信息
自信息
自信息的定义:
某一事件发生的自信息是它发生的概率的对数取反,即:
I(x)=−logp(x)
也就是说,如果一个事件发生的概率越大,则它发生所含有的信息越少。
独立事件的信息:
如果两个事件x和y独立,即p(xy)=p(x)p(y),则根据自信息的定义,两个事件同时发生的信息量为
I(x∩y)=I(x)+I(y)
非独立事件的信息:
如果两个事件x和y不独立,则事件y发生时事件x发生的信息量
I(x∣y)=−logp(x∣y)
互信息
I(x;y)=logp(x)p(x∣y)
由于
I(x;y)=logp(x)p(x∣y)=logp(x)p(y)p(x∣y)p(y)=logp(x)p(y)p(xy)=logp(y)p(y∣x)=I(y;x)
所以互信息具有对称性。
熵
熵的定义
熵是来自于物理学的一个概念,它是由信息论的创始人Shannon于1948年提出来的。它是对随机变量平均不确定性的度量。一个系统越有序,则信息熵越低,反之,信息熵越高。若随机变量为定值,则信息熵为0。
熵是自信息的期望。
令X表示信源,它包含有多个符号消息,各个符号消息又按概率空间的先验概率分布,各个符号的信息量不同,信息熵H(X)是从平均意义上表示信源的总体特征,表示其平均不确定性。
H(X)=E[I(X)]=x∑p(x)I(x)=−x∑p(x)logp(x)
其单位为比特/符号,容易知道
H(X)≥0
条件熵
在给定y的条件下,x的条件自信息量为I(x|y),X集合的条件熵
H(X∣y)=x∑p(x∣y)I(x∣y)
进一步,在给定Y(各个y)条件下,X集合的条件熵:
H(X∣Y)=y∑p(y)H(X∣y)=x,y∑p(y)p(x∣y)I(x∣y)=x,y∑p(x,y)I(x∣y)=−x,y∑p(x,y)log(x∣y)(已知Y,X的不确定度)
在联合符号集合XY上的条件自信息量联合概率加权平均。
联合熵
联合熵是联合符号集合XY上的每个元素x,y的自信息量概率加权平均:
H(XY)=x,y∑p(x,y)I(xy)=−x,y∑p(x,y)logp(x,y)
条件熵与联合熵之间的关系:
H(XY)=H(X)+H(Y∣X)
H(XY)=H(Y)+H(X∣Y)
熵的基本性质
- 非负性
- 对称性:熵函数的所有变量都是可以互换的,或者说它们的顺序不影响熵的值。
H(x1,x2,x3,...,xn)=H(x2,x1,x3,...,xn)
- 确定性:在信源符号表中,只要有一个符号出现的概率为1,则信源熵为0。在概率空间中,如果有两个基本事件,一个是必然事件,一个不是必然事件,因此没有不确定性,则熵为0。可以推广到n个事件组成的概率空间。
- 最大熵定理:离散无记忆信源输出M个不同的信息符号,当且仅当每个符号出现的概率相等时(
pi=1/M),熵最大:
H(X)≤H(M1,M1,...,M1)=logM
- 条件熵小于无条件熵:
H(Y∣X)≤H(Y)
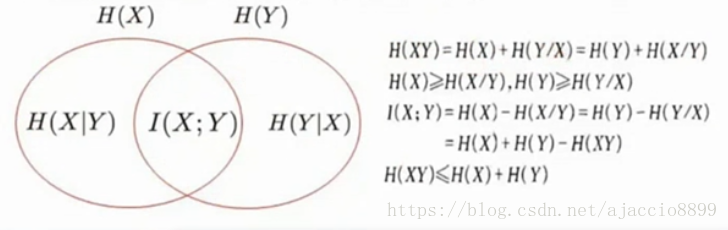
最大熵模型