分类目录:《机器学习中的数学》总目录
相关文章:
· 病态
· 局部极小值
· 高原、鞍点和其他平坦区域
· 梯度消失和梯度爆炸
· 非精确梯度
· 局部和全局结构间的弱对应
多层神经网络通常存在像悬崖一样的斜率较大区域,如下图所示。这是由于几个较大的权重相乘导致的。遇到斜率极大的悬崖结构时,梯度更新会很大程度地改变参数值,通常会完全跳过这类悬崖结构。
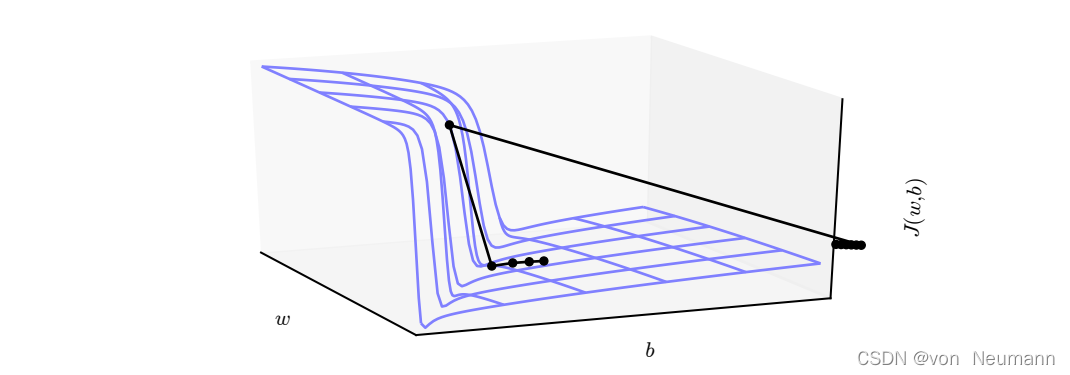
高度非线性的深度神经网络或循环神经网络的目标函数通常包含由几个参数连乘而导致的参数空间中尖锐非线性。这些非线性在某些区域会产生非常大的导数。当参数接近这样的悬崖区域时,梯度下降更新可以使参数弹射得非常远,可能会使大量已完成的优化工作成为无用功。
不管我们是从上还是从下接近悬崖,情况都很糟糕,但幸运的是,我们可以使用启发式梯度截断(Gradient Clipping)来避免其严重的后果。其基本想法源自梯度并没有指明最佳步长,只说明了在无限小区域内的最佳方向。当传统的梯度下降算法提议更新很大一步时,启发式梯度截断会干涉来减小步长,从而使其不太可能走出梯度近似为最陡下降方向的悬崖区域。悬崖结构在循环神经网络的代价函数中很常见,因为这类模型会涉及多个因子的相乘,其中每个因子对应一个时间步。因此,长期时间序列会产生大量相乘。
深度依赖导致的问题
当计算图变得极深时,神经网络优化算法会面临的另一个难题就是长期依赖问题——由于变深的结构使模型丧失了学习到先前信息的能力,让优化变得极其困难。深层的计算图不仅存在于前馈网络,还存在于循环网络中。因为循环网络要在很长时间序列的各个时刻重复应用相同操作来构建非常深的计算图,并且模型参数共享,这使问题更加凸显。例如,假设某个计算图中包含一条反复与矩阵 W W W相乘的路径。那么 t t t步后,相当于乘以 W t W^t Wt。假设 W W W有特征值分解 W = V diag ( λ ) V − 1 W=V\text{diag}(\lambda)V^{-1} W=Vdiag(λ)V−1。在这种简单的情况下,很容易看出:
w t = ( V diag ( λ ) V − 1 ) t = V diag ( λ ) t V − 1 w^t=(V\text{diag}(\lambda)V^{-1})^t=V\text{diag}(\lambda)^tV^{-1} wt=(Vdiag(λ)V−1)t=Vdiag(λ)tV−1
当特征值 λ \lambda λ不在1附近时,若在量级上大于1则会爆炸;若小于1时则会消失。梯度消失与爆炸问题(Vanishing and Exploding Gradient Problem)是指该计算图上的梯度也会因为 diag ( λ ) t \text{diag}(\lambda)^t diag(λ)t大幅度变化。梯度消失使得我们难以知道参数朝哪个方向移动能够改进代价函数,而梯度爆炸会使得学习不稳定。之前描述的促使我们使用梯度截断的悬崖结构便是梯度爆炸现象的一个例子。
此处描述的在各时间步重复与 W W W相乘非常类似于寻求矩阵 W W W的最大特征值及对应特征向量的幂方法。从这个观点来看, x T w t x^Tw^t xTwt最终会丢弃 x x x中所有与 W W W的主特征向量正交的成分。循环网络在各时间步上使用相同的矩阵 W W W,而前馈网络并没有。所以即使使用非常深层的前馈网络,也能很大程度上有效地避免梯度消失与爆炸问题。