版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_16137569/article/details/82560785
最大熵模型(Maximum Entropy Model,MaxEnt)是一种很经典的分类算法,理解它有助于加深我们对逻辑回归、支持向量机、决策树等算法的理解。最大熵模型是将最大熵原理应用到分类任务得到的模型 。在解释最大熵原理和最大熵模型之前,先简单对熵的概念进行一下回顾。
1. 信息熵,联合熵,条件熵
信息论的基本想法是发生一个不太可能发生的事件比发生一个非常可能发生的事件能提供更多的信息。比如说,“今天早上太阳升起”几乎一定会发生的,这句话包含的信息量很少;如果说“今天早上有日食”,日食是非常罕见的,那么这句话包含的信息量就很多了。一个事件
x = x
x
=
x
包含的信息量称为自信息 (Self-information),自信息也可以理解为事件发生之前的不确定性:
I ( x ) = − log P ( x )
I
(
x
)
=
−
log
P
(
x
)
其中log以2为底时,
I ( x )
I
(
x
)
的单位是比特或香农;log以
e
e
为底时,
I ( x )
I
(
x
)
单位是奈特,为了计算方便,本文都是自然对数。
自信息只能处理单个的输出。我们可以用香农熵(也叫
信息熵 )来对整个概率分布中的不确定性总量进行量化:
H ( x ) = E x ∼ P [ I ( x ) ] = − E x ∼ P [ log P ( x ) ] (1)
(1)
H
(
x
)
=
E
x
∼
P
[
I
(
x
)
]
=
−
E
x
∼
P
[
log
P
(
x
)
]
对于离散变量
H ( x ) = − E x ∼ P [ log P ( x ) ] = − ∑ i = 1 N P ( x i ) log P ( x i ) (2)
(2)
H
(
x
)
=
−
E
x
∼
P
[
log
P
(
x
)
]
=
−
∑
i
=
1
N
P
(
x
i
)
log
P
(
x
i
)
换而言之,一个分布的信息熵是遵循这个分布的事件所产生信息总量的期望,即所有自信息的加权平均。信息熵满足下列不等式:
0 ≤ H ( P ) ≤ log | X |
0
≤
H
(
P
)
≤
log
|
X
|
其中
| X |
|
X
|
是
X
X
取值的个数。那些接近确定的分布(输出几乎可以确定)具有较低的熵;那些接近均匀分布的概率具有较高的熵。当且仅当
X
X
的分布是均匀分布事上式右边的等号成立,所以
X
X
服从均匀分布时熵最大。
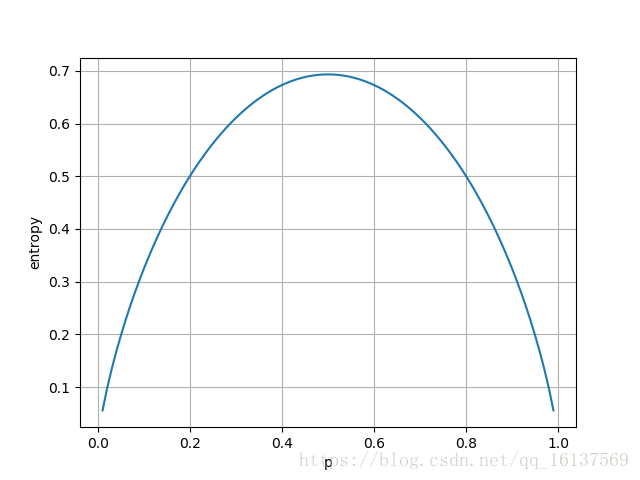
以二值随机变量为例,说明更接近确定性的分布是如何具有较低的信息熵。下图中
x
x
轴是
p
p
,表示二值随机变量等于1的概率,其信息熵由
− ( p log p + ( 1 − p ) log ( 1 − p ) )
−
(
p
log
p
+
(
1
−
p
)
log
(
1
−
p
)
)
给出。当
p
p
接近0或者1时,分布几乎是确定的,当
p = 0.5
p
=
0.5
时,是一个均匀分布,熵达到最大值1。这正好符合
ln 2 = 0.693
ln
2
=
0.693
(二值变量只有2个取值)。
该部分测试代码如下:
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(0 , 1 , 0.01 )
entropy = -1 * (x * np.log(x) + (1 - x) * np.log(1 - x))
plt.plot(x, entropy)
plt.xlabel('p' ), plt.ylabel('entropy' )
plt.grid(), plt.show() 推广到多个变量的联合熵 :
H ( X , Y ) = − ∑ i = 1 N P ( x i , y i ) log P ( x i , y i ) (3)
(3)
H
(
X
,
Y
)
=
−
∑
i
=
1
N
P
(
x
i
,
y
i
)
log
P
(
x
i
,
y
i
)
联合熵是是在联合自信息
I ( X , Y )
I
(
X
,
Y
)
的期望。
条件熵 是已知随机变量
X
X
的条件下随机变量
Y
Y
的不确定性:
H ( Y | X ) = ∑ x ∈ X P ( x ) H ( Y | X = x ) = − ∑ x ∈ X P ( x ) ∑ y ∈ Y P ( y | x ) log P ( y | x ) = − ∑ x ∈ X ∑ y ∈ Y P ( x , y ) log P ( y | x ) (4)
H
(
Y
|
X
)
=
∑
x
∈
X
P
(
x
)
H
(
Y
|
X
=
x
)
=
−
∑
x
∈
X
P
(
x
)
∑
y
∈
Y
P
(
y
|
x
)
log
P
(
y
|
x
)
(4)
=
−
∑
x
∈
X
∑
y
∈
Y
P
(
x
,
y
)
log
P
(
y
|
x
)
2. 最大熵原理
最大熵原理是概率模型学习的一个准则 。最大熵原理认为,学习概率模型时,在所有可能的概率模型(分布)中,熵最大的模型是最好的模型。如果有约束条件,最大熵原理也可以表述为在满足约束条件的模型集合中选取熵最大的模型。
X
X
的概率分布是
P ( X )
P
(
X
)
,则其熵为:
H ( x ) = − ∑ i = 1 N P ( x i ) log P ( x i )
H
(
x
)
=
−
∑
i
=
1
N
P
(
x
i
)
log
P
(
x
i
)
熵满足下列不等式:
0 ≤ H ( P ) ≤ log | X |
0
≤
H
(
P
)
≤
log
|
X
|
当
X
X
服从均匀分布时,右边等号成立,熵最大。
直观上来说,最大熵原理认为要选择的概率模型首先必须满足已有的事实,即约束条件。在没有更多信息的情况下,那些不确定的部分都是“等可能”的。最大熵原理通过熵的最大化来表示等可能性。别看说的有点玄乎,其实这在我们生活中也经常见到:比如给你一个6个面的色子,很自然的我们会认为每个面出现的概率都是
1 6
1
6
。如果已经告诉你出现“1”的概率为
1 2
1
2
,那么我们一般推测剩下5个面出现的概率都是
1 10
1
10
。做出这样推测的潜在逻辑就是,对于一个事件,不作出任何主观假设(不引入不可信的先验信息)往往是最可信的。
最大熵的思想在其他地方其实也能见到,比如我们建模选择概率分布默认比较好的选择是正态分布。其一,我们想要建模的很多分布的真实情况是比较接近正态分布的(中心极限定理,这里不展开了)。其二,在具有相同方差的所有可能的概率分布中,正态分布在实数上具有最大的不确定性,即正态分布是对模型加入的先验知识量最少的分布,这正是最大熵的思想。
3. 最大熵模型
上面讲到的最大熵原理是统计学习中的一般原理,如果将它应用到分类,就得到了最大熵模型。简单来说,最大熵模型做的事就是假设分类模型是一个条件概率分布
P ( Y | X )
P
(
Y
|
X
)
,然后利用最大熵原理选择最好的分类模型。
P ( Y | X )
P
(
Y
|
X
)
,
X ∈ R n
X
∈
R
n
表示输入,
Y ∈ R
Y
∈
R
表示输出。这个模型表示的是对于给定的输入
X
X
,以条件概率
P ( Y | X )
P
(
Y
|
X
)
输出
Y
Y
。
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x N , y N ) }
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
…
,
(
x
N
,
y
N
)
}
,首先考虑模型应该满足的条件。给定训练集,就可以确定联合分布
P ( X , Y )
P
(
X
,
Y
)
的经验分布和边缘分布
P ( X )
P
(
X
)
的经验分布,分别以
P ~ ( X , Y )
P
~
(
X
,
Y
)
和
P ~ ( X )
P
~
(
X
)
表示:
P ~ ( X , Y ) P ~ ( X ) = v ( X = x , Y = y ) N = v ( X = x ) N
P
~
(
X
,
Y
)
=
v
(
X
=
x
,
Y
=
y
)
N
P
~
(
X
)
=
v
(
X
=
x
)
N
其中
v ( X = x , Y = y )
v
(
X
=
x
,
Y
=
y
)
表示训练集中样本
( x , y )
(
x
,
y
)
出现的频数,
v ( X = x )
v
(
X
=
x
)
表示训练集中输入
x
x
出现的频数,
N
N
表示训练集样本总数。
用特征函数
f ( x , y )
f
(
x
,
y
)
描述输入
x
x
和输出
y
y
之间的关系:
f ( x , y ) = { 1 , x 和 y 满 足 某 一 事 实 0 , e l s e
f
(
x
,
y
)
=
{
1
,
x
和
y
满
足
某
一
事
实
0
,
e
l
s
e
可以认为出现在训练集中的
( x i , y i )
(
x
i
,
y
i
)
,全部有
f ( x i , y i ) = 1
f
(
x
i
,
y
i
)
=
1
,对于一个训练样本可以有多个特征函数。
特征函数
f ( x , y )
f
(
x
,
y
)
关于经验分布
P ~ ( X , Y )
P
~
(
X
,
Y
)
的期望用
E P ~ ( f )
E
P
~
(
f
)
表示:
E P ~ ( f ) = ∑ x , y P ~ ( x , y ) f ( x , y ) (5)
(5)
E
P
~
(
f
)
=
∑
x
,
y
P
~
(
x
,
y
)
f
(
x
,
y
)
特征函数
f ( x , y )
f
(
x
,
y
)
关于模型
P ( Y | X )
P
(
Y
|
X
)
和经验分布
P ~ ( X )
P
~
(
X
)
的期望用
E P ( f )
E
P
(
f
)
表示:
E P ( f ) = ∑ x , y P ~ ( x ) P ( y | x ) f ( x , y ) (6)
(6)
E
P
(
f
)
=
∑
x
,
y
P
~
(
x
)
P
(
y
|
x
)
f
(
x
,
y
)
如果模型能够从训练集中学习,那么可以假设这两个期望值相等,即
E P ~ ( f ) = E P ( f )
E
P
~
(
f
)
=
E
P
(
f
)
不知道对不对,我认为这个其实就是根据联合分布的经验分布
P ~ ( x , y )
P
~
(
x
,
y
)
去估计真实联合分布
P ( x , y )
P
(
x
,
y
)
,根据贝叶斯概率公式:
P ( x , y ) = P ( x ) P ( y | x )
P
(
x
,
y
)
=
P
(
x
)
P
(
y
|
x
)
其中
P ( y | x )
P
(
y
|
x
)
是我们的模型假设,是需要求的东西,
P ( x )
P
(
x
)
是
x
x
的边缘分布,但真实的边缘分布无从得知,所以这里用
P ~ ( x )
P
~
(
x
)
来近似
P ( x )
P
(
x
)
,所以对于(6)式有:
E P ~ ( f ) = ∑ x , y P ~ ( x , y ) f ( x , y ) ≈ ∑ x , y P ( x , y ) f ( x , y )
E
P
~
(
f
)
=
∑
x
,
y
P
~
(
x
,
y
)
f
(
x
,
y
)
≈
∑
x
,
y
P
(
x
,
y
)
f
(
x
,
y
)
现在得到模型的约束条件(如果有
n
n
个特征函数,约束条件就有
n
n
个)
∑ x , y P ~ ( x , y ) f ( x , y ) = ∑ x , y P ~ ( x ) P ( y | x ) f ( x , y ) (7)
(7)
∑
x
,
y
P
~
(
x
,
y
)
f
(
x
,
y
)
=
∑
x
,
y
P
~
(
x
)
P
(
y
|
x
)
f
(
x
,
y
)
后,我们只要找到满足(7)的模型
P ( y | x )
P
(
y
|
x
)
就大功告成。
但显然
P ( y | x )
P
(
y
|
x
)
的选取不止一种,那么如何才能确定最优的模型呢?这时就要用到第2节的最大熵原理了。最大熵原理认为熵最大的模型是最好的模型,条件分布
P ( Y | X )
P
(
Y
|
X
)
对应的条件熵为
H ( Y | X ) = − ∑ x , y P ( x , y ) log P ( y | x ) ≈ − ∑ x , y P ~ ( x ) P ( y | x ) log P ( y | x ) (8)
H
(
Y
|
X
)
=
−
∑
x
,
y
P
(
x
,
y
)
log
P
(
y
|
x
)
(8)
≈
−
∑
x
,
y
P
~
(
x
)
P
(
y
|
x
)
log
P
(
y
|
x
)
于是我们的目标转化为求使
H ( Y | X )
H
(
Y
|
X
)
最大时对应的
P ( y | x )
P
(
y
|
x
)
,求得的
P ( y | x )
P
(
y
|
x
)
称为最大熵模型。
4. 最大熵模型的学习
经过上面的分析,不难得知最大熵模型的学习其实就是一个约束最优化问题。
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x N , y N ) }
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
…
,
(
x
N
,
y
N
)
}
以及特征函数
f i ( x , y ) , i = 1 , 2 , … , n
f
i
(
x
,
y
)
,
i
=
1
,
2
,
…
,
n
,最大熵模型的学习等价于约束最优化问题:
max P s . t . H ( P ) = − ∑ x , y P ~ ( x ) P ( y | x ) log P ( y | x ) E P ( f i ) = E P ~ ( f i ) , i = 1 , 2 , … , n ∑ y P ( y | x ) = 1
max
P
H
(
P
)
=
−
∑
x
,
y
P
~
(
x
)
P
(
y
|
x
)
log
P
(
y
|
x
)
s
.
t
.
E
P
(
f
i
)
=
E
P
~
(
f
i
)
,
i
=
1
,
2
,
…
,
n
∑
y
P
(
y
|
x
)
=
1
可以改写为等价的求最小值问题:
min P s . t . − H ( P ) = ∑ x , y P ~ ( x ) P ( y | x ) log P ( y | x ) E P ( f i ) − E P ~ ( f i ) = 0 , i = 1 , 2 , … , n ∑ y P ( y | x ) = 1 (9)
(9)
min
P
−
H
(
P
)
=
∑
x
,
y
P
~
(
x
)
P
(
y
|
x
)
log
P
(
y
|
x
)
s
.
t
.
E
P
(
f
i
)
−
E
P
~
(
f
i
)
=
0
,
i
=
1
,
2
,
…
,
n
∑
y
P
(
y
|
x
)
=
1
求解约束最优化问题(9)所得出的解,就是最大熵模型学习的解。下面给出具体推导。
按照惯例,引入拉格朗日乘子
w 0 , w 1 , … , w n
w
0
,
w
1
,
…
,
w
n
,定义拉格朗日函数为:
L ( P , w ) = − H ( P ) + w 0 ( 1 − ∑ y P ( y | x ) ) + ∑ i = 1 n w i ( E P ~ ( f i ) − E P ( f i ) ) = ∑ x , y P ~ ( x ) P ( y | x ) log P ( y | x ) + w 0 ( 1 − ∑ y P ( y | x ) ) + ∑ i = 1 n ( ∑ x , y P ~ ( x , y ) f i ( x , y ) − ∑ x , y P ~ ( x ) P ( y | x ) f i ( x , y ) ) (10)
L
(
P
,
w
)
=
−
H
(
P
)
+
w
0
(
1
−
∑
y
P
(
y
|
x
)
)
+
∑
i
=
1
n
w
i
(
E
P
~
(
f
i
)
−
E
P
(
f
i
)
)
(10)
=
∑
x
,
y
P
~
(
x
)
P
(
y
|
x
)
log
P
(
y
|
x
)
+
w
0
(
1
−
∑
y
P
(
y
|
x
)
)
+
∑
i
=
1
n
(
∑
x
,
y
P
~
(
x
,
y
)
f
i
(
x
,
y
)
−
∑
x
,
y
P
~
(
x
)
P
(
y
|
x
)
f
i
(
x
,
y
)
)
对偶问题是
max w min P L ( P , w ) (11)
(11)
max
w
min
P
L
(
P
,
w
)
首先求解对偶问题(11)内部的极小化问题,记
Ψ ( w ) = min P L ( P , w ) = L ( P w , w )
Ψ
(
w
)
=
min
P
L
(
P
,
w
)
=
L
(
P
w
,
w
)
同时将其解记为
P w = arg min P L ( P , w ) = P w ( y | x )
P
w
=
arg
min
P
L
(
P
,
w
)
=
P
w
(
y
|
x
)
求
L ( P , w )
L
(
P
,
w
)
对
P ( y | x )
P
(
y
|
x
)
的偏导数并令其等于0,有:
∂ L ( P , w ) ∂ P ( y | x ) = ∑ x , y P ~ ( x ) ( log P ( y | x ) + 1 ) − ∑ y w 0 − ∑ x , y ( P ~ ( x ) ∑ i = 1 n w i f i ( x , y ) ) = ∑ x , y P ~ ( x ) ( log P ( y | x ) + 1 − w 0 − ∑ i = 1 n w i f i ( x , y ) ) = 0
∂
L
(
P
,
w
)
∂
P
(
y
|
x
)
=
∑
x
,
y
P
~
(
x
)
(
log
P
(
y
|
x
)
+
1
)
−
∑
y
w
0
−
∑
x
,
y
(
P
~
(
x
)
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
=
∑
x
,
y
P
~
(
x
)
(
log
P
(
y
|
x
)
+
1
−
w
0
−
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
=
0
解得
P w ( y | x ) = exp ( ∑ i = 1 n w i f i ( x , y ) + w 0 − 1 ) = exp ( ∑ n i = 1 w i f i ( x , y ) ) exp ( 1 − w 0 ) (12)
(12)
P
w
(
y
|
x
)
=
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
+
w
0
−
1
)
=
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
exp
(
1
−
w
0
)
又因为
∑ y P ( y | x ) = 1
∑
y
P
(
y
|
x
)
=
1
,得
P w ( y | x ) = exp ( ∑ n i = 1 w i f i ( x , y ) ) Z w ( x ) (13)
(13)
P
w
(
y
|
x
)
=
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
Z
w
(
x
)
其中
Z w
Z
w
为规范化因子
Z w ( x ) = ∑ y exp ( ∑ i = 1 n w i f i ( x , y ) ) (14)
(14)
Z
w
(
x
)
=
∑
y
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
这样就得到了
P ( y | x )
P
(
y
|
x
)
和
w
w
之间的关系,将(13-14)反代回
Ψ ( w )
Ψ
(
w
)
,这样
Ψ ( w )
Ψ
(
w
)
就是全部用
w
w
表示了。接着对
Ψ ( w )
Ψ
(
w
)
求极大,就可以得到极大化时对应的
w
w
向量的取值
w ∗
w
∗
,代入(13-14)就能得到
P w ( y | x )
P
w
(
y
|
x
)
的最终结果。
由于
Ψ ( w )
Ψ
(
w
)
是连续可导的,所以对
Ψ ( w )
Ψ
(
w
)
求极大化有很多种方法,比如梯度下降、牛顿法、拟牛顿法都可以。最大熵模型求解还有一种专用的优化方法,叫做改进的迭代尺度法(Improved Iterative Scaling, IIS)。
5. 极大似然估计
这里先简单上个结论:最大熵模型学习中的对偶函数极大化等价于最大熵模型的极大似然估计。至于证明日后再补上来,最近开始秋招实在有点忙。
6. 小结
最大熵模型在分类方法中算是比较优的模型,但是由于它的约束函数数目一般来说会随着样本量的增大而增大,导致样本量很大的时候,对偶函数的优化求解过程非常慢。