为什么会梯度爆炸或梯度消失:
梯度爆炸指的是在训练时,累计了很大的误差导数,导致神经网络模型大幅更新。这样模型会变得很不稳定,不能从训练数据中很好的进行学习。极端情况下会得到nan.
会发生这个的原因是在神经网络层间不断的以指数级在乘以导数。
补充:雅克比矩阵 -- 函数的一阶偏导数以一定方式排列成的矩阵,举个例子:
 可以看到,除对角线元素外,其他元素都是0.而对角线上的元素值就是对应的y与x的一阶偏导数值。
可以看到,除对角线元素外,其他元素都是0.而对角线上的元素值就是对应的y与x的一阶偏导数值。
RNN部分:
在反向传播时,要求误差函数对W的导数
 E是误差函数,表示对所有时刻t的权重偏导数求和
E是误差函数,表示对所有时刻t的权重偏导数求和
使用链式推导展开可知,上式可以表示为:

说明: E就是输出值y与真值之间的函数,而y又由ht线性变换然后过激活函数得到;ht由输入和之前的hk的函数得到,hk与药训练的参数W有函数关系
这里面比较关键的就是ht与hk的偏导数关系
继续使用链式推导可以知道,
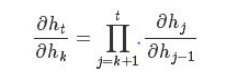
对上式再展开一点,令![]()
则
而 其实就是W矩阵
其实就是W矩阵
所以 (diag表示雅克比矩阵的对角线)
(diag表示雅克比矩阵的对角线)
当序列长度越长,对一个序列反向传播的每一步都要计算一个连乘项
 也就是W的连乘
也就是W的连乘
当W<1或W>1时,很容易因为连乘的指数增长而发生梯度消失和梯度爆炸
梯度消失与梯度爆炸和激活函数:
常用的激活函数sigmoid和tanh
在梯度很小火梯度很大时,函数都是很平滑的,很容易导致越往后训练,梯度几乎不变。因此产生了梯度消失或梯度爆炸的问题
解决梯度爆照和梯度消失问题:
几个tricks:
1、gradient clipping:


2、逆置输入
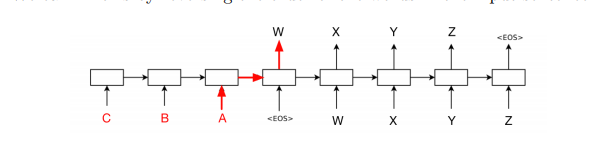
之前正序输入的时候,整个句子输入后,才开始decode第一个输入的词,所以每一个词都有长距离的依赖。但是逆置输入之后,每次decode的时候只有1个时间步之差,然后用这个信息来处理句子后续的信息,减少了过长的依赖。
3、identity initialization
恒等函数identity function f(x)=x是不担心多次迭代的,如果计算接近恒等函数的话,就会相对比较稳定。identity RNN就是一种RNN模型,激活函数全都是relu,中间的recuurent weight初始化为恒等矩阵
4、LSTM
使用LSTM可以更好的记住长时间前的信息

5、weight regularization
就是正则化,在loss函数后面加L1或L2范数的惩罚