梯度消失和梯度爆炸:
梯度消失和梯度爆炸可以从同一个角度来解释, 根本原因是神经网络是根据链式求导法, 根据损失函数指导神经元之间的权重经行更新, 神经元的输入在经过激活函数激活, 通常, 如果我们选择sigmoid为激活函数:
通常,若使用的激活函数为sigmoid函数,其导数为:
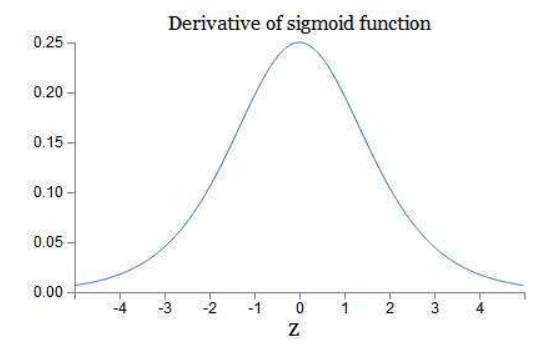
这样可以看到,如果我们使用标准化初始w,那么各个层次的相乘都是0-1之间的小数,而激活函数f的导数也是0-1之间的数,其连乘后,结果会变的很小,导致梯度消失。若我们初始化的w是很大的数,w大到乘以激活函数的导数都大于1,那么连乘后,可能会导致求导的结果很大,形成梯度爆炸。
如何解决?
-
- 更换激活函数,如Relu, Tanh, 但Tanh的导数也是小于1的, 也有可能发生梯度消失/爆炸
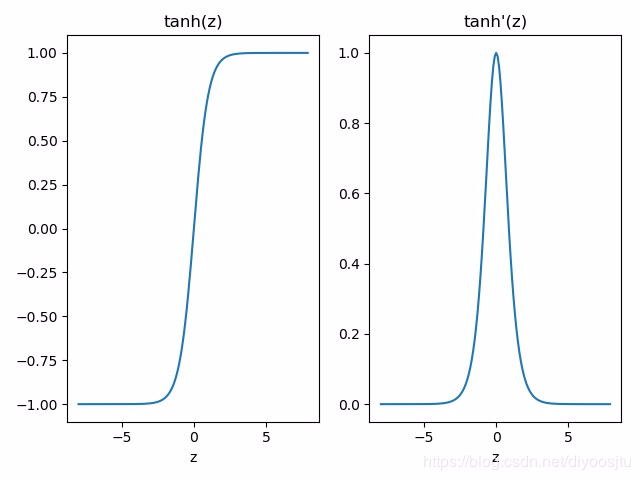

- 更换激活函数,如Relu, Tanh, 但Tanh的导数也是小于1的, 也有可能发生梯度消失/爆炸
由上图可知,ReLU函数的导数,在正值部分恒为1,因此不会导致梯度消失或梯度爆炸问题。
另外ReLU函数还有一些优点:
计算方便,计算速度快
解决了梯度消失问题,收敛速度快
-
- 参数阶段, 将w截取到一个范围内, wgan就是这样做的
-
- 残差连接
-
- BN
-
- 正则化,惩罚参数项目
https://blog.csdn.net/weixin_39853245/article/details/90085307