目录
2.4 选择relu等梯度大部分落在常数上的激活函数(适用梯度消失/爆炸)

1. 产生原因
1.1 概念
梯度消失:梯度趋近于零,网络权重无法更新或更新的很微小,网络训练再久也不会有效果;
梯度爆炸:梯度呈指数级增长,变的非常大,然后导致网络权重的大幅更新,使网络变得不稳定
1.2 产生原因
梯度消失还是梯度爆炸本质上都是由于——深度神经网络的反向传播造成的
反向传播链式传导,链式法则是一个连乘的形式,所以当层数越深的时候,梯度将以指数形式传播。在反向传播过程中需要对激活函数进行求导,如果导数大于1,那么随着网络层数的增加梯度更新将会朝着指数爆炸的方式增加就是梯度爆炸。同样如果导数小于1,那么随着网络层数的增加梯度更新信息会朝着指数衰减的方式减少就是梯度消失。
网络过深,不合适的激活函数,较大/小的初始化权重
2. 解决方案
2.1 预训练(适用梯度消失/爆炸)
采取无监督逐层训练方法,其基本思想是每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,此过程就是逐层“预训练”(pre-training);在预训练完成后,再对整个网络进行“微调”(fine-tunning)。此思想相当于是先寻找局部最优,然后整合起来寻找全局最优
2.2 梯度剪切:对梯度设定阈值 (适用梯度爆炸)
设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。
2.3 权重正则化(适用梯度爆炸)
比较常见的是L1正则,和L2正则,正则化是通过对网络权重做正则,防止w过大,限制过拟合,正则项在损失函数的形式为:
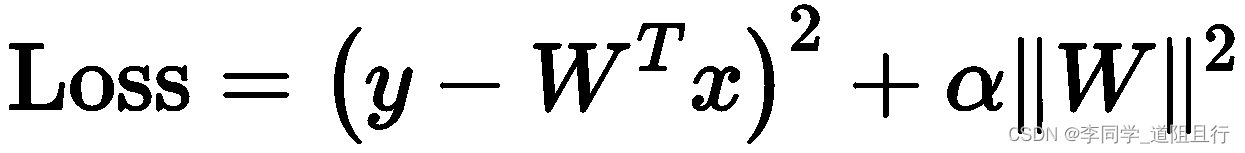
α为超参数,是正则项系数。通过公式可知,W越大,传到上一层的梯度就越大,连乘之后,就容易发生梯度爆炸,因此,对W做正则化就是约束W的取值,可以部分限制梯度爆炸的发生。除了对W做正则化,在初始权重的时候可以加上标准化,使W符合均值为0,标准差为1的高斯分布,也能限制部分梯度爆炸的发生。
2.4 选择relu等梯度大部分落在常数上的激活函数(适用梯度消失/爆炸)
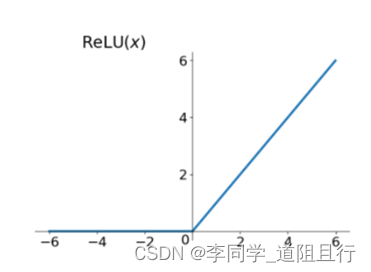
relu函数
relu函数的导数在正数部分是恒等于1的,因此在深层网络中使用relu激活函数就不会导致梯度消失和爆炸的问题。
relu的主要贡献在于:解决了梯度消失、爆炸的问题;计算方便,计算速度快;加速了网络的训练。缺点:由于负数部分恒为0,会导致一些神经元无法激活(可通过设置小学习率部分解决);输出不是以0为中心的。
LeakRelu
LeakRelu就是为了解决Relu的0区间带来的影响,其数学表达为: LeakRelu=max(k∗x,x),其中k是leak系数,一般选择0.01或者0.02,或者通过学习而来。

2.5 批归一化 (适用梯度消失/爆炸)
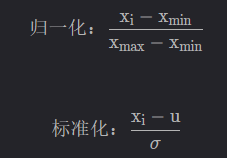
归一化就是要把需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内。首先归一化是为了后面数据处理的方便,其次是保证程序运行时收敛加快。归一化的具体作用是归纳统一样本的统计分布性。归一化在0 - 1之间是统计的概率分布,归一化在某个区间上是统计的坐标分布。
标准化和归一化本质上都是不改变数据顺序的情况下对数据的线性变化,而它们最大的不同是归一化(Normalization)会将原始数据规定在一个范围区间中,而标准化(Standardization)则是将数据调整为标准差为1,均值为0对分布。
另外归一化只与数据的最大值和最小值有关,缩放比例为 = Xmas - Xmin,而标准化的缩放比例等于标准差,平移量等于均值 ,当除了极大值极小值的数据改变时他的缩放比例和平移量也会改变。
BN,即批规范化,通过规范化操作将输出信号x规范化到均值为0,方差为1保证网络的稳定性
更新权重的梯度和上一层的输出X有关,如果输出过大或过小,就会导致产生梯度爆炸和梯度消失,BatchNorm通过对每一层的输出规范为均值和方差一致的方法,消除了X带来的放大缩小的影响,进而解决梯度消失和爆炸的问题。
2.6 残差结构 (适用梯度消失)

残差中有很多这样的跨层连接结构,其实就是在前向传播的过程中,输出端的值加上输入X再传到下一层网络结构中,这样的结构在反向传播中具有很大的好处。
因为旁边的分支结构是直接传递过来的,没有带权重,因此反向传播时该分支的梯度始终为1,这样即使主干梯度值很小,加上分支的梯度再传给上一层网络时,梯度也不会很小,从而很大程度上缓解了梯度消失。所以利用残差结构,可以轻松的构建几百层网络结构,而不用担心梯度消失过快的问题。