版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_32023541/article/details/84584452
之前分别介绍了朴素贝叶斯模型和隐马尔科夫模型,接下来我们解析第三大概率模型 -- 最大熵模型。说实在的,我这里不愿去写一大堆数学公式出来,即敲的累看的也累。首先介绍下数学思想:在满足一些客观真实(通过训练数据)的约束下,这样的概率模型的子集中,我们选取最大信息熵的那个模型。
我们只说下 CIS 算法的最后迭代收敛公式:
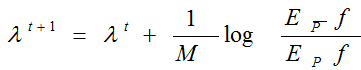
类似梯度下降原理,不断的使得模型最终的效果满足训练数据的经验分布![]() 的一个迭代训练过程。比如文本分类,data.txt 数据如下
的一个迭代训练过程。比如文本分类,data.txt 数据如下
Outdoor Sunny Happy Outdoor Sunny 5
Outdoor Sunny Happy Dry Outdoor Happy 5
Outdoor Sunny Happy Humid Outdoor Dry 2
Outdoor Sunny Sad Dry Outdoor Humid 6
Outdoor Sunny Sad Humid Outdoor Sad 4
Outdoor Cloudy Happy Humid Outdoor Cloudy 4
Outdoor Cloudy Happy Humid 获取特征===> Indoor Rainy 4
Outdoor Cloudy Sad Humid Indoor Humid 4
Outdoor Cloudy Sad Humid Indoor Happy 2
Indoor Rainy Happy Humid Indoor Dry 2
Indoor Rainy Happy Dry Indoor Sad 4
Indoor Rainy Sad Dry Indoor Cloudy 2
Indoor Rainy Sad Humid
Indoor Cloudy Sad Humid
Indoor Cloudy Sad Humid
第一列为标签,后面为文本内容根据左边的特征获取经验分布 (5/15 5/15 2/15 6/15 4/15 4/15 4/15 4/15 2/15 2/15 4/15 2/15)
然后根据模型的参数 λ 计算训练数据中每一次迭代的实际分布 ep,根据实际分布ep 和经验分布的差距更新参数 λ,迭代算法公式如上所示。当计算模型在训练数据中的分布 ep 与训练数据的经验分布误差足够小时,认为模型已经收敛。
具体代码如下所示:
# -*- coding:utf-8 -*-
# 采用 GIS 算法实现最大熵模型
import sys,os
from collections import defaultdict
import math
reload(sys)
sys.setdefaultencoding("utf-8")
# 最大熵模型
class MaxEnt(object):
def __init__(self):
self.feats = defaultdict(int)
self.trainset = [] # 训练集
self.labels = set() # 标签集
def load_data(self,file):
f = open(file)
for line in f:
fields = line.strip().split()
if len(fields) < 2:continue # 特征数要大于两列
label = fields[0] # 默认第一列为标签
self.labels.add(label)
for s in set(fields[1:]):
self.feats[(label,s)] += 1 # (标签,词)
self.trainset.append(fields)
f.close()
def _initparams(self):# 初始化参数
self.size = len(self.trainset)
self.M = max([len(record)-1 for record in self.trainset]) # GIS 训练算法的 M 参数
self.ep_ = [0.0]*len(self.feats)
for i,f in enumerate(self.feats): # 计算经验分布的特征期望
self.ep_[i] = float(self.feats[f]) / float(self.size)
self.feats[f] = i # 为每个特征分配id
self.w = [0.0]*len(self.feats)
self.lastw = self.w
def probwgt(self,features,label):# 计算 feature 属于 label 的概率权重
wgt = 0.0
for f in features:
if (label,f) in self.feats:
wgt += self.w[self.feats[(label,f)]]
return math.exp(wgt)
def Ep(self): # 特征函数
ep = [0.0]*len(self.feats)
for record in self.trainset:# 从训练集中迭代输出特征
features = record[1:]
prob = self.calprob(features) # 计算 feature 下每个标签的概率 [(概率,标签)]
for f in features:
for w,l in prob:
if (l,f) in self.feats:
idx = self.feats[(l,f)]
ep[idx] += w*(1.0/self.size)
return ep
def _convergence(self,lastw,w): # 收敛唯一终止条件
for w1,w2 in zip(lastw,w):
if abs(w1-w2) >= 0.001:return False
return True
def calprob(self,features):
wgts = [(self.probwgt(features,l),l) for l in self.labels] # 获得[(weight,label)]
Z = sum([w for w,l in wgts]) # 归一化参数
prob = [(w/Z,l) for w,l in wgts]
return prob
def train(self,max_iter = 10000): # 训练样本的主函数,默认迭代次数 10000
self._initparams()
for i in xrange(max_iter):
print 'iter %d ...' %(i+1)
self.ep = self.Ep() # 计算模型分布的特征期望
self.lastw = self.w[:]
for i,win in enumerate(self.w):
delta = 1.0 / self.M * math.log(self.ep_[i]/self.ep[i])
self.w[i] += delta # 更新 w
print self.w
if self._convergence(self.lastw,self.w): # 判断是否收敛
break
def predict(self,input):
features = input.strip().split()
prob = self.calprob(features)
prob.sort(reverse = True)
return prob
if __name__ == "__main__":
model = MaxEnt()
model.load_data("data.txt")
model.train()
print model.predict("Rainy Happy Dry")模型输出如下:
