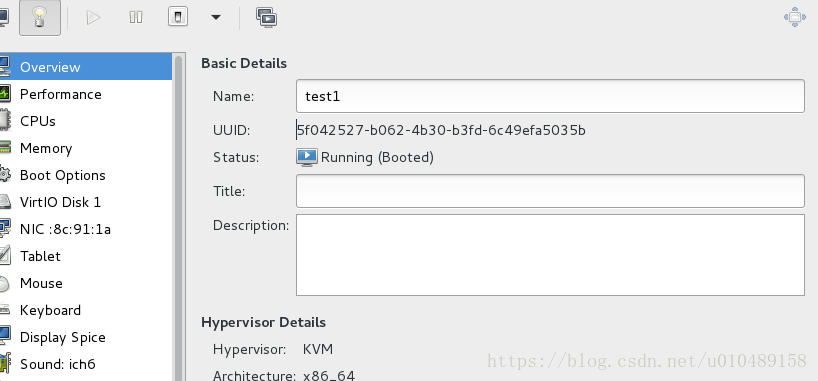
测试
当server1或者server4出现异常的时候
[root@server1 init.d]# echo c >/proc/sysrq-trigger #模拟内核崩溃
/etc/init.d/network stop #模拟网络中断当出现异常的时候,这个主机会自动进行重启并且在启动以后自动加入到集群当中