计算机视觉系列-轻松掌握 MMDetection 中 全景分割算法 MaskFormer(一)
全景分割 简介
论文链接:
https://arxiv.org/abs/1801.00868

全景分割 :论文提出并研究了一种称为全景分割的任务。全景分割结合了典型的不同任务:语义分割(为每个像素分配一个类标签)和实例分割(检测和分割每个对象实例)。提出的任务需要生成一个连贯的场景分割,丰富和完整,这是走向现实世界的视觉系统的重要一步。虽然计算机视觉的早期工作解决了相关的图像/场景解析任务,但这些目前并不流行,可能是由于缺乏适当的指标或相关的识别挑战。为了解决这个问题,论文提出了一个新的全局质量(PQ)指标,它以一种可解释的和统一的方式捕捉所有类(东西)的性能。使用提出的指标,论文在三个现有的数据集上对全景分割的人和机器性能进行了严格的研究,揭示了关于任务的有趣见解。论文工作的目的是重新唤起社会对图像分割更统一观点的兴趣。




- 语义分割: 图像中每个像素分配一个语义标签
- 实例分割:将图像中每个实例都分割出来,允许实例之间有重叠。
- 全景分割:包括语义分割和实例分割, 区分单个对象实例; 实例之间不重叠。全景分割 对图像中每个像素点分配一个语义标签和一个实例编号。
MaskFormer 简介
MaskFormer 论文链接:
https://arxiv.org/abs/2107.06278


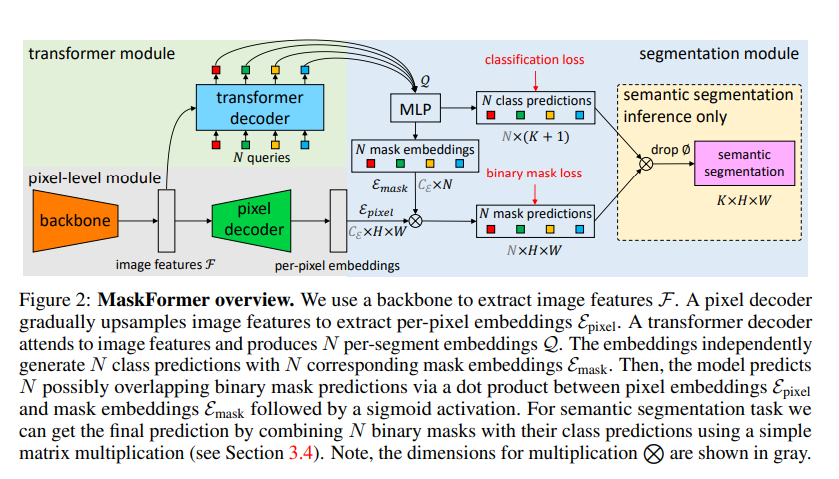

逐像素分类并不是语义分割所需要的全部:
现代方法通常将语义分割制定为逐像素分类任务,而实例级分割则使用替代掩码分类进行处理。我们的关键见解:掩码分类足够通用,可以使用完全相同的模型、损失和训练过程以统一的方式解决语义和实例级别的分割任务。根据这一观察,我们提出了 MaskFormer,这是一个简单的掩码分类模型,它预测一组二进制掩码,每个掩码与单个全局类标签预测相关联。总体而言,所提出的基于掩码分类的方法简化了语义和全景分割任务的有效方法的前景,并显示了出色的实证结果。尤其是,我们观察到当类的数量很大时,MaskFormer 优于每像素分类基线。我们基于掩码分类的方法优于当前最先进的语义(ADE20K 上为 55.6 mIoU)和全景分割(COCO 上为 52.7 PQ)模型。
github代码:
https://github.com/facebookresearch/MaskFormer
MaskFormer 配置代码
- MMDetection 复现代码:
https://github.com/open-mmlab/mmdetection/tree/master/configs/maskformer - maskformer配置文件
mmdetection-2.25.0/configs/maskformer/maskformer_r50_mstrain_16x1_75e_coco.py
_base_ = [
'../_base_/datasets/coco_panoptic.py', '../_base_/default_runtime.py'
]
num_things_classes = 80
num_stuff_classes = 53
num_classes = num_things_classes + num_stuff_classes
model = dict(
type='MaskFormer',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=-1,
norm_cfg=dict(type='BN', requires_grad=False),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
panoptic_head=dict(
type='MaskFormerHead',
in_channels=[256, 512, 1024, 2048], # pass to pixel_decoder inside
feat_channels=256,
out_channels=256,
num_things_classes=num_things_classes,
num_stuff_classes=num_stuff_classes,
num_queries=100,
pixel_decoder=dict(
type='TransformerEncoderPixelDecoder',
norm_cfg=dict(type='GN', num_groups=32),
act_cfg=dict(type='ReLU'),
encoder=dict(
type='DetrTransformerEncoder',
num_layers=6,
transformerlayers=dict(
type='BaseTransformerLayer',
attn_cfgs=dict(
type='MultiheadAttention',
embed_dims=256,
num_heads=8,
attn_drop=0.1,
proj_drop=0.1,
dropout_layer=None,
batch_first=False),
ffn_cfgs=dict(
embed_dims=256,
feedforward_channels=2048,
num_fcs=2,
act_cfg=dict(type='ReLU', inplace=True),
ffn_drop=0.1,
dropout_layer=None,
add_identity=True),
operation_order=('self_attn', 'norm', 'ffn', 'norm'),
norm_cfg=dict(type='LN'),
init_cfg=None,
batch_first=False),
init_cfg=None),
positional_encoding=dict(
type='SinePositionalEncoding', num_feats=128, normalize=True)),
enforce_decoder_input_project=False,
positional_encoding=dict(
type='SinePositionalEncoding', num_feats=128, normalize=True),
transformer_decoder=dict(
type='DetrTransformerDecoder',
return_intermediate=True,
num_layers=6,
transformerlayers=dict(
type='DetrTransformerDecoderLayer',
attn_cfgs=dict(
type='MultiheadAttention',
embed_dims=256,
num_heads=8,
attn_drop=0.1,
proj_drop=0.1,
dropout_layer=None,
batch_first=False),
ffn_cfgs=dict(
embed_dims=256,
feedforward_channels=2048,
num_fcs=2,
act_cfg=dict(type='ReLU', inplace=True),
ffn_drop=0.1,
dropout_layer=None,
add_identity=True),
# the following parameter was not used,
# just make current api happy
feedforward_channels=2048,
operation_order=('self_attn', 'norm', 'cross_attn', 'norm',
'ffn', 'norm')),
init_cfg=None),
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0,
reduction='mean',
class_weight=[1.0] * num_classes + [0.1]),
loss_mask=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
reduction='mean',
loss_weight=20.0),
loss_dice=dict(
type='DiceLoss',
use_sigmoid=True,
activate=True,
reduction='mean',
naive_dice=True,
eps=1.0,
loss_weight=1.0)),
panoptic_fusion_head=dict(
type='MaskFormerFusionHead',
num_things_classes=num_things_classes,
num_stuff_classes=num_stuff_classes,
loss_panoptic=None,
init_cfg=None),
train_cfg=dict(
assigner=dict(
type='MaskHungarianAssigner',
cls_cost=dict(type='ClassificationCost', weight=1.0),
mask_cost=dict(
type='FocalLossCost', weight=20.0, binary_input=True),
dice_cost=dict(
type='DiceCost', weight=1.0, pred_act=True, eps=1.0)),
sampler=dict(type='MaskPseudoSampler')),
test_cfg=dict(
panoptic_on=True,
# For now, the dataset does not support
# evaluating semantic segmentation metric.
semantic_on=False,
instance_on=False,
# max_per_image is for instance segmentation.
max_per_image=100,
object_mask_thr=0.8,
iou_thr=0.8,
# In MaskFormer's panoptic postprocessing,
# it will not filter masks whose score is smaller than 0.5 .
filter_low_score=False),
init_cfg=None)
# dataset settings
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='LoadPanopticAnnotations',
with_bbox=True,
with_mask=True,
with_seg=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='AutoAugment',
policies=[[
dict(
type='Resize',
img_scale=[(480, 1333), (512, 1333), (544, 1333), (576, 1333),
(608, 1333), (640, 1333), (672, 1333), (704, 1333),
(736, 1333), (768, 1333), (800, 1333)],
multiscale_mode='value',
keep_ratio=True)
],
[
dict(
type='Resize',
img_scale=[(400, 1333), (500, 1333), (600, 1333)],
multiscale_mode='value',
keep_ratio=True),
dict(
type='RandomCrop',
crop_type='absolute_range',
crop_size=(384, 600),
allow_negative_crop=True),
dict(
type='Resize',
img_scale=[(480, 1333), (512, 1333), (544, 1333),
(576, 1333), (608, 1333), (640, 1333),
(672, 1333), (704, 1333), (736, 1333),
(768, 1333), (800, 1333)],
multiscale_mode='value',
override=True,
keep_ratio=True)
]]),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=1),
dict(type='DefaultFormatBundle'),
dict(
type='Collect',
keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks', 'gt_semantic_seg']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=1),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=1,
workers_per_gpu=1,
train=dict(pipeline=train_pipeline),
val=dict(pipeline=test_pipeline),
test=dict(pipeline=test_pipeline))
# optimizer
optimizer = dict(
type='AdamW',
lr=0.0001,
weight_decay=0.0001,
eps=1e-8,
betas=(0.9, 0.999),
paramwise_cfg=dict(
custom_keys={
'backbone': dict(lr_mult=0.1, decay_mult=1.0),
'query_embed': dict(lr_mult=1.0, decay_mult=0.0)
},
norm_decay_mult=0.0))
optimizer_config = dict(grad_clip=dict(max_norm=0.01, norm_type=2))
# learning policy
lr_config = dict(
policy='step',
gamma=0.1,
by_epoch=True,
step=[50],
warmup='linear',
warmup_by_epoch=False,
warmup_ratio=1.0, # no warmup
warmup_iters=10)
runner = dict(type='EpochBasedRunner', max_epochs=75)
- 配置文件 mmdetection-2.25.0/configs/maskformer/maskformer_swin-l-p4-w12_mstrain_64x1_300e_coco.py 主干网络采用SwinTransformer
_base_ = './maskformer_r50_mstrain_16x1_75e_coco.py'
pretrained = 'https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window12_384_22k.pth' # noqa
depths = [2, 2, 18, 2]
model = dict(
backbone=dict(
_delete_=True,
type='SwinTransformer',
pretrain_img_size=384,
embed_dims=192,
patch_size=4,
window_size=12,
mlp_ratio=4,
depths=depths,
num_heads=[6, 12, 24, 48],
qkv_bias=True,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.3,
patch_norm=True,
out_indices=(0, 1, 2, 3),
with_cp=False,
convert_weights=True,
init_cfg=dict(type='Pretrained', checkpoint=pretrained)),
panoptic_head=dict(
in_channels=[192, 384, 768, 1536], # pass to pixel_decoder inside
pixel_decoder=dict(
_delete_=True,
type='PixelDecoder',
norm_cfg=dict(type='GN', num_groups=32),
act_cfg=dict(type='ReLU')),
enforce_decoder_input_project=True))
# weight_decay = 0.01
# norm_weight_decay = 0.0
# embed_weight_decay = 0.0
embed_multi = dict(lr_mult=1.0, decay_mult=0.0)
norm_multi = dict(lr_mult=1.0, decay_mult=0.0)
custom_keys = {
'norm': norm_multi,
'absolute_pos_embed': embed_multi,
'relative_position_bias_table': embed_multi,
'query_embed': embed_multi
}
# optimizer
optimizer = dict(
type='AdamW',
lr=6e-5,
weight_decay=0.01,
eps=1e-8,
betas=(0.9, 0.999),
paramwise_cfg=dict(custom_keys=custom_keys, norm_decay_mult=0.0))
optimizer_config = dict(grad_clip=dict(max_norm=0.01, norm_type=2))
# learning policy
lr_config = dict(
policy='step',
gamma=0.1,
by_epoch=True,
step=[250],
warmup='linear',
warmup_by_epoch=False,
warmup_ratio=1e-6,
warmup_iters=1500)
runner = dict(type='EpochBasedRunner', max_epochs=300)
- 元文件 metafile.yml
Collections:
- Name: MaskFormer
Metadata:
Training Data: COCO
Training Techniques:
- AdamW
- Weight Decay
Training Resources: 16x V100 GPUs
Architecture:
- MaskFormer
Paper:
URL: https://arxiv.org/pdf/2107.06278
Title: 'Per-Pixel Classification is Not All You Need for Semantic Segmentation'
README: configs/maskformer/README.md
Code:
URL: https://github.com/open-mmlab/mmdetection/blob/v2.22.0/mmdet/models/detectors/maskformer.py#L7
Version: v2.22.0
Models:
- Name: maskformer_r50_mstrain_16x1_75e_coco
In Collection: MaskFormer
Config: configs/maskformer/maskformer_r50_mstrain_16x1_75e_coco.py
Metadata:
Training Memory (GB): 16.2
Epochs: 75
Results:
- Task: Panoptic Segmentation
Dataset: COCO
Metrics:
PQ: 46.9
Weights: https://download.openmmlab.com/mmdetection/v2.0/maskformer/maskformer_r50_mstrain_16x1_75e_coco/maskformer_r50_mstrain_16x1_75e_coco_20220221_141956-bc2699cb.pth
- Name: maskformer_swin-l-p4-w12_mstrain_64x1_300e_coco
In Collection: MaskFormer
Config: configs/maskformer/maskformer_swin-l-p4-w12_mstrain_64x1_300e_coco.py
Metadata:
Training Memory (GB): 27.2
Epochs: 300
Results:
- Task: Panoptic Segmentation
Dataset: COCO
Metrics:
PQ: 53.2
Weights: https://download.openmmlab.com/mmdetection/v2.0/maskformer/maskformer_swin-l-p4-w12_mstrain_64x1_300e_coco/maskformer_swin-l-p4-w12_mstrain_64x1_300e_coco_20220326_221612-061b4eb8.pth
以上部分学习笔记素材来源自 openmmlab,部分图文来源网络。
计算机视觉学习笔记系列
- 业界前沿技术:从零开始学视觉Transformer-学习笔记
- 业界前沿技术:从零开始学视觉Transformer-Data-Efficient Image Transformers
- MMDetection 整体构建流程-学习笔记一
- MMDetection 整体构建流程-学习笔记二
- MMDetection 整体构建流程-学习笔记三
- MMDetection 整体构建流程-学习笔记四
- MMDetection 整体构建流程-学习笔记五
- 业界前沿技术:从零开始学视觉Transformer-Swin Transformer-1
- 计算机视觉系列-轻松掌握 MMDetection 中 Head 流程-学习笔记 一
- 计算机视觉系列-轻松掌握 MMDetection 中 Head 流程-学习笔记 二
- 计算机视觉系列-轻松掌握 MMDetection 中 Head 流程-学习笔记 三
- 计算机视觉系列-MMCV 配置组件分析: Config
- 计算机视觉系列-MMCV 注册组件分析: Registry
- 计算机视觉系列-MMCV 组件分析: Hook
- 计算机视觉系列-MMCV 组件分析: Runner
- 计算机视觉系列-轻松掌握 MMDetection 中常用算法 :RetinaNet(一)
- 计算机视觉系列-轻松掌握 MMDetection 中常用算法 :RetinaNet(二)
- 计算机视觉系列-轻松掌握 MMDetection 中常用算法 :RetinaNet(三)
- 计算机视觉系列-轻松掌握 MMDetection 中常用算法 :RetinaNet(四)
- 计算机视觉系列-轻松掌握 MMDetection 中常用算法 :Faster R-CNN|Mask R-CNN(一)
- 计算机视觉系列-轻松掌握 MMDetection 中常用算法:Faster R-CNN|Mask R-CNN (二)
- 计算机视觉系列-轻松掌握 MMDetection 中常用算法:Faster R-CNN|Mask R-CNN (三)
- 计算机视觉系列-轻松掌握 MMDetection 中常用算法:Faster R-CNN|Mask R-CNN (四)
- 计算机视觉系列-轻松掌握 MMDetection 中常用算法:Faster R-CNN|Mask R-CNN (五)
- 计算机视觉系列-轻松掌握 MMDetection 中常用算法 :FCOS(一)
- 计算机视觉系列-轻松掌握 MMDetection 中常用算法 :FCOS(二)
- 计算机视觉系列-论文学习 INTERN: A New Learning Paradigm Towards General Vision
- 计算机视觉系列-轻松掌握 MMDetection 中常用算法 :FCOS (三)
- 计算机视觉系列-轻松掌握 MMDetection 中常用算法 :ATSS(一)
- 计算机视觉系列-轻松掌握 MMDetection 中常用算法 :ATSS(二)
- 计算机视觉系列-轻松掌握 MMDetection 中常用算法 :Cascade R-CNN(一)
- 计算机视觉系列-轻松掌握 MMDetection 中常用算法 :Cascade R-CNN(二)
- 计算机视觉系列-轻松掌握 MMDetection 中常用算法 :Cascade R-CNN(三)