一、前言
商汤和港中文联合开源了 mmdetection—基于 PyTorch 的开源目标检测工具包。
工具包支持 Mask RCNN 等多种流行的检测框架,读者可在 PyTorch 环境下测试不同的预训练模型及训练新的检测分割模型。
项目地址:https://github.com/open-mmlab/mmdetection
mmdetection 目标检测工具包
mmdetection 的主要特征可以总结为以下几个方面:
- 模块化设计:你可以通过连接不同组件轻松构建自定义目标检测框架。
- 支持多个框架,开箱即用:该工具包直接支持多种流行的检测框架,如 Faster RCNN、Mask RCNN、RetinaNet 等。
- 高效:所有基础边界框和掩码运算都在 GPU 上运行。不同模型的训练速度大约比 FAIR 的 Detectron 快 5% ~ 20%。
- 当前最优:这是 MMDet 团队的代码库,该团队赢得了 2018 COCO 检测挑战赛的冠军。
open-mmlab 项目
├─── mmcv 计算机视觉基础库
| ├── deep learning framework 工具函数(IO/Image/Video )
| └── PyTorch 训练工具
└─── mmdetection
其实 mmdetection 很多算法的实现都依赖于 mmcv 库。
第一个版本中实现了 RPN、Fast R-CNN、Faster R-CNN、Mask R-CNN,近期还计划放出 RetinaNet 和 Cascade R-CNN。
先简单与 Detectron 的对比
- performance 稍高
- 训练速度稍快
- 所需显存稍小
performance:由于 PyTorch 官方 model zoo 里面的 ResNet 结构和 Detectron 所用的 ResNet 有细微差别(mmdetection 中可以通过 backbone 的 style 参数指定),导致模型收敛速度不一样,所以我们用两种结构都跑了实验,一般来说在 1x 的 lr schedule 下 Detectron 的会高,但 2x 的结果 PyTorch 的结构会比较高。
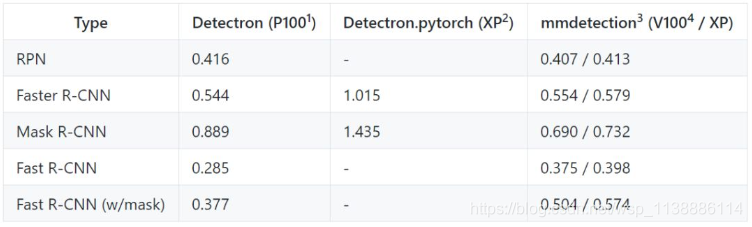
速度方面 :Mask R-CNN 差距比较大,其余的很小。采用相同的 setting,Detectron 每个 iteration 需要 0.89s,而 mmdetection 只需要 0.69s。Fast R-CNN 比较例外,比 Detectron 的速度稍慢。另外在我们的服务器上跑 Detectron 会比官方 report 的速度慢 20% 左右,猜测是 FB 的 Big Basin 服务器性能比我们好?
显存方面优势比较明显:会小 30% 左右。但这个和框架有关,不完全是 codebase 优化的功劳。一个让我们比较意外的结果是现在的 codebase 版本跑 ResNet-50 的 Mask R-CNN,每张卡(12 G)可以放 4 张图,比我们比赛时候小了不少。
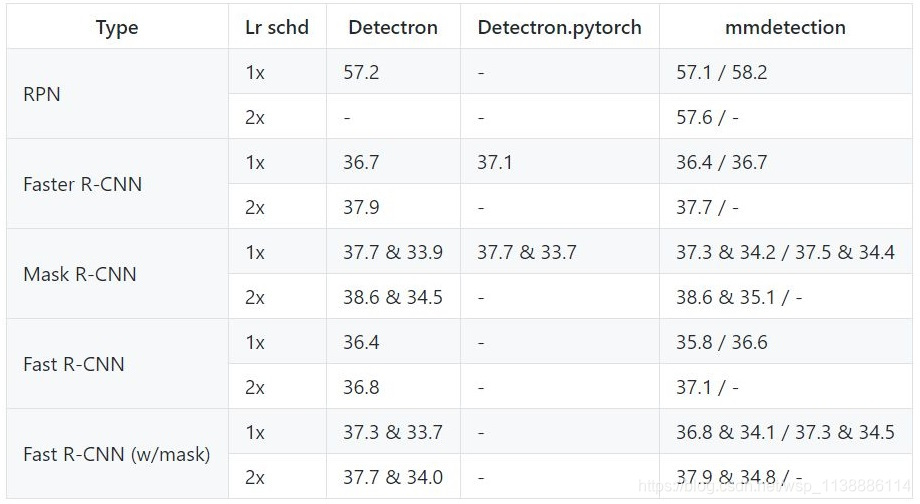
- 性能
开发者报告了使用使用 caffe-style 和 pytorch-style ResNet 骨干网络的结果,前者的权重来自 Detectron 中 MODEL ZOO 的预训练模型,后者的权重来自官方 model zoo。
- 训练速度
训练速度的单位是 s/iter,数值越低代表速度越高
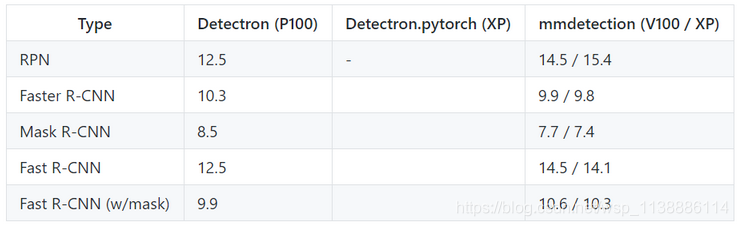
3. 推断测试
推断速度的单位是 fps (img/s),数值越高代表效果越好。
二、测试与训练
mmdetection 需要以下环境
Linux (tested on Ubuntu 16.04 and CentOS 7.2)
Python 3.4+
PyTorch 0.4.1 and torchvision
Cython
mmcv
windows环境下 Anaconda | python==3.6.6 直接安装
测试和保存运行示例
测试和保存结果:python tools/test.py <CONFIG_FILE> <CHECKPOINT_FILE> --gpus <GPU_NUM> --out <OUT_FILE>
要想执行测试后的评估,你需要添加 --eval <EVAL_TYPES>。支持类型包括:
proposal_fast:使用 mmdetection 的代码求 proposal 的召回率。
proposal: 使用 COCO 提供的官方代码求 proposal 的召回率。
bbox: 使用 COCO 提供的官方代码求 box AP 值。
segm: 使用 COCO 提供的官方代码求 mask AP 值。
keypoints:使用 COCO 提供的官方代码求 keypoint AP 值。
例如,估计使用 8 个 GPU 的 Mask R-CNN,并将结果保存为 results.pkl:
python tools/test.py configs/mask_rcnn_r50_fpn_1x.py \
<CHECKPOINT_FILE> --gpus 8 --out results.pkl --eval bbox segm
在测试过程中可视化结果同样很方便,只需添加一个参数 --show:
python tools/test.py <CONFIG_FILE> <CHECKPOINT_FILE> --show
测试图像
import mmcv
from mmcv.runner import load_checkpoint
from mmdet.models import build_detector
from mmdet.apis import inference_detector, show_result
# 导入模型参数
cfg = mmcv.Config.fromfile('configs/faster_rcnn_r50_fpn_1x.py')
cfg.model.pretrained = None
# 构建化模型和加载检查点卡
model = build_detector(cfg.model, test_cfg=cfg.test_cfg)
_ = load_checkpoint(model, 'https://s3.ap-northeast-2.amazonaws.com/open-mmlab/mmdetection\
/models/faster_rcnn_r50_fpn_1x_20181010-3d1b3351.pth')
# 测试单张图片
img = mmcv.imread('test.jpg')
result = inference_detector(model, img, cfg)
show_result(img, result)
# 测试(多张)图片列表
imgs = ['test1.jpg', 'test2.jpg']
for i, result in enumerate(inference_detector(model, imgs, cfg, device='cuda:0')):
print(i, imgs[i])
show_result(imgs[i], result)
训练模型
mmdetection 使用 MMDistributedDataParallel 和 MMDataParallel 分别实现分布式训练和非分布式训练。
开发者建议在单个机器上也要使用分布式训练,因为它速度更快,而非分布式训练可以用于 debug 或其他目的。
- 分布式训练
mmdetection 潜在支持多种 launch 方法,如 PyTorch 的内置 launch utility、 slurm 和 MPI。
开发者使用 PyTorch 内置的 launch utility 提供训练脚本:
./tools/dist_train.sh <CONFIG_FILE> <GPU_NUM> [optional arguments]
支持的参数有:
--validate:训练过程中每 k(默认值为 1)个 epoch 执行估计。
--work_dir <WORK_DIR>:如果指定,配置文件中的路径将被重写。 - 非分布式训练
python tools/train.py <CONFIG_FILE> --gpus <GPU_NUM> --work_dir <WORK_DIR> --validate