卷积神经网络的结构:
卷积神经网络是一种多层神经网络,擅长处理图像特别是大图像的相关机器学习问题。
典型的卷积神经网络如LeNet,被应用在手写字体识别上(MINST)。其网络结构如下:
LeNet结构图是一个6层网络结构:一个输入层,两个卷积层,两个下采样层(即池化层)和一个全连接层(Convolutions代表卷积层,Subsampling代表下采样层(即池化层),Full connection代表全连接层)。C5层是一个全连接层,因为C5层的卷积核大小和输入图像的大小一致,都是5*5。

总体来说,CNN通过卷积来模拟特征区分,并且通过卷积的权值共享及池化,来降低网络参数的数量级,最后通过传统神经网络完成分类等任务。
输入层:
该层要做的处理主要是对原始图像数据进行预处理,包括:
去均值:把输入数据各个维度都中心化为0,如下图所示,其目的就是把样本的中心拉回到坐标系原点上。
归一化:幅度归一化到同样的范围,如下所示,即减少各维度数据取值范围的差异而带来的干扰,比如,我们有两个维度的特征A和B,A范围是0到10,而B范围是0到10000,如果直接使用这两个特征是有问题的,好的做法就是归一化,即A和B的数据都变为0到1的范围。
PCA/白化:用PCA降维;白化是对数据各个特征轴上的幅度归一化。
卷积层:
基本名词:
深度/depth:卷积层内有多少个神经元,深度就是多少。
步长/stride:即窗口一次滑动的长度。
填充值/zero-padding:即为图像加上一个边界,边界元素均为0。(对原输入无影响)

填充值的例子:如下图,有这么一个5*5的图片(一个格子一个像素),我们滑动窗口取2*2,步长取2,那么我们发现还剩下1个像素没法滑完,如何处理?
我们在原先的矩阵上面和右边各加了一层格子,格子内的值填充为0,使得变成6*6的矩阵,那么窗口就可以刚好把所有像素遍历完。这就是填充值的运用。

卷积层的作用是进行特征提取。
在卷积层中每个神经元连接数据窗的权重是固定的,每个神经元只关注一个特性。神经元就是图像处理中的滤波器,卷积层的每个滤波器都会有自己关注的一个图像特征,比如垂直边缘,水平边缘,颜色,纹理等等,这些所有神经元加起来就好比就是整张图像的特征提取器集合。
如:

如上图,输入层输入图像大小是32*32*3,3是它的深度(即R、G、B),卷积层是一个5*5*3的滤波器(filter)。通过一个filter与输入图像的卷积可以得到一个28*28*1的特征图,上图是用了两个filter得到了两个特征图。
注意:滤波器的深度必须和输入图像的深度相同。
卷积的计算过程:
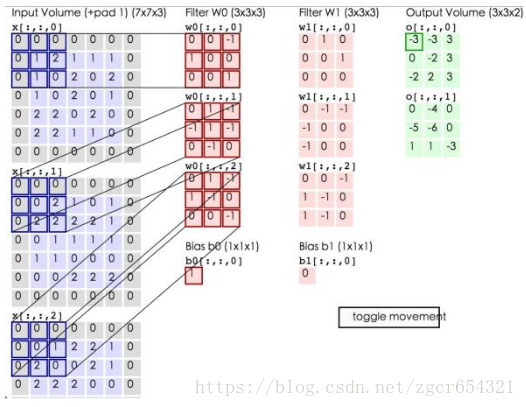
上图中,蓝色矩阵就是输入层,粉色矩阵就是卷积层的神经元,这里有两个神经元w0和w1。绿色矩阵就是经过卷积运算后的输出矩阵,这里的步长设置为2。
在这里还要注意一点,即填充值项(zero pad),加上zero pad这一项是为了使输入图像和卷积后的特征图具有相同的维度,边界的宽度是一个经验值,一般按如下取:
F=3 => zero pad with 1
F=5 => zero pad with 2
F=7=> zero pad with 3
输入图像n*n,过滤器f*f,输出图像大小为:(n−f+1)∗(n−f+1)。
如上图中输入为5*5*3,filter为3*3*3,则zero pad 为1,则加上zero pad后的输入图像为7*7*3,则卷积后的特征图大小为5*5*1((7-3)+1)*((7-3)+1),与输入图像一样。
卷积的计算方法:
输入图像和filter的对应位置元素相乘再求和,最后再加上b,得到输出矩阵的一个元素。然后输入图像的蓝色方框再滑动,依次计算出输出矩阵的所有元素值。
如,上面绿色矩阵中的-3值由下面的式子计算出:
蓝色矩阵有3个深度,深度0、1、2。各个深度的矩阵中每个元素分别与filter的w0神经元的深度0、1、2的矩阵的对应位置的元素相乘再求和。我们可以得到结果为0+(-4)+0=-4,然后再加上偏置值b为1,结果为-3。计算出矩阵的一个元素后(即卷积后)输入图像的蓝色方框再滑动。
动态显示计算过程如下:
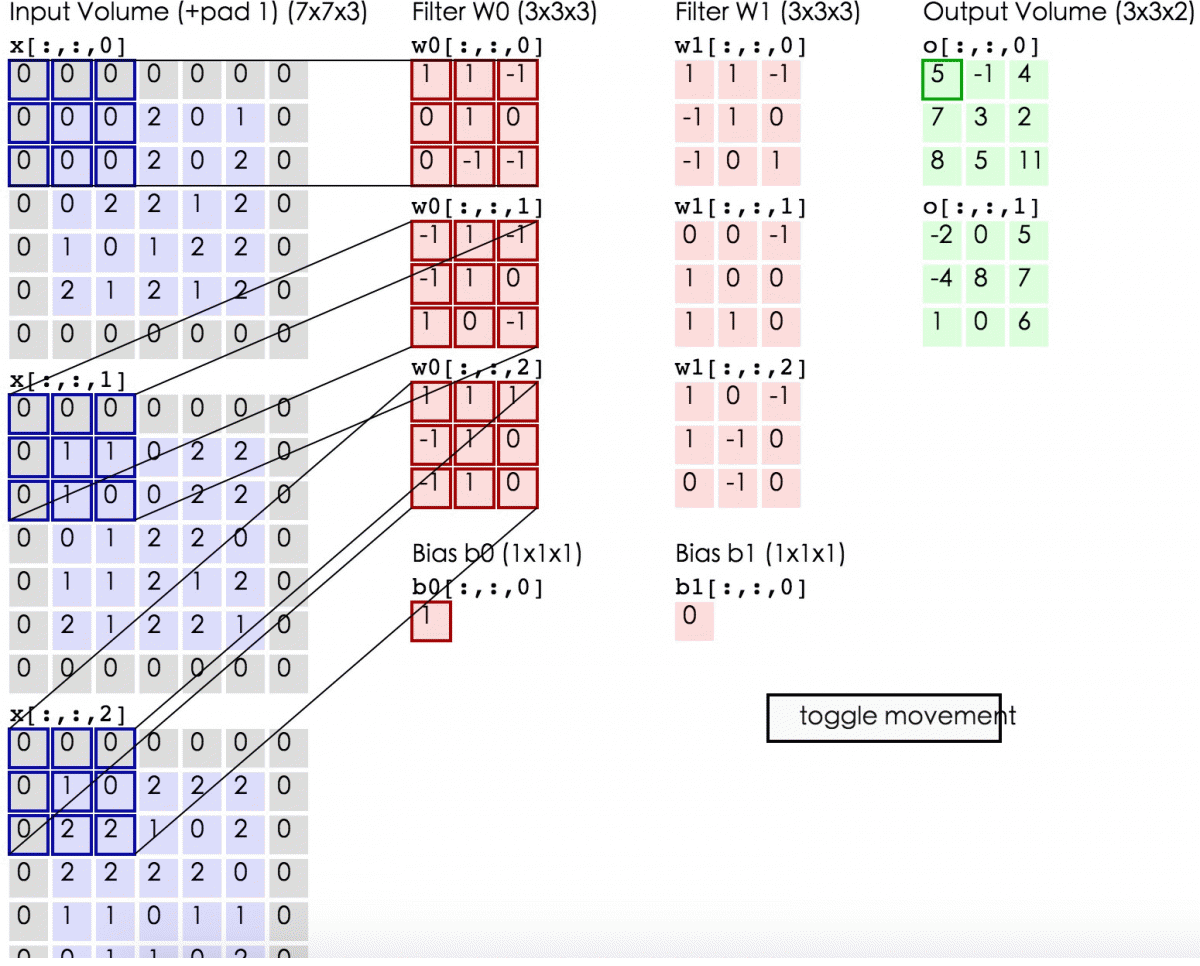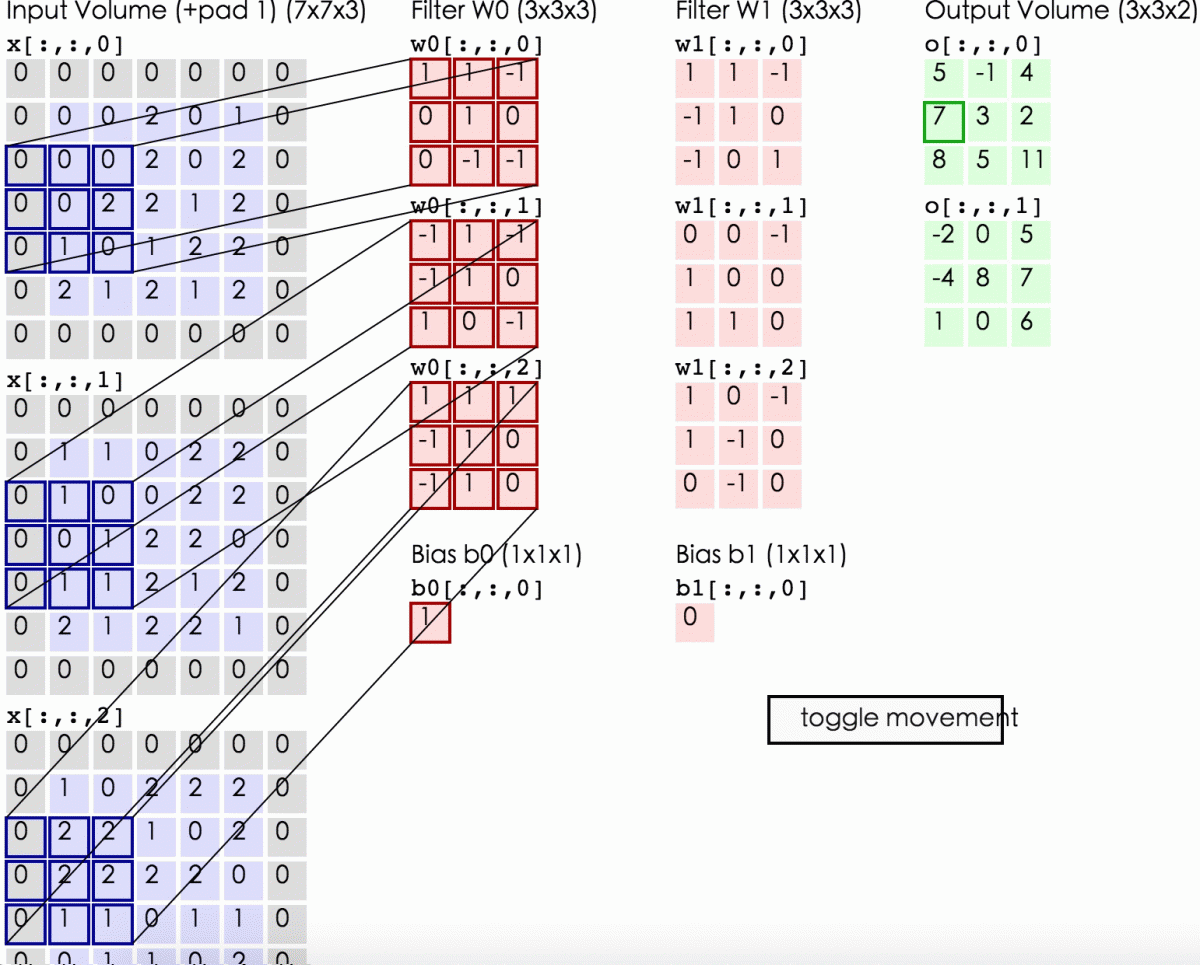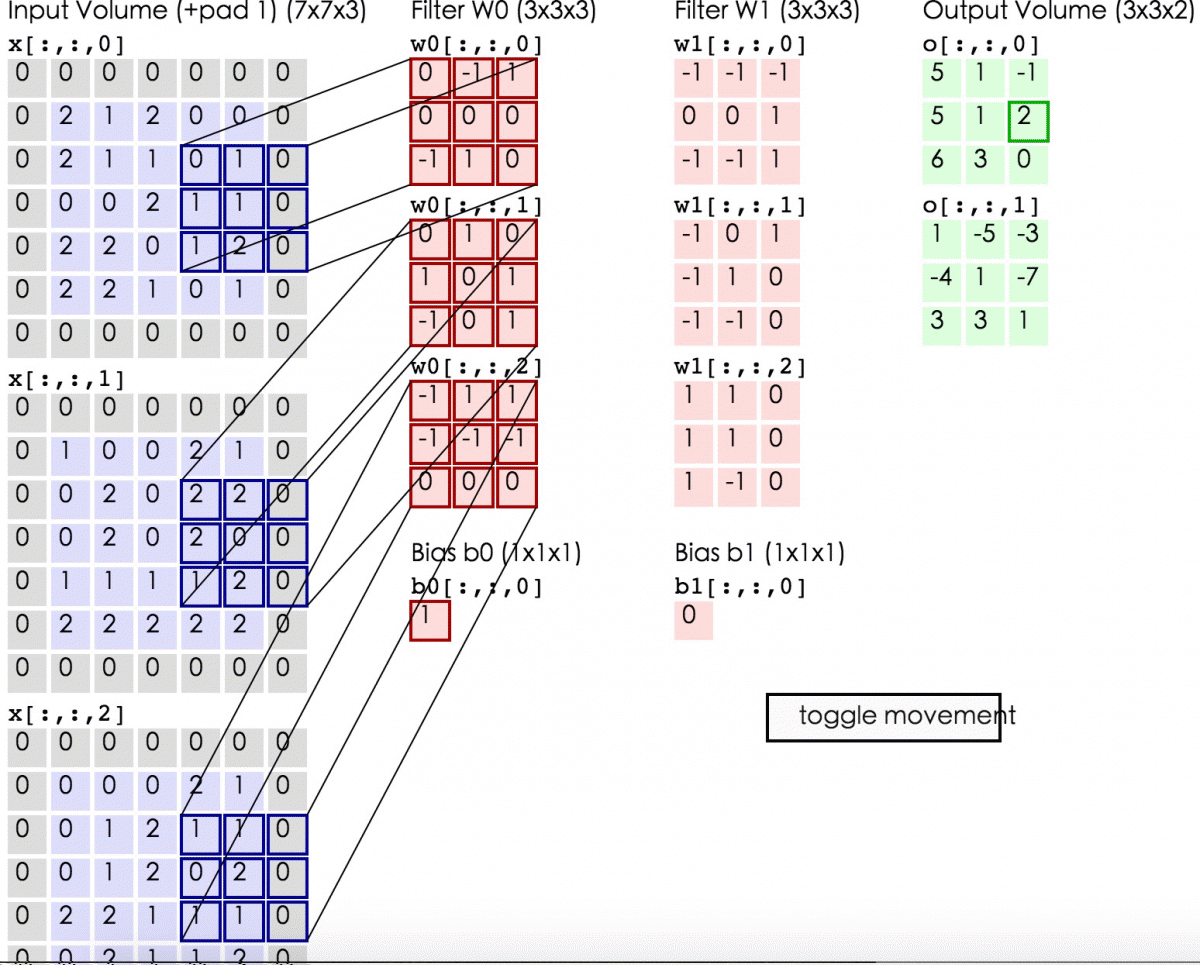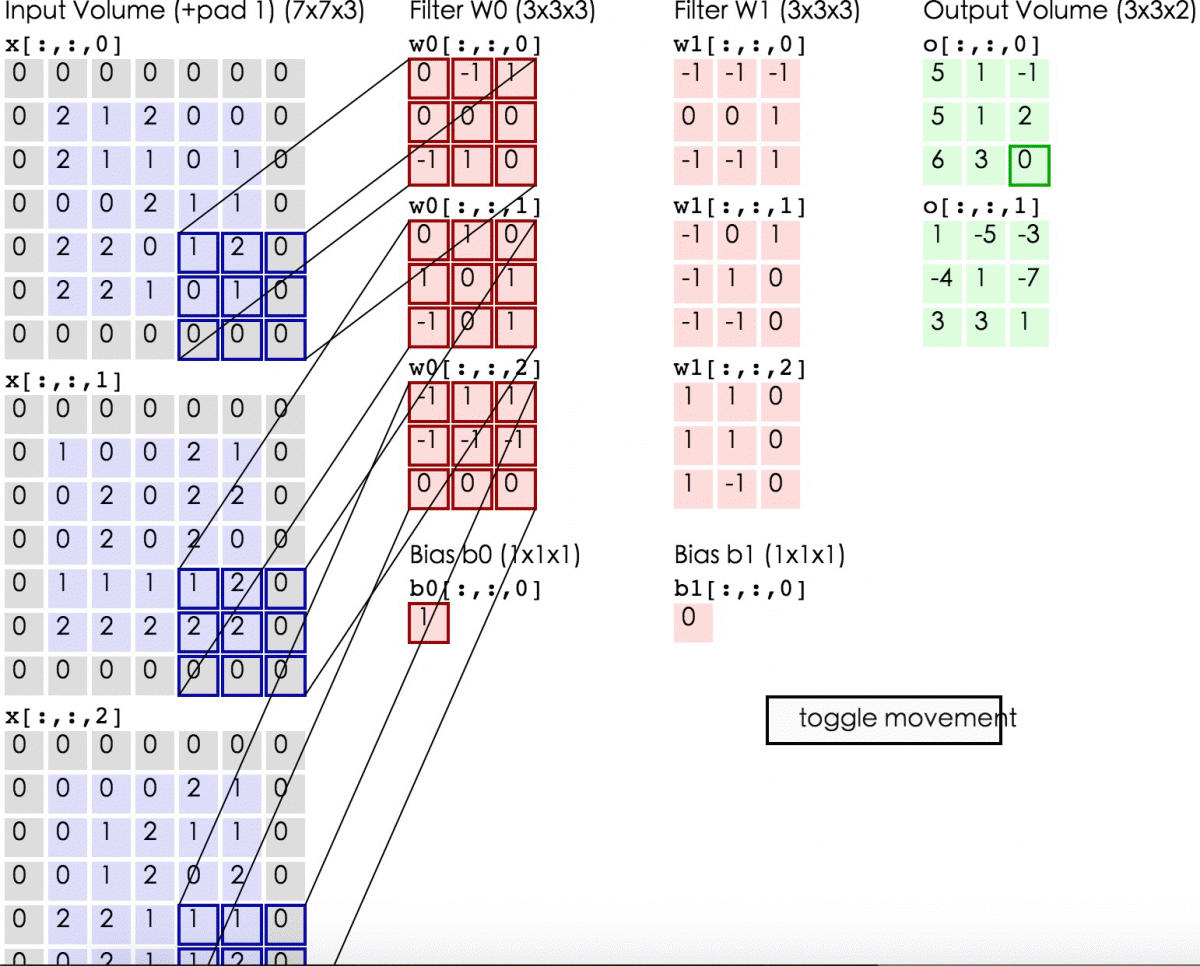
完成卷积后,我们可以得到一个3*3*2的特征图。
卷积层还有一个特性就是“权值共享”原则。
如:

如上图,输入层为32X32X3,filter为10个5X5的filters。如果没有这个原则,那么特征图由10个32*32*1的特征图组成,即每个特征图上有1024个神经元,每个神经元对应输入图像上一块5*5*3的区域,即一个神经元和输入图像的这块区域有75个连接,即75个权值参数,则共有75*1024*10=768000个权值参数,这非常复杂。
卷积神经网络引入“权值”共享原则,则一个特征图上每个神经元对应的75个权值参数被每个神经元共享,这样则只需75*10=750个权值参数,而每个特征图的阈值也共享,即需要10个阈值,则总共需要750+10=760个参数。
所谓的权值共享就是说,给一张输入的图片,用一个filter去扫这张图,filter里面的数就叫权重,这张图每个位置就是被同样的filter扫的,所以权重是一样的,也就是共享。
激活函数:
激活函数的作用就是增强整个网络的表达能力(非线性),把卷积层输出结果做非线性映射,因为线性模型的表达力有时候不够
在卷积神经网络中,最常用的激活函数是RELU(The Rectified Linear Unit)。它的特点是收敛快,求梯度简单,但较脆弱,图像如下。

一般情况下,我们使用激活函数时首先尝试RELU,如果失效,则尝试用Leaky ReLU或者Maxout。有些情况下tanh会有不错的结果,但是很少。
Leaky ReLU函数:
改善了ReLU的死亡特性,但是也同时损失了一部分稀疏性,且增加了一个超参数,目前来说其好处不太明确。

Maxout函数 :

泛化了ReLU和Leaky ReLU,改善了死亡特性,但是同样损失了部分稀疏性,每个非线性函数增加了两倍的参数。
池化层:
池化层在连续的卷积层中间, 用于压缩数据和参数的量,减小过拟合。池化层对输入的特征图进行压缩,一方面使特征图变小,简化网络计算复杂度;一方面进行特征压缩,提取主要特征。
如:

池化层的具体作用:
特征不变性:也就是我们在图像处理中经常提到的特征的尺度不变性,池化操作就是图像的resize,图像压缩时去掉的信息只是一些无关紧要的信息,而留下的信息则是具有尺度不变性的特征,是最能表达图像的特征。
特征降维:去除对我们的任务时没有太多用途或者重复的冗余信息,把最重要的特征抽取出来,这也是池化操作的一大作用。
防止过拟合:在一定程度上防止过拟合,更方便优化。
池化层的方法有Max pooling 和 average pooling,而实际用的较多的是Max pooling。
平均池化:计算图像区域的平均值作为该区域池化后的值。
最大池化:选图像区域的最大值作为该区域池化后的值。
Max pooling方法介绍:
如上图,对于每个2*2的窗口选出最大的数作为输出矩阵的相应元素的值,比如输入矩阵第一个2*2窗口中最大的数是6,那么输出矩阵的第一个元素就是6,如此类推。
全连接层:
全连接层的每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来,并将输出值送给分类器(如softmax分类器)。由于其全相连的特性,一般全连接层的参数也是最多的。全连接一般会把卷积输出的二维特征图转化成一维的一个向量。为了提升 CNN网络性能,全连接层每个神经元的激励函数一般采用ReLU函数。
如:

上图中最右边两列就是两个全连接层,在最后一层卷积结束后,进行了最后一次池化,输出了20X12X12的图像,然后通过了一个全连接层变成了1X100的向量。这其实是20*100个12*12的卷积核卷积出来的,对于输入的每一张图,用了一个和图像一样大小的核卷积,这样整幅图就变成了一个数。如果高度是20就是那20个核卷积完了之后相加求和。这样就能把一张图高度浓缩成一个数。
全连接层是高度提纯的特征,方便交给最后的分类器或者回归。由于全连接的参数实在太多,目前主流的方法是全局平均值。即最后那一层的feature map(最后一层卷积的输出结果),直接求平均值。有多少种分类就训练多少层,最后一层的十个数字就是对应的概率或者叫置信度。
softmax 可以理解为归一化,如目前图片分类有一百种,那经过 softmax 层的输出就是一个一百维的向量。向量中的第一个值就是当前图片属于第一类的概率值,向量中的第二个值就是当前图片属于第二类的概率值...这一百维的向量之和为1。softmax的输入层和输出层的维度是一样的,如果不一样,就在输入至 softmax 层之前通过一层全连接层。
卷积神经网络的优缺点:
优点:
共享卷积核,对高维数据处理无压力;
无需手动选取特征,训练好权重,即得特征,分类效果好。
缺点:
需要调参,需要大样本量,训练最好要GPU;
物理含义不明确(即我们并不知道没个卷积层到底提取到的是什么特征,而且神经网络本身是一种“黑箱模型”)。
卷积神经网络常用框架:
Caffe
源于Berkeley的主流CV工具包,支持C++,python,matlab;
Model Zoo中有大量预训练好的模型供使用。
Torch
Facebook用的卷积神经网络工具包;
通过时域卷积的本地接口,使用非常直观;
定义新网络层简单。
TensorFlow
Google的深度学习框架;
TensorBoard可视化很方便;
数据和模型并行化好,速度快。
Tensorflow搭建第一个CNN卷积神经网络实例:
我们使用MNIST库,这是一个手写体数字库,总共有 60000 张图片,其中 50000 张训练图片,10000 张测试图片。
我们还是用mnist数据集,用下面的CNN卷积神经网络来学习这个数据库,并计算对手写体数字图片识别的准确率。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
# 定义weight变量
def weight_variable(shape):
inital = tf.truncated_normal(shape, stddev=0.1)
# tf.truncated_normal(shape, mean, stddev) :shape表示生成张量的维度,mean是均值,stddev是标准差
# 这个函数产生正太分布,均值和标准差自己设定。
# 这是一个截断的产生正太分布的函数,就是说产生正太分布的值如果与均值的差值大于两倍的标准差,那就重新生成。
return tf.Variable(inital)
# 定义bias变量
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
# 创建一个常量tensor,按照给出value来赋值,可以用shape来指定其形状。value可以是一个数,也可以是一个list。
return tf.Variable(initial)
# 定义二维卷积函数,x是图片的所有参数,W是此卷积层的权重
def conv2d(x, W):
# 定义步长strides=[1,1,1,1],strides[0]和strides[3]的两个1是默认值
# 中间两个1代表padding时在x方向运动一步,y方向运动一步,padding采用的方式是SAME。
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# SAME和VALID的区别:当窗口滑到边缘时,若数据不够步长,VALID会直接舍弃这部分边缘数据,SAME则会多添加几列来满足步长,添加的填充值均为0
# 定义池化函数
def max_poo_2x2(x):
# tf.nn.max_pool(value, ksize, strides, padding, name=None)
# 第一个参数value:需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,依然是[batch,height, width, channels]这样的shape
# 第二个参数ksize:池化窗口的大小,取一个四维向量,一般是[1,height, width, 1],因为我们不想在batch和channels上做池化,所以这两个维度设为1
# 第三个参数strides:和卷积类似,窗口在每一个维度上滑动的步长,一般也是[1,stride,stride, 1]
# 第四个参数padding:和卷积类似,可以取'VALID' 或者'SAME'
# 返回一个Tensor,类型不变,shape仍然是[batch, height, width, channels]这种形式
# 输入的高度是原图片的高度,输出的高度是卷积核的数量
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
def compute_accuracy(v_xs, v_ys):
global prediction
# 使用global则对全局变量prediction进行操作
y_pre = sess.run(prediction, feed_dict={xs: v_xs, keep_prob: 1})
# 使用xs输入数据生成预测值prediction
correct_prediction = tf.equal(tf.argmax(y_pre, 1), tf.argmax(v_ys, 1))
# 对于预测值和真实值的差别
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 计算预测的准确率
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys, keep_prob: 1})
# run得到结果,结果是个百分比
return result
# 定义输入的placeholder
xs = tf.placeholder(tf.float32, [None, 784])
ys = tf.placeholder(tf.float32, [None, 10])
# 定义dropout的placeholder
keep_prob = tf.placeholder(tf.float32)
# 处理xs,把xs的形状变成[-1,28,28,1]
# -1代表先不考虑输入的图片例子多少这个维度,后面的1是channel的数量,因为我们输入的图片是黑白的
# 如果是RGB图像,那么channel是3
x_image = tf.reshape(xs, [-1, 28, 28, 1])
# -1表示reshape函数算出的数就是samples的数量,也就是我们导入例子的数量,即导入了多少张图像
# 定义卷积层的weight 和bias
# 卷积核patch的大小是5x5,黑白图片channel是1所以输入是1,输出是32个feature map
# kernel_size是(5x5),channel是1,feature_map数量32,卷积层作用就是从图片中提取feature,不同的feature_map提取不同的特征
# 32是自己取的,32也是卷积核的个数,一个卷积核生成一层feature map,提取出的图片高度也会变成32
W_conv1 = weight_variable([5, 5, 1, 32])
# bias大小是32个长度,因此我们传入它的shape为[32]
b_conv1 = bias_variable([32])
# 定义第一个卷积层,并们对h_conv1使用激活函数进行非线性处理,这里我们用的是tf.nn.relu(修正线性单元)
# 因为采用了SAME的padding方式,输出图片的大小没有变化依然是28x28,但高度变大,现在的输出大小变成28x28x32
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
# outsize为28X28X32
# 用pooling对卷积结果处理
h_pool1 = max_poo_2x2(h_conv1)
# pooling时步长为2,,故图像长宽被缩小了一半,outsize变为14X14X32
# pool就是在feature map上继续提取特征,在2x2的窗口上选择最大的值,比如[[0,1],[2,1]]经过最大池化后得到2,这就是长宽都被缩小一半的原因
# padding的same方式不变的是长宽比不是长宽,h_conv1结果的长宽不变是因为上面stride设置的两个方向步长都是1
# 定义第二层卷积
# 本层卷积核patch的大小是5x5,有32个feature map所以输入就是32
# 输出定为64
W_conv2 = weight_variable([5, 5, 32, 64])
# patch 5x5, in size 32, out size 64
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# output size 14x14x64
h_pool2 = max_poo_2x2(h_conv2)
# output size 7x7x64
# 定义全连接层fc1
# 进入全连接层时,通过tf.reshape()将h_pool2的输出值从一个三维的变为一维的数据
# -1表示先不考虑输入图片维度
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
# [n_samples, 7, 7, 64] -> [n_samples, 7*7*64]
# 7, 7, 64是三维,7 * 7 * 64是一维,降维打击了解一下
# 此时weight_variable的shape输入就是第二个卷积层展平了的输出大小: 7x7x64
# 后面的输出高度我们继续扩大,定为1024
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
# 将展平后的h_pool2_flat与本层的W_fc1相乘
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# 为了解决过拟合问题,加一个dropout处理
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 定义全连接层fc2,输入是1024,最后的输出是10个类(因为mnist数据集就是[0-9]十个数字类)
# prediction就是我们最后的预测值
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
prediction = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
# 利用交叉熵损失函数定义cost function
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction), reduction_indices=[1]))
# 用tf.train.AdamOptimizer()作为我们的优化器进行优化,使我们的cross_entropy最小
# Adam算法即(adaptive moment estimation)自适应矩估计
# 如果一个随机变量 X 服从某个分布,X 的一阶矩是 E(X),也就是样本平均值,X 的二阶矩就是 E(X^2),也就是样本平方的平均值。
# Adam 算法根据损失函数对每个参数的梯度的一阶矩估计和二阶矩估计动态调整针对于每个参数的学习速率。
# TensorFlow提供的tf.train.AdamOptimizer可控制学习速度。
# Adam 也是基于梯度下降的方法,但是每次迭代参数的学习步长都有一个确定的范围,不会因为很大的梯度导致很大的学习步长,参数的值比较稳定。
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 创建会话并初始化变量
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(1000)
# 训练时只从数据集中取100张图片来训练
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys, keep_prob: 0.5})
if i % 20 == 0:
print(compute_accuracy(mnist.test.images[:1000], mnist.test.labels[:1000]))
# 对比mnist中的training data和testing data的准确度运行结果如下:
C:\ProgramData\Anaconda3\envs\tensorflow-gpu\python.exe C:/Users/1234/Desktop/test/src/test.py
WARNING:tensorflow:From C:/Users/1234/Desktop/test/src/test.py:7: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use alternatives such as official/mnist/dataset.py from tensorflow/models.
Extracting MNIST_data\train-images-idx3-ubyte.gz
WARNING:tensorflow:From C:\ProgramData\Anaconda3\envs\tensorflow-gpu\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.
Instructions for updating:
Please write your own downloading logic.
WARNING:tensorflow:From C:\ProgramData\Anaconda3\envs\tensorflow-gpu\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use tf.data to implement this functionality.
Extracting MNIST_data\train-labels-idx1-ubyte.gz
WARNING:tensorflow:From C:\ProgramData\Anaconda3\envs\tensorflow-gpu\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use tf.data to implement this functionality.
WARNING:tensorflow:From C:\ProgramData\Anaconda3\envs\tensorflow-gpu\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py:110: dense_to_one_hot (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use tf.one_hot on tensors.
Extracting MNIST_data\t10k-images-idx3-ubyte.gz
Extracting MNIST_data\t10k-labels-idx1-ubyte.gz
WARNING:tensorflow:From C:\ProgramData\Anaconda3\envs\tensorflow-gpu\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use alternatives such as official/mnist/dataset.py from tensorflow/models.
0.096
0.675
0.821
0.877
0.901
0.908
0.922
0.937
0.942
0.942
0.949
0.954
0.954
0.957
0.957
0.957
0.962
0.959
0.966
0.966
0.962
0.967
0.966
0.967
0.971
0.969
0.968
0.971
0.969
0.971
0.971
0.971
0.973
0.975
0.973
0.975
0.977
0.972
0.977
0.976
0.976
0.977
0.976
0.978
0.978
0.978
0.976
0.978
0.977
0.975
Process finished with exit code 0要注意的是,这个代码用tensorflow-gpu运行起来比较快,因为gpu进行神经网络计算比用cpu进行神经网络计算快的多。