下面的代码主要是数据的处理,但是运行出现内存错误,或者会出现保存的flower_process_data.npy文件是空的。后面为了进行迁移学习的实验,(因为数据处理跑了两天了问题没解决),今天决定处理了两部分的图片文件,从而得到的flow_process_data.npy文件但是也很大有2个G多。最后完成了迁移学习实验,最下方有截图,但是不知道是问什么会报内存错误。下面得好好看看数据处理方面的知识。很烦的是这个内存问题到底该怎么解决??????
import glob
import os.path
import numpy as np
import tensorflow as tf
from tensorflow.python.platform import gfile
import gc
INPUT_DATA = '/PycharmProjects/fenlei/flower_dataset1/flower_photo' # 原始输入数据的目录,其有五个子目录,每个目录下保存属于该类别的所有图片
OUTPUT_DATA = './flower_dataset1/flower_processed_datadd.npy' # 将整理后的图片数据通过numpy的格式保存
# 测试数据和验证数据的比例
VALIDATION_PERCENTAGE = 10
TEST_PERCENTAGE = 10
# 读取数据并将数据分割成训练数据、验证数据和测试数据
def create_image_lists(sess, testing_percentage, validation_percentage):
# sub_dirs用于存储INPUT_DATA下的全部子文件夹目录
# X[0]中保存的是查询文件夹的路径"/home/。。/PycharmProjects/fenlei/flower_dataset/flower_photos"
# #x[1] "['sunflowers', 'daisy', 'dandelion', 'roses', 'tulips'] [] [] [] [] "
# #x[2]"['LICENSE.txt']
# # ['2720698862_486d3ec079_m.jpg', '4080112931_cb20b3d51a_n.jpg', '3858508462_db2b9692d1.jpg',"
# #
# # os.walk()查询这个路径文件里的文件
sub_dirs = [x[0] for x in os.walk(INPUT_DATA)] # os.walk() 方法用于通过在目录树中游走输出在目录中的文件名,向上或者向下
is_root_dir = True
# 初始化各个数据集
training_images = []
training_labels = []
testing_images = []
testing_labels = []
validation_images = []
validation_labels = []
current_label = 0 # 在接下来的for循环中,第一次循环时值为0,每次循环结束时加一
count = 1 # 循环计数器
# 对每个在sub_dirs中的子文件夹进行操作
for sub_dir in sub_dirs:
# 直观上感觉这个条件结构是多此一举,暂时不分析为什么要加上这个语句
if is_root_dir:
is_root_dir = False
continue # 继续下一轮循环,下一轮就无法进入条件分支而是直接执行下列语句
print("开始读取第%d类图片:" % count)
count += 1
# 获取一个子目录中所有的图片文件
extensions = ['jpg', 'jpeg', 'JPG', 'JPEG'] # 列出所有扩展名
file_list = []
# os.path.basename()返回path最后的文件名。若path以/或\结尾,那么就会返回空值
dir_name = os.path.basename(sub_dir) # 返回子文件夹的名称(sub_dir是包含文件夹地址的串,去掉其地址,只保留文件夹名称)
# 针对不同的扩展名,将其文件名加入文件列表
for extension in extensions:
# INPUT_DATA是数据集的根文件夹,其下有五个子文件夹,每个文件夹下是一种花的照片;
# dir_name是这次循环中存放所要处理的某种花的图片的文件夹的名称
# file_glob形如"INPUT_DATA/dir_name/*.extension"
file_glob = os.path.join(INPUT_DATA, dir_name, '*.' + extension)
# extend()的作用是将glob.glob(file_glob)加入file_list
# glob.glob()返回所有匹配的文件路径列表,此处返回的是所有在INPUT_DATA/dir_name文件夹中,且扩展名是extension的文件
file_list.extend(glob.glob(file_glob))
# 猜想这句话的意思是,如果file_list是 ,则不继续运行下面的数据处理部分,而是直接进行下一轮循环,
# 即换一个子文件夹继续操作
if not file_list: continue
print ("文件名列表制作完毕,开始读取图片文件")
# 将file_list中的图片文件一条一条进行数据处理
# 注意此时file_list已经变成了一个基本单位为字符串的list,list中的每个字符串存储的是一个图片的完整文件名(含路径),
# 这些图片所属的文件夹就是这一轮循环的sub_dir
for file_name in file_list:
# 以下两行是读文件常用语句
image_raw_data = gfile.FastGFile(file_name, 'rb').read()
image = tf.image.decode_jpeg(image_raw_data)
# 如果图片数据的类型不是float32,则转换之
if image.dtype != tf.float32:
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# 调整图片的尺寸,将其化为299*299,以便inception-v3模型来处理
image = tf.image.resize_images(image, [299, 299])
image_value = sess.run(image) # 提示:sess.run(image)返回image的计算结果;
# 至此, image_value类型是299*299的float32型矩阵,代表当前循环所处理的图片文件
# 随机划分数据集,通过生成一个0-99的随机数chance来决定当前循环中的图片文件划入验证集、测试集还是训练集
# np.random.randint(100)作用是随机生成在0-99间的一个数(此函数还可以指定返回的尺寸,比如可以指定返回一个x*y的矩阵,未指定尺寸则返回一个数)
chance = np.random.randint(100)
if chance < validation_percentage:
validation_images.append(image_value) # 由于一共有3670张图片,这样最终的validation_images的尺寸大致是(3670*validation_percentage%)*229*229*3
validation_labels.append(current_label) # 由于一共有3670张图片,这样最终的validation_labels的尺寸大致是(3670*validation_percentage%)*1
elif chance < (testing_percentage + validation_percentage):
testing_images.append(image_value)
testing_labels.append(current_label)
else:
training_images.append(image_value)
training_labels.append(current_label)
current_label += 1 # 注意这一行在上一个for外面,在最外层for里面;作用是在进入最外层for的下一轮循环之前,将"当前标签"加一,以表示下一个图片文件夹
print("本类图片读取完毕")
print("开始打乱训练数据集")
# 将训练数据随机打乱以获得更好的训练效果
# 注意这里已经跳出了for循环,此时的training_image尺寸大致是(3670*(100-validition_percentage-testing_percentage)%)*299*299*3
# training_labels尺寸大致是(734*(100-validition_percentage-testing_percentage)%)*1
state = np.random.get_state() # 获取随机生成器np.random的状态
np.random.shuffle(training_images) # 进行打乱操作,如果对象是多维矩阵,只对第一维进行打乱操作
np.random.set_state(state) # 将之前随机生成器的状态设置为现在随机生成器的状态,目的是让下面一行对标签的打乱和上一行图片的打乱一致
np.random.shuffle(training_labels)
print("数据集处理完毕!")
return np.asarray([training_images, training_labels,
validation_images, validation_labels,
testing_images, testing_labels])
def main():
with tf.Session() as sess:
processed_data = create_image_lists(sess, TEST_PERCENTAGE, VALIDATION_PERCENTAGE)
np.save(OUTPUT_DATA, processed_data)
# data_size = processed_data.size
# print(type(processed_data)) #输出是asarray
# print(processed_data.ndim) #数组是一维
# print(processed_data.size) #元素个数为6
# for batch in range(0,6):
#想通过循环将6个元素加到.npy文件里面防止一次性加入内存撑爆但是似乎没用卵用。。。。。。脑仁疼
# batch+=1
if __name__ == '__main__':
main()
代码主要来自下面的链接,中间有我改动的部分注释和代码
https://blog.csdn.net/umbrellalalalala/article/details/86516928#comments
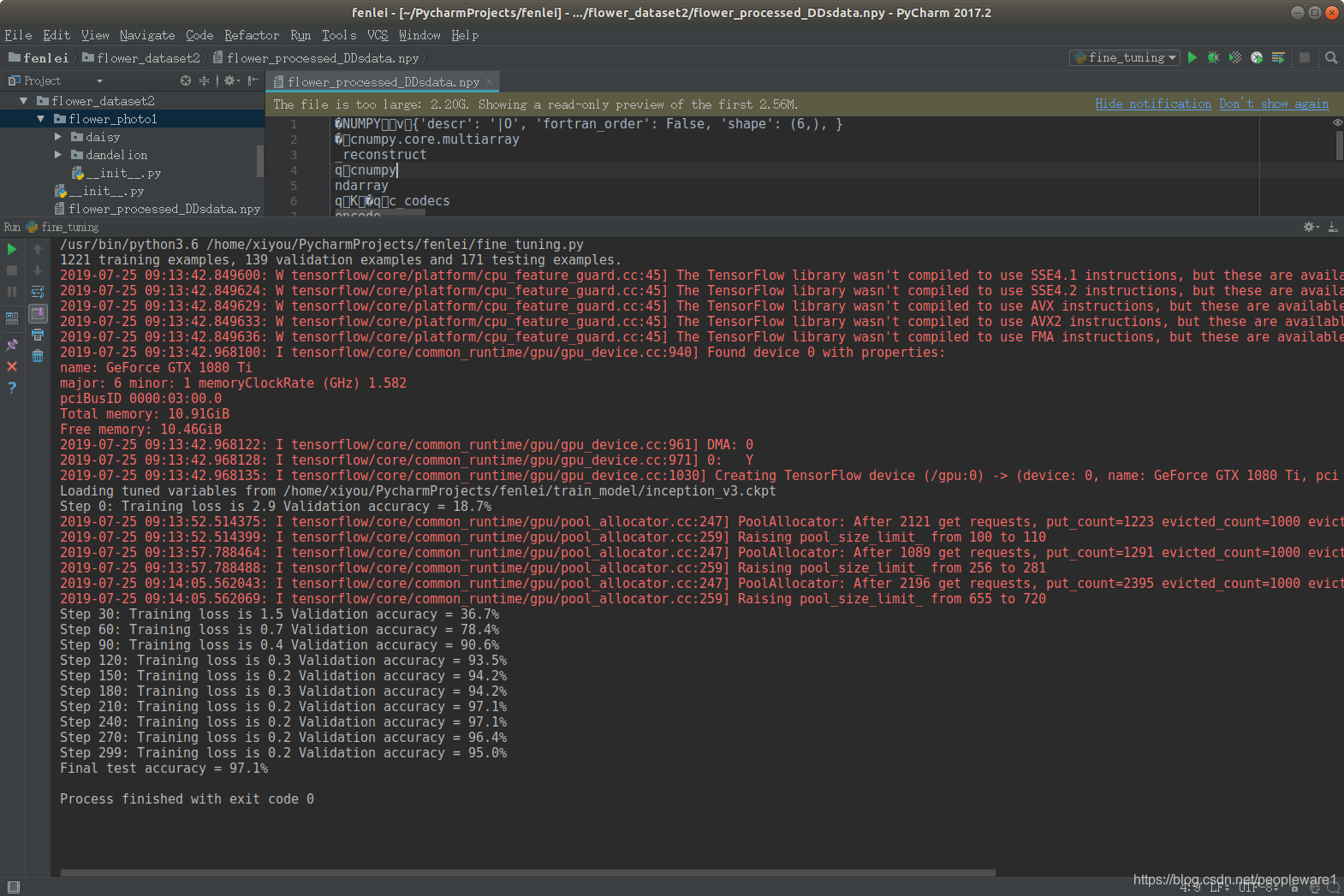 所以最后的解决方案就是将数据集删除一部分,应该是硬件的问题,不是代码的问题
所以最后的解决方案就是将数据集删除一部分,应该是硬件的问题,不是代码的问题