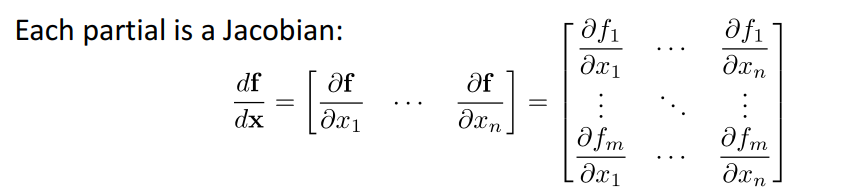首先来看一下经典的RRN的结构图,这里 x 是输入 W 是权重矩阵 (RNN的权重矩阵是共享的所以都是W) h 是隐藏状态 y是输出
RNN简单公式定义
ht=W∗f(ht−1)+W(hx)∗x[t] yt=W(S)∗f(ht) 其中,ht表示 t 时刻的隐藏状态 x[t] 表示 t 时刻的输入 yt 表示 t 时刻的输出。我们记总体的error为 E 那么 E 有如下表达式: E=t=1∑T∂W∂Et 总体的误差是所有时刻 t 的误差的累加。那么继续往下展开, 根据链式法则: ∂W∂Et=k=1∑t∂yt∂Et∂ht∂yt∂hk∂ht∂W∂hk 继续往下展开有: ∂hk∂ht=j=k+1∏t∂hj−1∂hj 注意到:ht=W∗f(ht−1)+W(hx)∗x[t],上式的每个偏导其实是一个Jacobian式
考虑Jacobians的范数,令: ∣∣∂hj−1∂hj∣∣≤∣∣WT∣∣∗∣∣diag[f′(hj−1)]∣∣≤βw∗βh 其中,βw,βh 表示正则化的上界。将上式回代到连乘的式子得: ∣∣∂hk∂ht∣∣=∣∣j=k+1∏t∂hj−1∂hj∣∣≤(βw∗βh)t−k 这里得 t 表示 time-step,也就是序列越长t会越大,即就变成了长期依赖的问题。注意到(βw∗βh)t−k 这项其实与矩阵的W的初始化有关,假设初始化一些非常小的数,W的范数也会变得很小,也就是βw会变得比较小,那么随着t的增长,这一指数项会趋近于0而导致梯度消失,相反,如果初始化成为大于1的数,则随着t的增长,会导致梯度爆炸。